Python爬虫|豆瓣网友评价告诉你《你好,李焕英》为什么这么火!
Posted 爬虫与地理信息
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫|豆瓣网友评价告诉你《你好,李焕英》为什么这么火!相关的知识,希望对你有一定的参考价值。
欢迎大家关注我的微信公众号!
名称:爬虫与地理信息

一、爬虫思路分析
点击划线处进入到短评页面,鼠标右击检查进入浏览器调试页面。
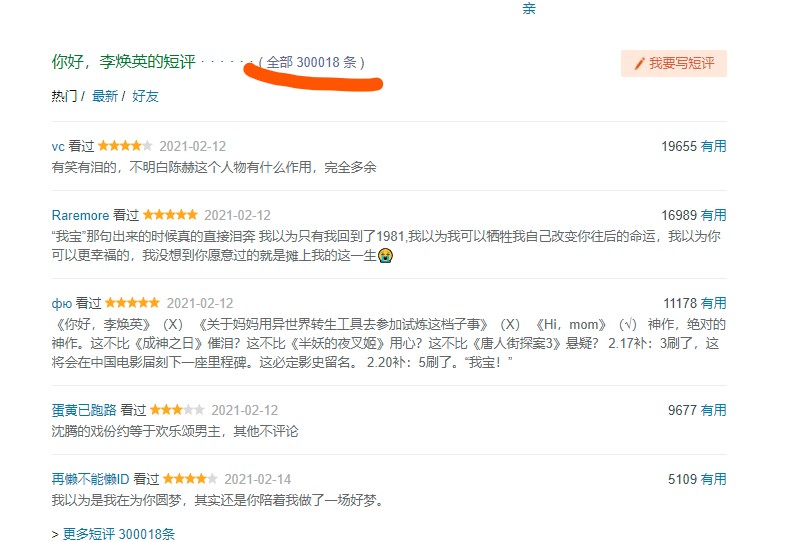
通过分析,每一条短评属于一个div标签,class名为comment-item,每一页显示固定数量的短评。
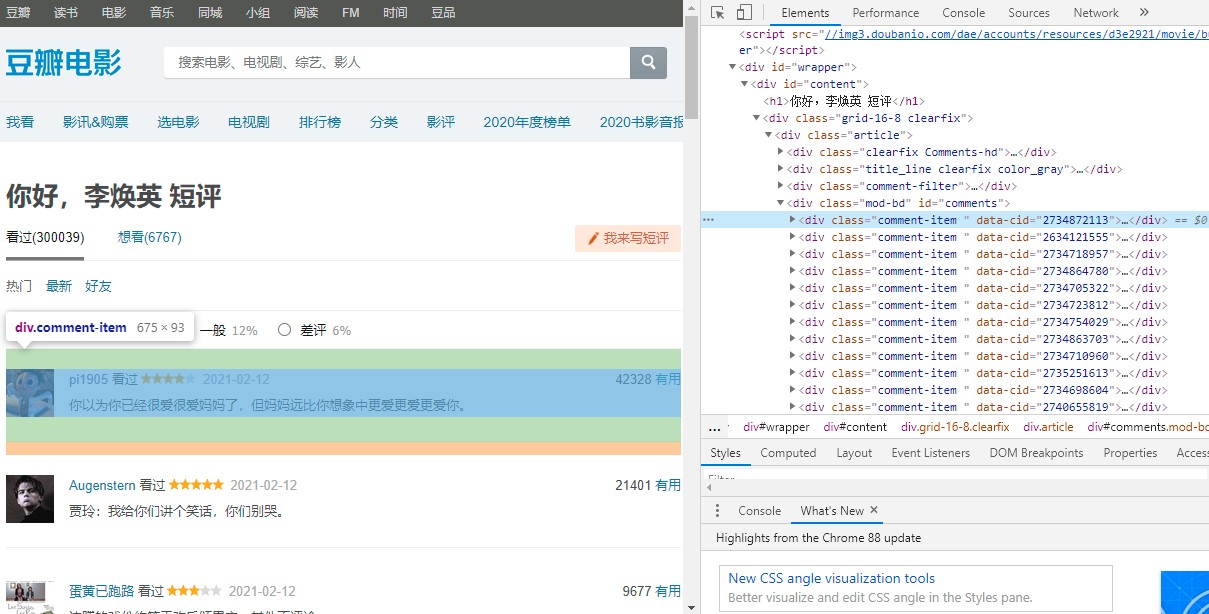
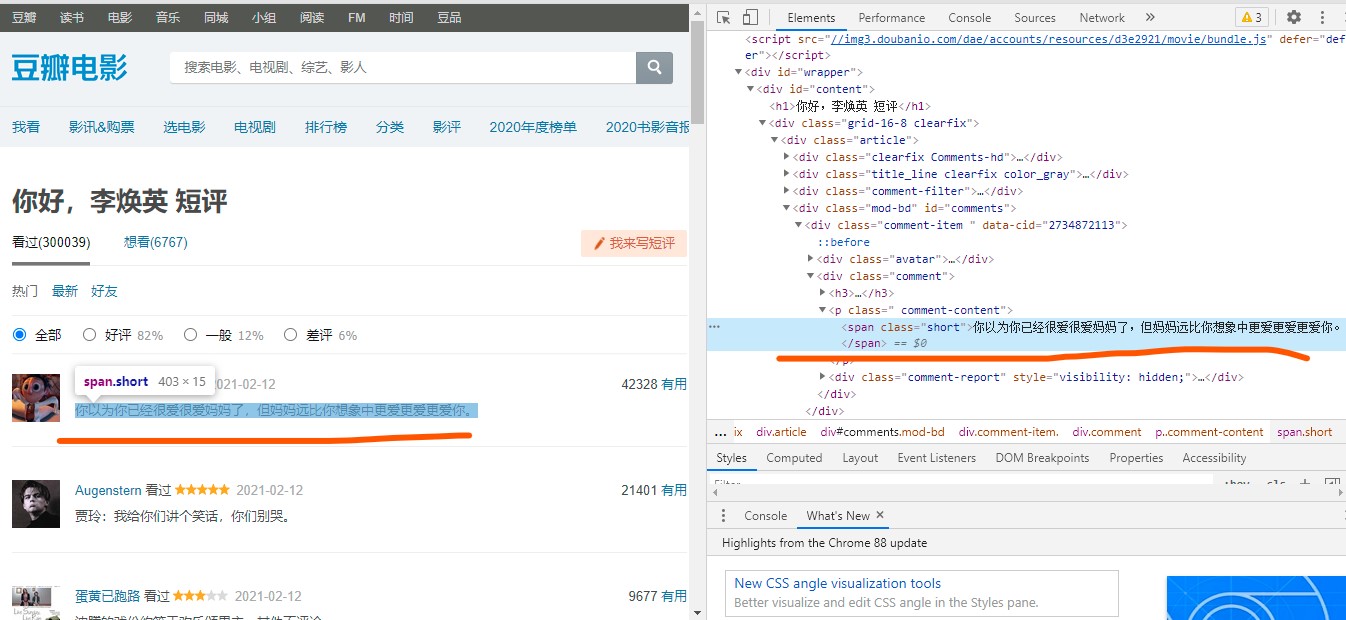
点开第一个,可以发现我们要找的评价语在一个标签中。通过点击下方的翻页,可以观察到每一页的url地址规律,发现只有一个参数start在变化,说明其为页面参数。照此规律,我们依次构造每一页的访问地址。
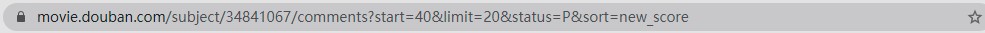

二、核心代码
1.获取网页内容
def gethtml(url):
user_agent = random.choice(USER_AGENTS)
headers =
'User-Agent': user_agent,
'Cookie':'你自己账号的Cookie'
try:
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
# content属性返回的类型是bytes
#html = response.content.decode('utf-8', errors='ignore')
# text属性类型为string
text = response.text
# print(text)
return text
except:
print("爬取失败!")
2.解析网页内容
def parse_page(text):
html = etree.HTML(text)
#获取短评列表
comments = html.xpath("//div[@class='comment']//span[@class='short']/text()")
return comments
3.爬取信息
def spider(page_nums):
print("爬虫开始......")
url = "https://movie.douban.com/subject/34841067/comments?start=&limit=20&status=P&sort=new_score"
#获取观看人数
html = etree.HTML(getHtml(url.format(0)))
visited_nums_str = html.xpath("//li[@class='is-active']/span/text()")
visited_nums = visited_nums_str[0].split('(')[1].split(')')[0]
print("观看人数:" + visited_nums)
comment_list = []
for i in range(1,page_nums+1):
if len(comment_list) < int(visited_nums):
full_url = url.format((i - 1) * 20)
# print(full_url)
print("爬取第 "+ str(i) +" 页")
tag = random.randint(1,3)
time.sleep(tag)
text = getHtml(full_url)
comments = parse_page(text)
for comment in comments:
#print(comment)
#print("******************************")
comment_list.append(comment)
# comment_list.append(comment.replace("\\n", ""))
print("爬虫结束!")
return comment_list
4.保存短评到文本文件
def save_file(comment_list):
print("开始写入文件......")
with open("./你好李焕英评论.txt", 'w', encoding='utf-8') as f:
for comment in comment_list:
#print(film_info)
comment_line = comment + "\\n"
f.write(comment_line)
#f.write("--------------------------------------------------------------------"+ "\\n")
print("写入文件完成!")
5.分词与词云图制作
if __name__ == '__main__':
start = time.time()
#comment_list = spider(10)
#save_file(comment_list)
filename = "你好李焕英评论.txt"
f = open(filename, mode='r', encoding='utf-8')
comments = f.readlines()
#保留用户自定义词语
jieba.load_userdict('dict.txt')
mytext = ''
for comment in comments:
mytext += ' '.join(jieba.cut(comment, cut_all=False))
# 设置词云形状
mask = np.array(Image.open("2.png"))
wordcloud = WordCloud(
mask = mask,
width=1000, #词云图片宽度,默认400像素
height=800, #词云图片高度 默认200像素
background_color='white', #词云图片的背景颜色,默认为黑色
scale= 5, #Scale 默认值1。值越大,图像密度越大越清晰
font_path='./fonts/simhei.ttf', #指定字体路径 默认None,对于中文可用font_path='msyh.ttc'
stopwords= '还是','故事','李焕英','不是','观众','导演','电影','贾玲','没有','时候','那个','自己','确实','但是','喜剧','就是',
'可以','什么','我们','觉得','最后','这个','如果','已经','以为','真的','一个' #不显示的单词
)
wordcloud.generate(mytext)
wordcloud.to_file('你好李焕英影评2.jpg')
end = time.time()
print('程序执行时间: %.2f' % (end - start))
三、结果展示
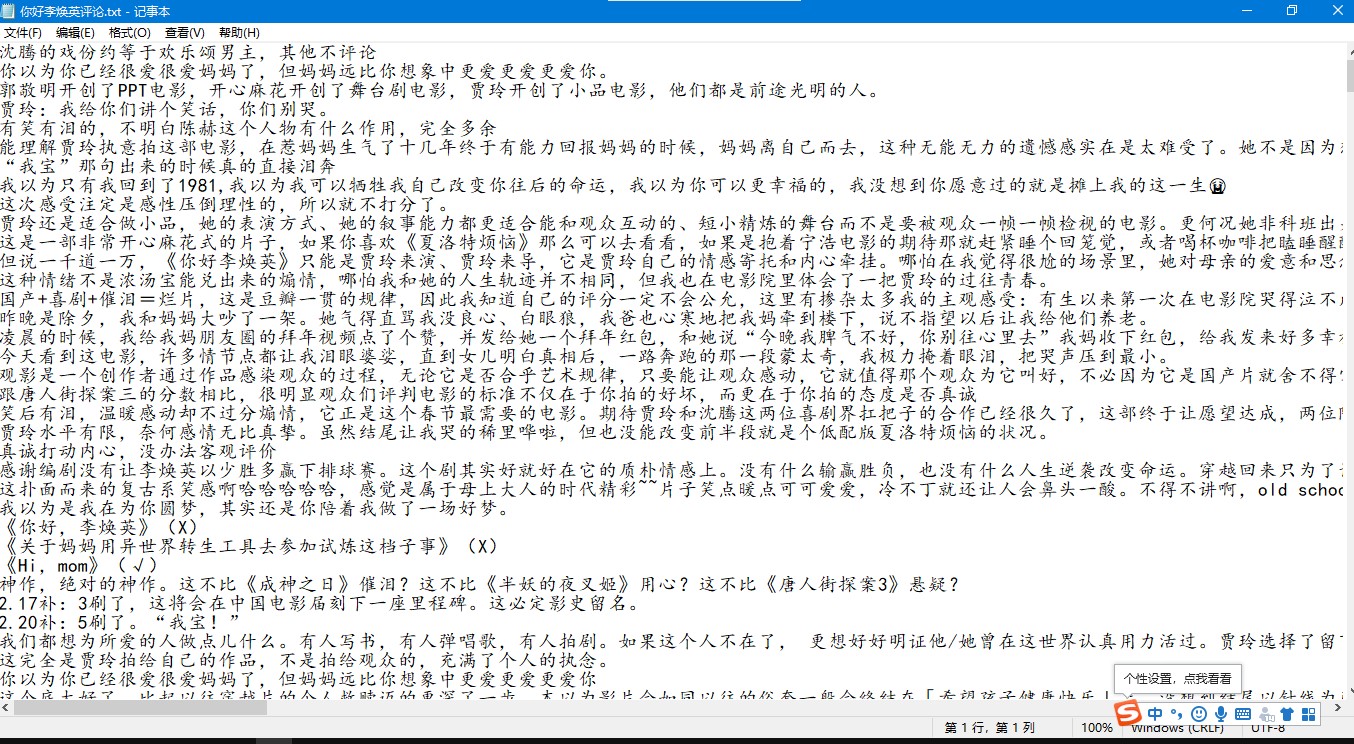
1.短评文件
最喜欢其中的一句短评:“你以为你已经很爱很爱妈妈了,但妈妈远比你想象中更爱更爱更爱你。”
2.词云图片
①.无背景词云

②.五角星形状词云

③.汉字形状词云
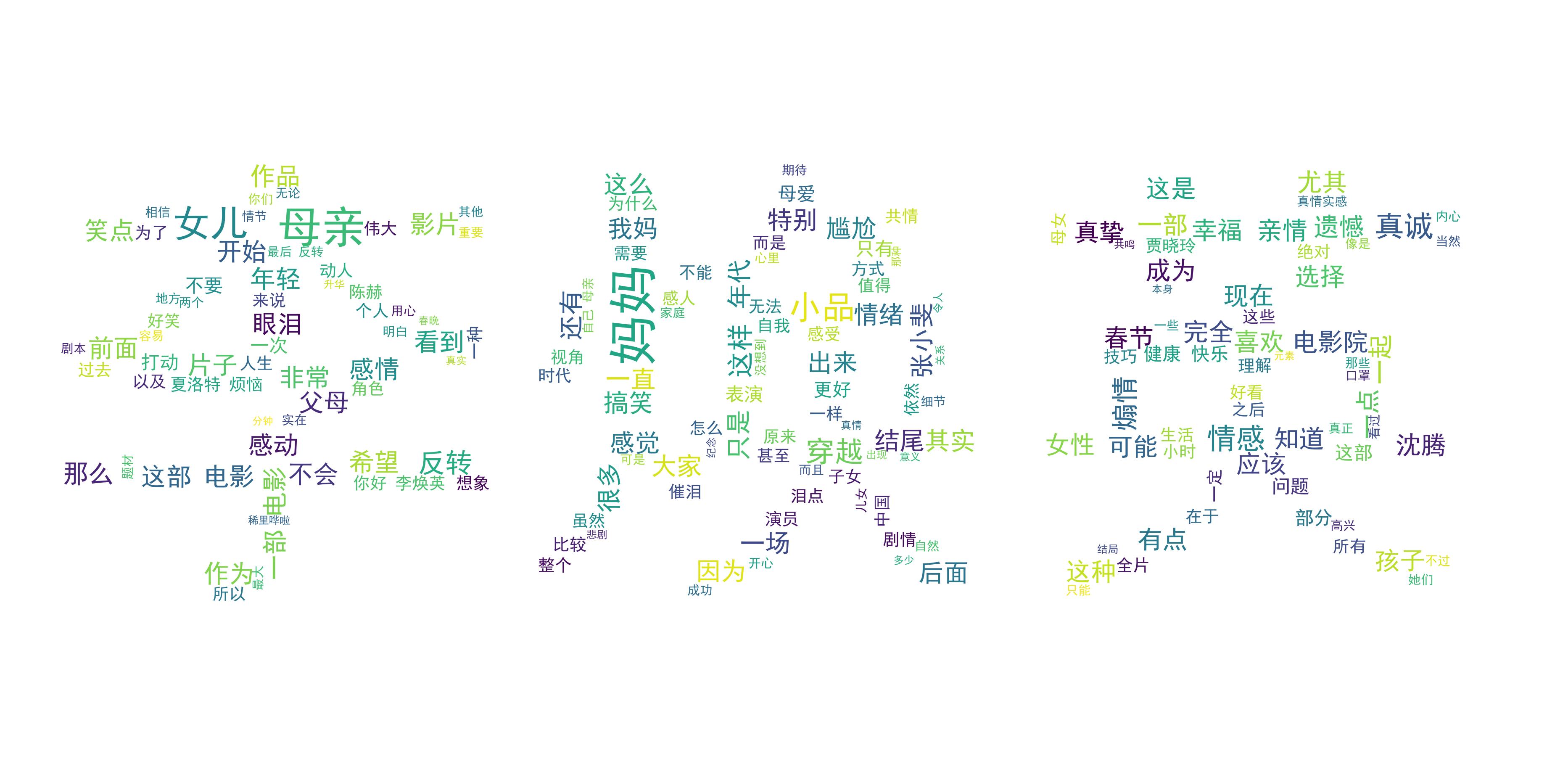
以上是关于Python爬虫|豆瓣网友评价告诉你《你好,李焕英》为什么这么火!的主要内容,如果未能解决你的问题,请参考以下文章