Python从0开始写爬虫——把扒到的豆瓣数据存储到数据库
Posted 莫问今朝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python从0开始写爬虫——把扒到的豆瓣数据存储到数据库相关的知识,希望对你有一定的参考价值。
1. 我们扒到了什么?
id, 名称, 上映年份,上映日期,所属类目, 导演,主演,片长,评分,星评,评价人数
2. 把这些数据做一个分类。
a..基本信息 :名称, 导演,上映年份, 所属类目, 片长
b.评价信息:评分,星评,评价人数
c.主演表: 主演(我在纠结要不要单独列一张表)
3 .表设计。现在有点蛋疼的是主键。用自增主键还是电影id做主键。经过我的多方面考虑,我慎重(草率)地决定,用电影id(反正都要建唯一索引,为什么不拿来当主键呢。。), 所以我刚才又在id那转了一下数据
m_id = re.search("[0-9]+", movie_url).group() movie["id"] = int(m_id)
写着玩嘛,就是那么随意,有什么想法就改!!!
4. 建表。。也是蛋疼,我居然纠结过是用mysql还是mongodb, 马上就删自己一个耳光,你会mongodb嘛?感觉要是继续又开一个mongodb的坑,我就再也回不来这个爬虫了。
我也不傻不拉几地自己写建表sql了.直接用的SQLyog。稍微纠结了一下InnoDB和MyISAM。 我开始是想每次把一个电影的信息分别插入三个表,要不要用事务, 又想垃圾数据也不会扣我钱,所以用了MyISAM。毕竟就是大量的Insert和select
建表语句
CREATE DATABASE `douban`; USE `douban`; -- 基本信息表 CREATE TABLE `t_movie_info` ( `id` bigint(20) unsigned NOT NULL COMMENT \'主键,豆瓣电影id\', `type` tinyint(4) DEFAULT NULL COMMENT \'类型 0:电视剧,1:电影\', `name` varchar(30) DEFAULT NULL COMMENT \'电影名字\', `director` varchar(50) DEFAULT NULL COMMENT \'导演\', `year` int(4) DEFAULT NULL COMMENT \'上映年份\', `month` int(2) DEFAULT NULL COMMENT \'上映月份\', `day` int(2) DEFAULT NULL COMMENT \'上映日期\', `categories1` varchar(20) DEFAULT NULL COMMENT \'所属类目1\', `categories2` varchar(20) DEFAULT NULL COMMENT \'所属类目2\', `time` int(3) DEFAULT NULL COMMENT \'时长\', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 -- 主演表 CREATE TABLE `t_movie_actors` ( `id` bigint(20) unsigned NOT NULL COMMENT \'主键,豆瓣电影id\', `actor1` varchar(50) DEFAULT NULL, `actor2` varchar(50) DEFAULT NULL, `actor3` varchar(50) DEFAULT NULL, `actor4` varchar(50) DEFAULT NULL, `actor5` varchar(50) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 -- 评价数据表 CREATE TABLE `t_movie_scores` ( `id` bigint(20) unsigned NOT NULL COMMENT \'主键,电影id\', `score` double unsigned DEFAULT \'0\' COMMENT \'评分\', `votes` int(10) unsigned DEFAULT \'0\' COMMENT \'评价人数\', `star1` double unsigned DEFAULT \'0\' COMMENT \'1星比例\', `star2` double unsigned DEFAULT \'0\' COMMENT \'2星比例\', `star3` double unsigned DEFAULT \'0\' COMMENT \'3星比例\', `star4` double unsigned DEFAULT \'0\' COMMENT \'4星比例\', `star5` double unsigned DEFAULT \'0\' COMMENT \'5星比例\', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8
5. 写一个方法把数据插入到数据库里。 也是第一次用python写数据到数据库,折腾了一晚上。 也不知道哪个小菜比写的 %s 不用加引号,搞得我第一次就看到这个,然后出了错一直认为这个是对的,在找别的原因
def inset_data(movie): # 获取一个数据库连接 conn = pymysql.Connect(host="localhost", port=3306, user="root", password="root", db="douban") # conn.autocommit(True) # 设置自动提交 cursor = conn.cursor() # 获取游标 sql_insert_info = ("insert into `t_movie_info`(`id`, `type`, `name`, `director`, `year`, `month`, `day`, " "`categories1`, `categories2`, `time`) values (%d, %d, \'%s\', \'%s\', %d, %d, %d, \'%s\', \'%s\', %d)") categories = movie["categories"] ca_len = len(categories) categories1 = categories[0] if ca_len > 0 else None categories2 = categories[1] if ca_len > 1 else None cursor.execute(sql_insert_info % (movie["id"], movie["type"], movie["name"], movie["directer"], movie["date"].year, movie["date"].month, movie["date"].day, categories1, categories2, movie["time"])) # 写sql 千万记住 %s 要加双引号,不然会报错 Unknown column \'a\' in \'field list\' sql_insert_actors = ("insert into `t_movie_actors`(id, actor1, actor2, actor3, actor4, actor5)" "values(%d, \'%s\', \'%s\', \'%s\', \'%s\', \'%s\')") actors = movie["actors"] actors_len = len(actors) actor1 = actors[0] if actors_len > 0 else None actor2 = actors[1] if actors_len > 1 else None actor3 = actors[2] if actors_len > 2 else None actor4 = actors[3] if actors_len > 3 else None actor5 = actors[4] if actors_len > 4 else None cursor.execute(sql_insert_actors % (movie["id"], actor1, actor2, actor3, actor4, actor5)) sql_insert_scores = ("insert into `t_movie_scores`(id, score, votes, star1, star2, star3, star4, star5)" "values(%d, %f, %d, %f, %f, %f, %f, %f)") stars = movie["stars"] stars_len = len(stars) star1 = stars[0] if stars_len > 0 else 0.0 star2 = stars[1] if stars_len > 1 else 0.0 star3 = stars[2] if stars_len > 2 else 0.0 star4 = stars[3] if stars_len > 3 else 0.0 star5 = stars[4] if stars_len > 4 else 0.0 cursor.execute(sql_insert_scores % (movie["id"], movie["score"], movie["vote"], star1, star2, star3, star4, star5)) conn.commit() data1 = douban_movie("https://movie.douban.com/subject/30236775/?from=showing") inset_data(data1) data2 = douban_movie("https://movie.douban.com/subject/26842702/?tag=%E7%83%AD%E9%97%A8&from=gaia") inset_data(data2) data3 = douban_movie("https://movie.douban.com/subject/26973784/?tag=%E6%9C%80%E6%96%B0&from=gaia") inset_data(data3) data4 = douban_movie("https://movie.douban.com/subject/30249296/?tag=%E7%83%AD%E9%97%A8&from=gaia") inset_data(data4)
执行完后数据库:


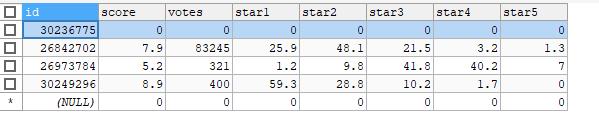
以上是关于Python从0开始写爬虫——把扒到的豆瓣数据存储到数据库的主要内容,如果未能解决你的问题,请参考以下文章