聚类算法DBSCAN算法及其Python实现
Posted 快乐江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法DBSCAN算法及其Python实现相关的知识,希望对你有一定的参考价值。
文章目录
一:DBSCAN算法
(1)快速入门BCSCAN算法
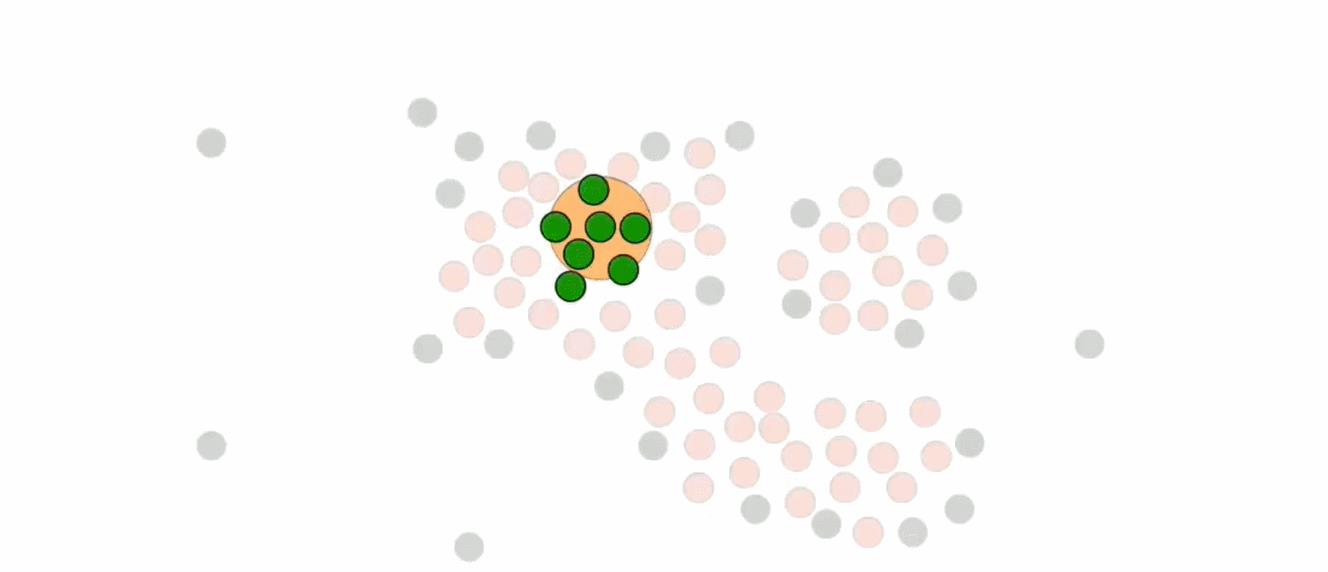
如下是一组未被聚类的数据

可以用肉眼进行大致划分
- 绿色为第一类
- 蓝色为第二类
- 灰色为离群点
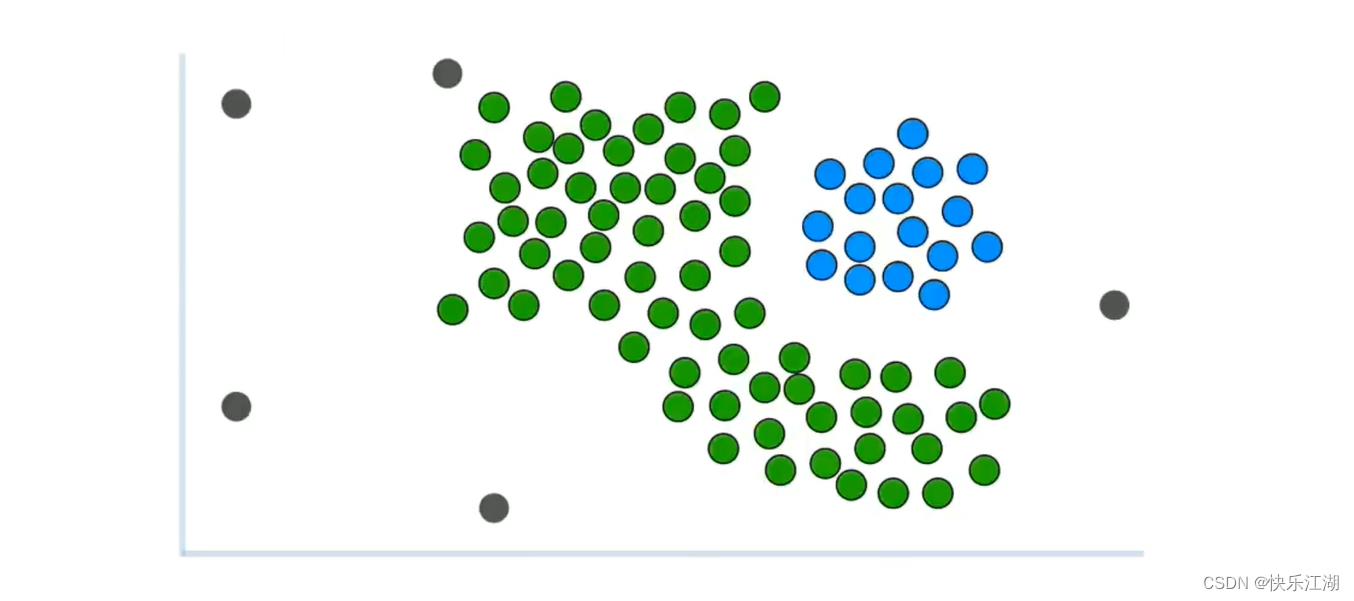
这种非凸数据是无法用K-Means算法进行区分的,如果使用则效果会是这样
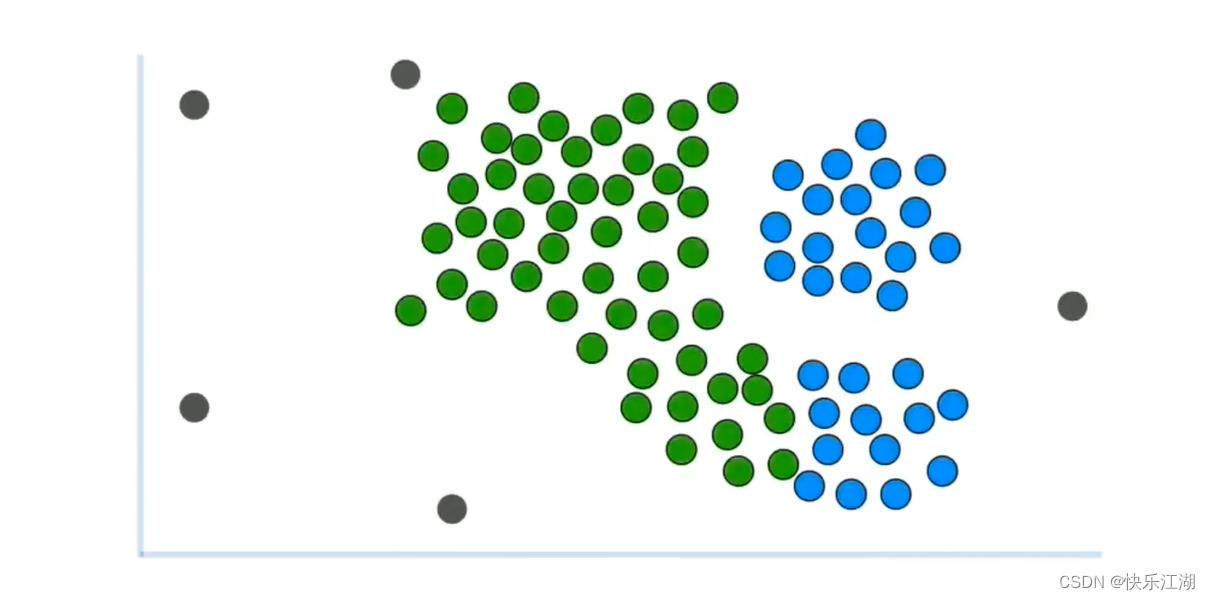
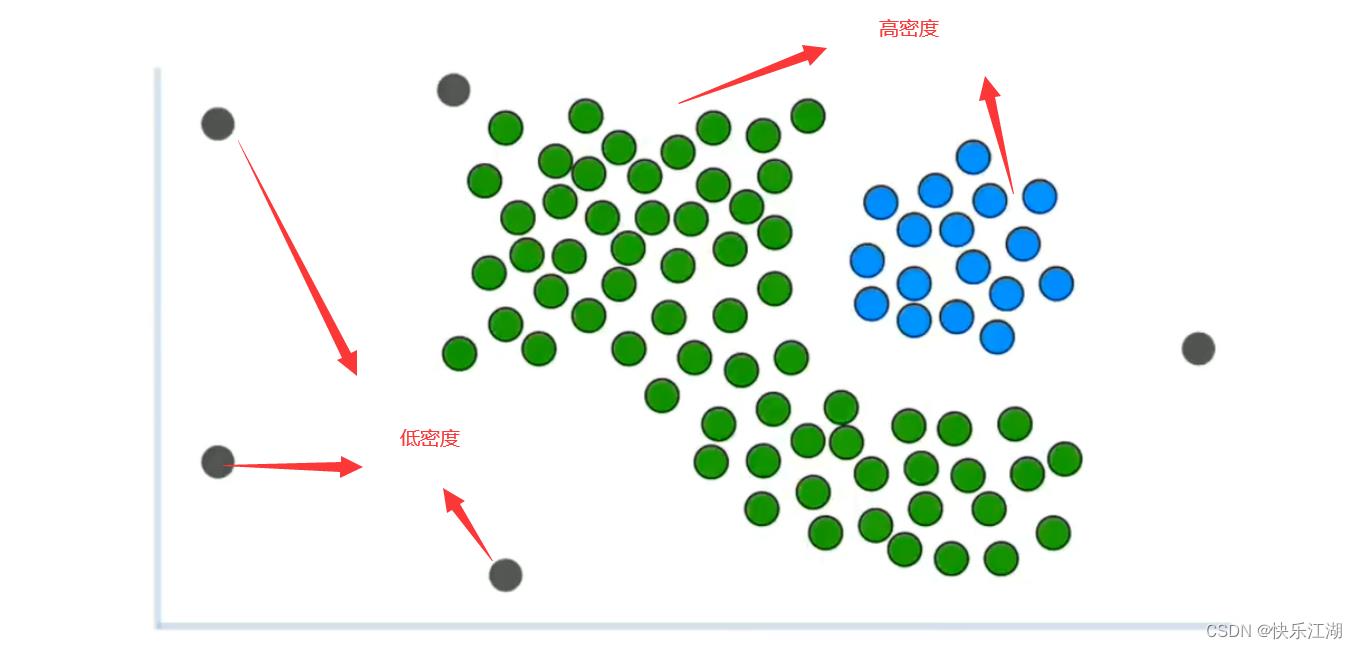
而本节的DBSCAN算法可以解决这个问题。DBSCAN算法通过密度来识别簇
- 簇通常位于高密度区域
- 离群值通常位于低密度区域
核心点是DBSCAN算法中非常重要的点,一个点是否能够成为核心点关键在于该点周围的临近点个数是否大于等于某个 r r r值(称为半径,需要自己提前设定)
- 例如下图,定义这个 r r r值为4,那么第1-4个点可以作为核心点,但第5-6个点不可以
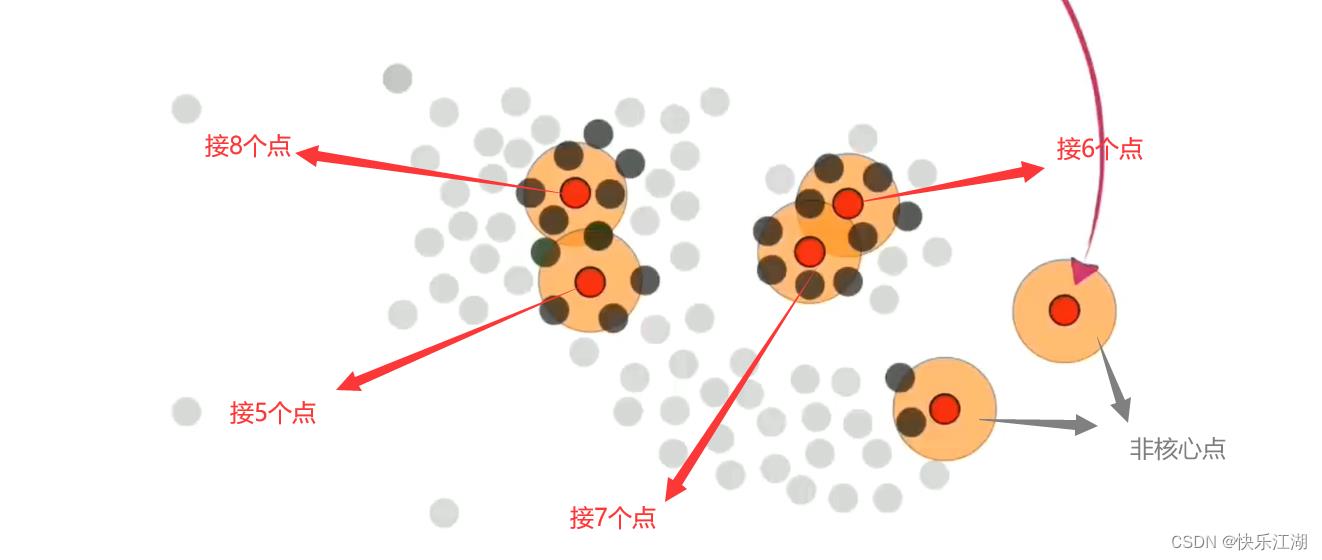

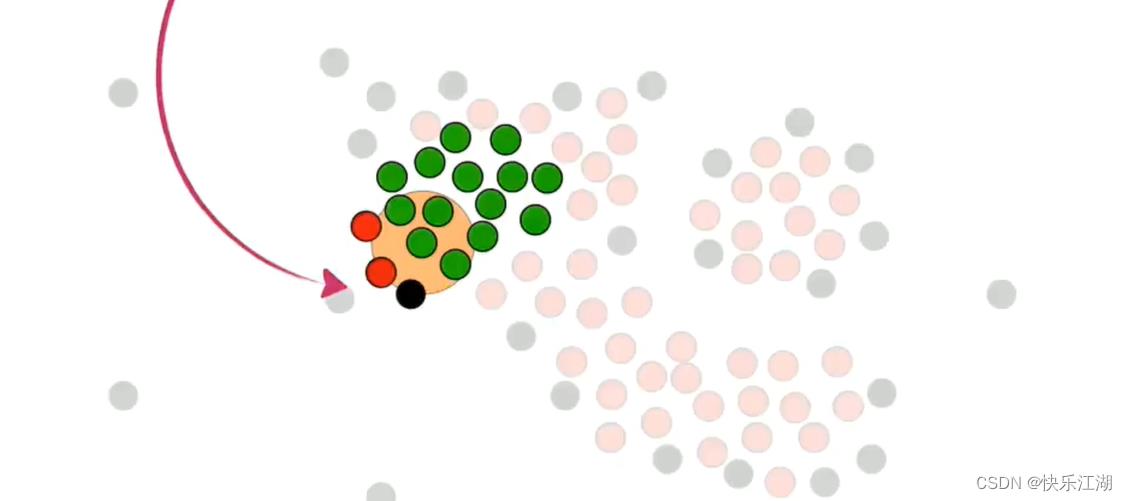
接着,我们挑选这组数据的所有核心点和非核心点
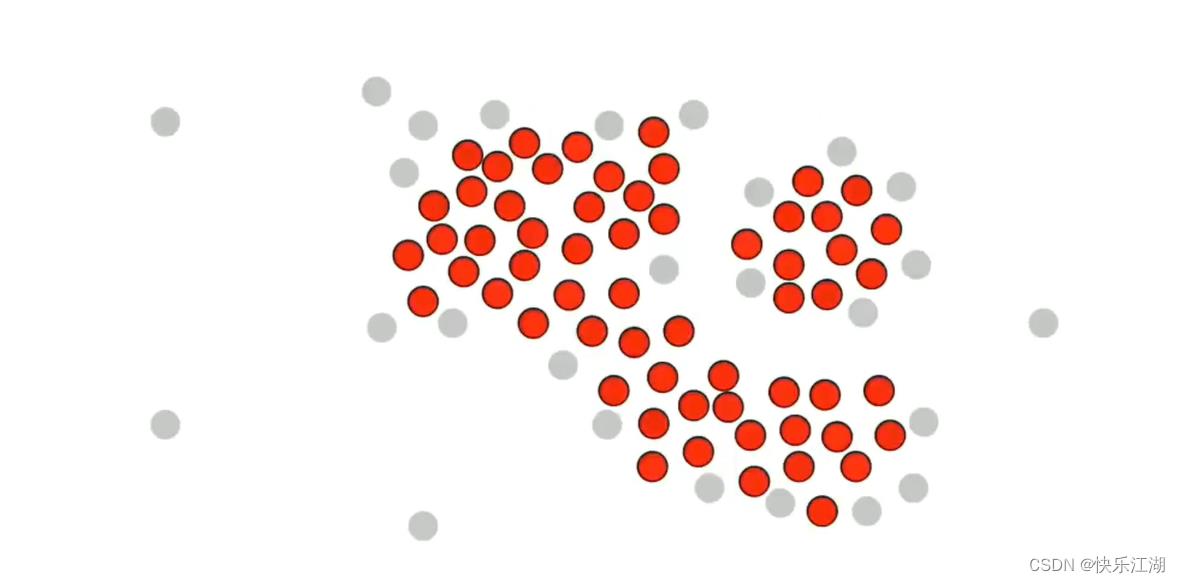
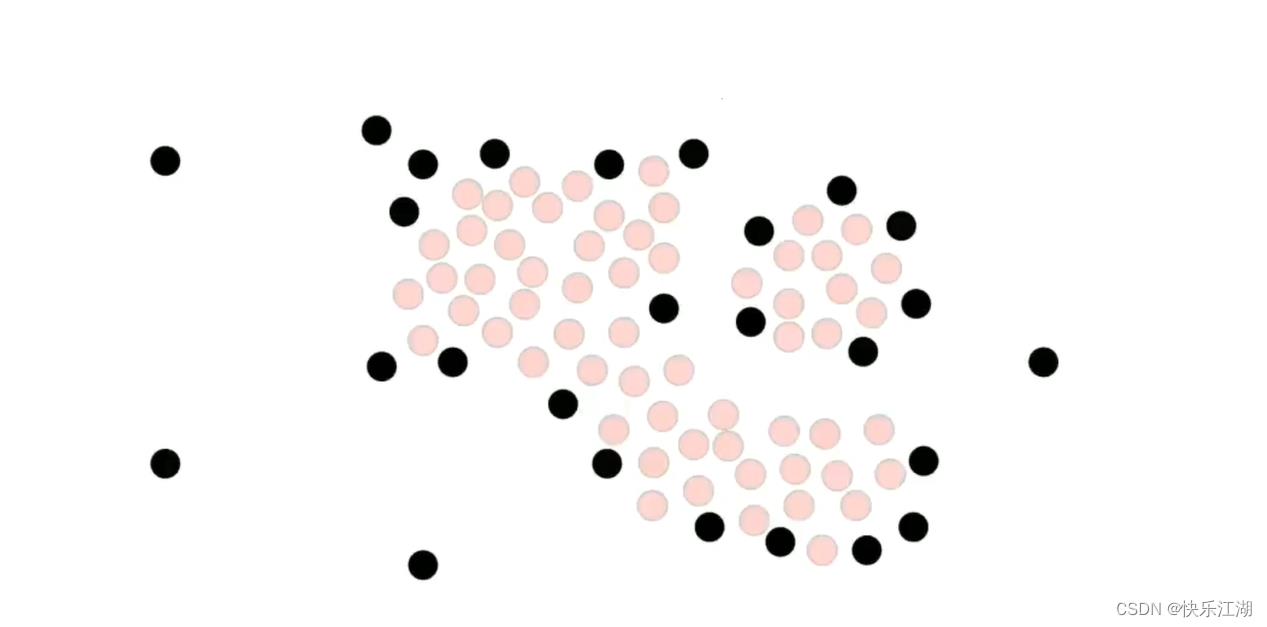
然后在核心点中随机选取一个并标记为绿色,然后把该绿色点周围的所有核心点都加入到该簇中,也标记为绿色
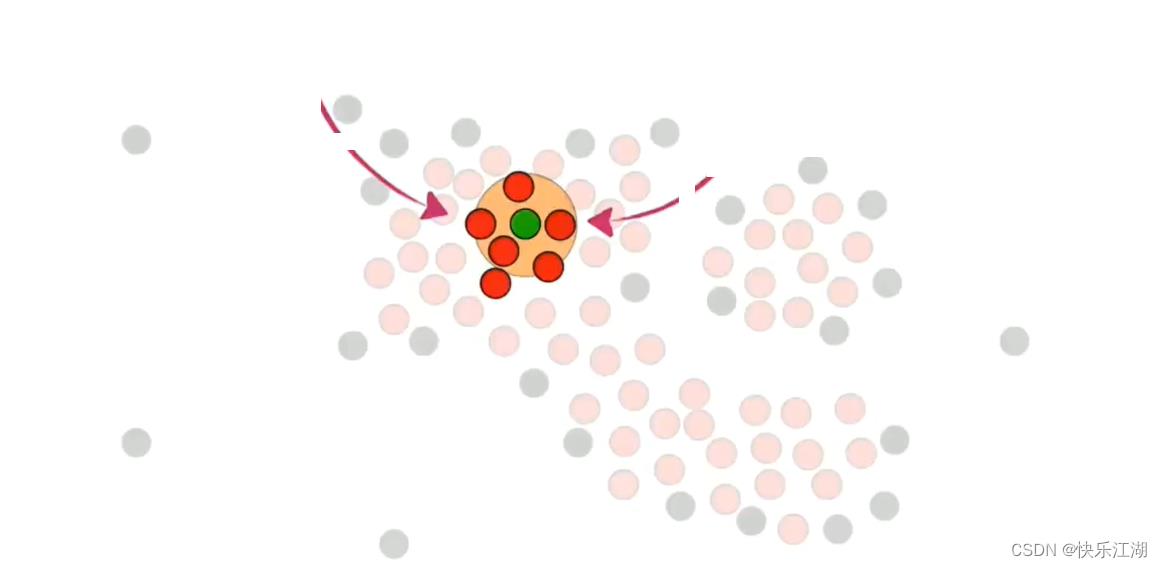
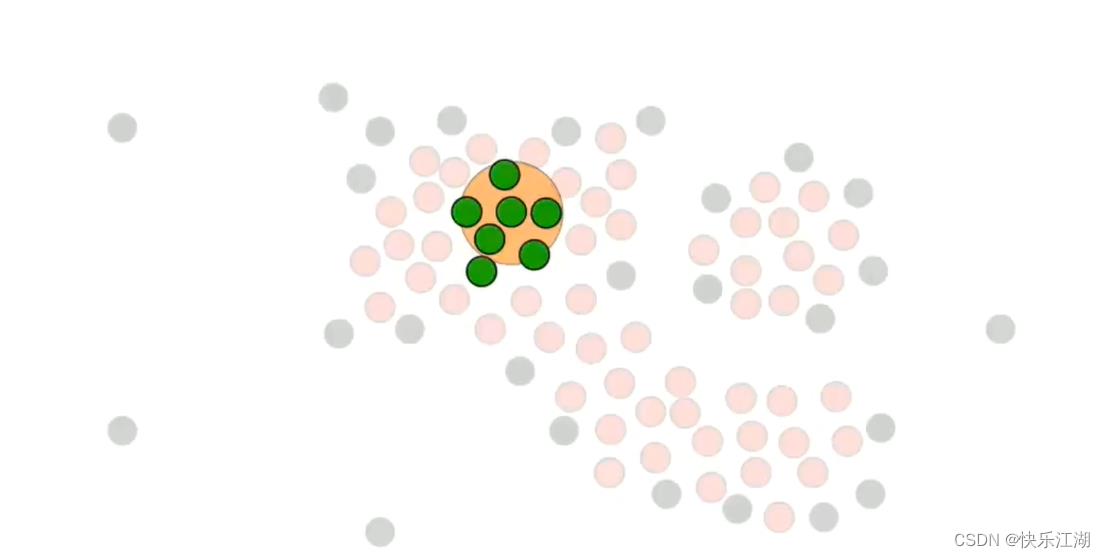
然后对其他绿色点执行重复操作
在处理时,如果同时喷到了核心点和非核心点,则暂时只把核心点加入其中
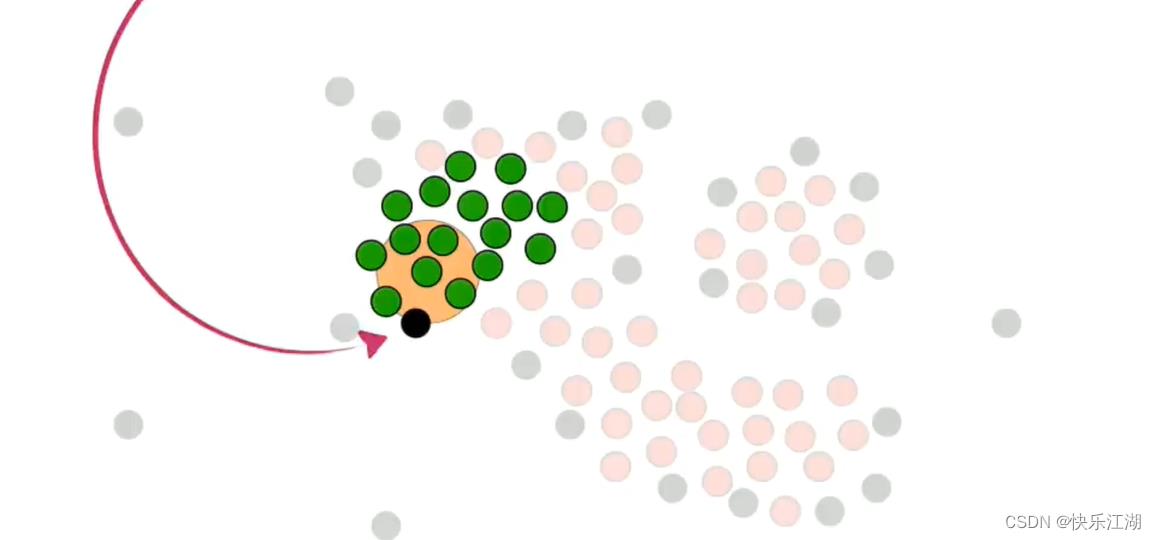
依据这个策略,进行扩展
然后处理非核心点。如下对于这个非核心点,其周围存在属于第一个簇的核心点,所以他可以并入
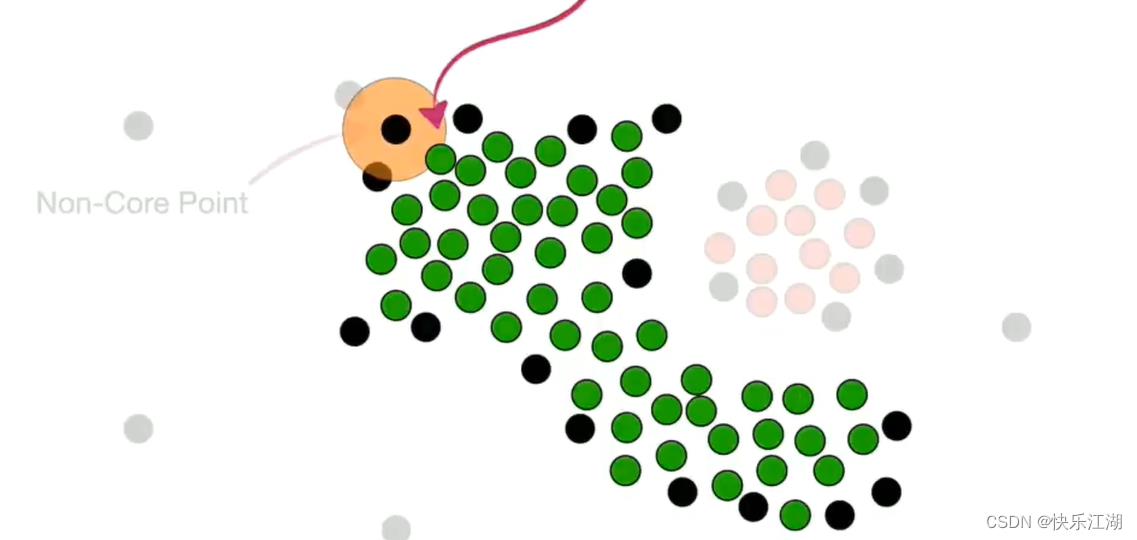
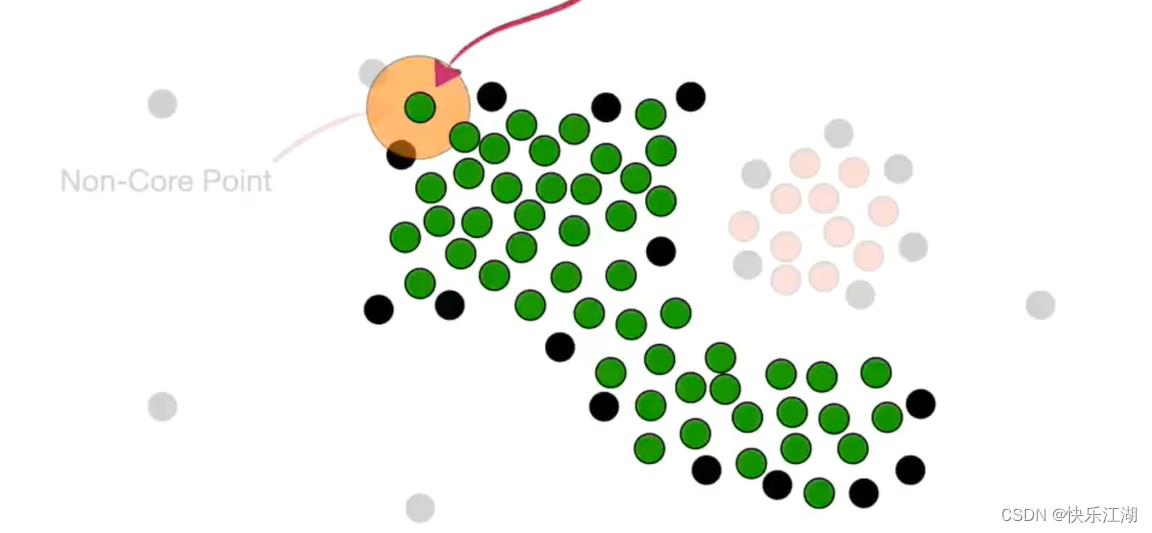
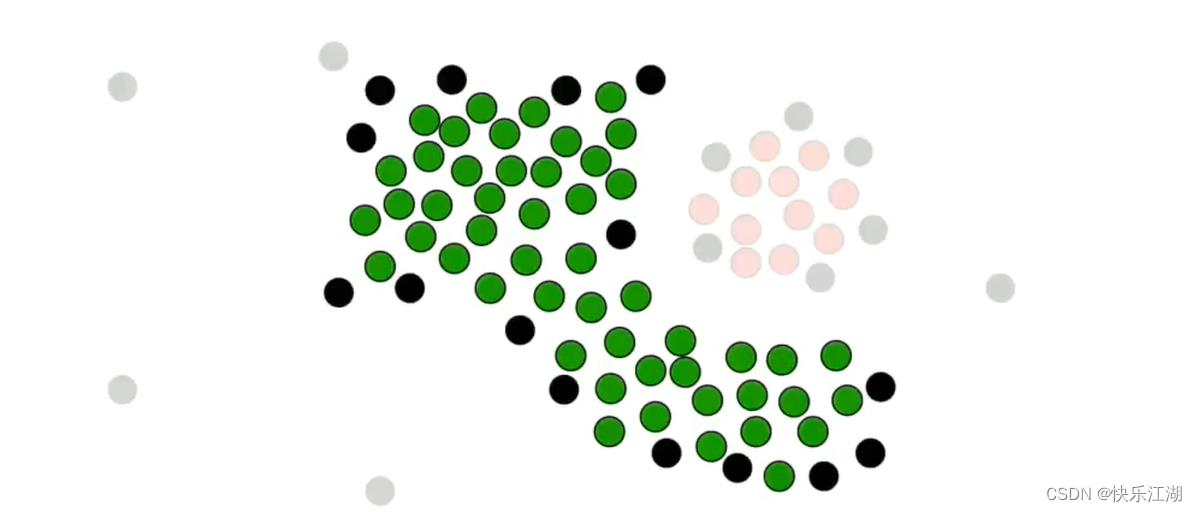
但是该非核心点上面的那个点现在就不可以并入了,或者说这就是它的边界
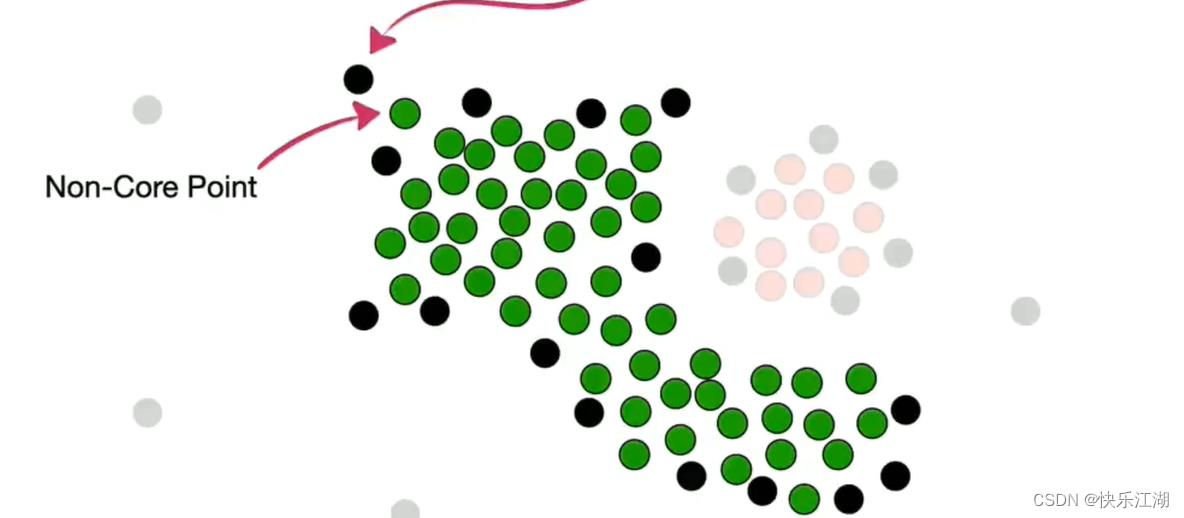
按照这个规则把所有非核心点并入,第一个簇完毕

(2)算法简介
A:基本概念
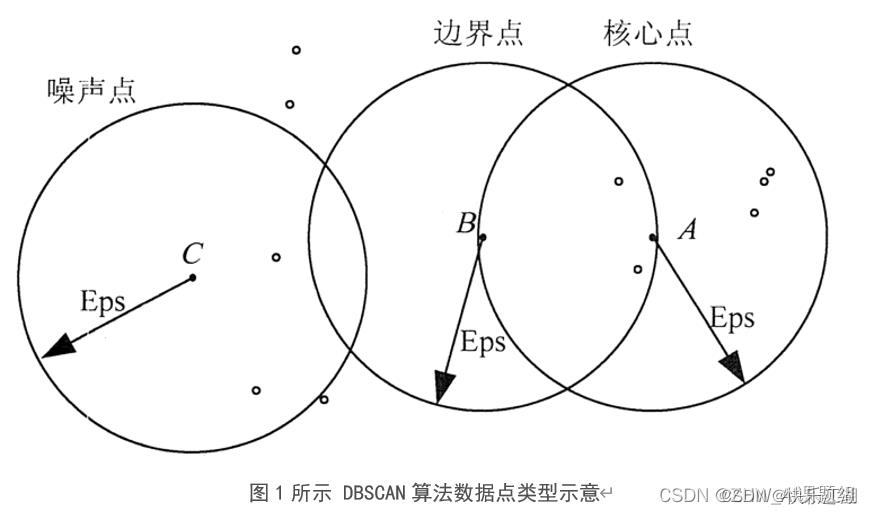
基本概念:DBSCAN全称为Density-Based Spatial Clustering of Applications with Noise,也即基于密度的带有噪声点的聚类方法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据中发现任意形状的簇,它将簇定义为密度相连的点的最大集合;在DBSCAN算法中将数据点分为以下3类
- 核心点: 如果一个对象在其半径
Eps内含有超过MinPts数目的点,则该对象为核心点 - 边界点: 如果一个对象在其半径
Eps内含有点的数量小于MinPts,但是该对象落在核心点的邻域内,则该对象为边界点 - 噪声点: 如果一个对象既不是核心点也不是边界点,则该对象为噪声点
其中Eps和MinPtS是DBSCAN算法中的两个重要参数
Eps:定义密度时的邻域半径MinPts:定义核心点时的阈值
如下图所示,假设MinPts设置为5,箭头表示Eps范围,则:
- A A A是核心点:因为在其Eps邻域内有7个点
- B B B是边界点:因为它落在了 A A A的Eps邻域内
- B B B是噪声点:没有落在任何核心点的邻域内
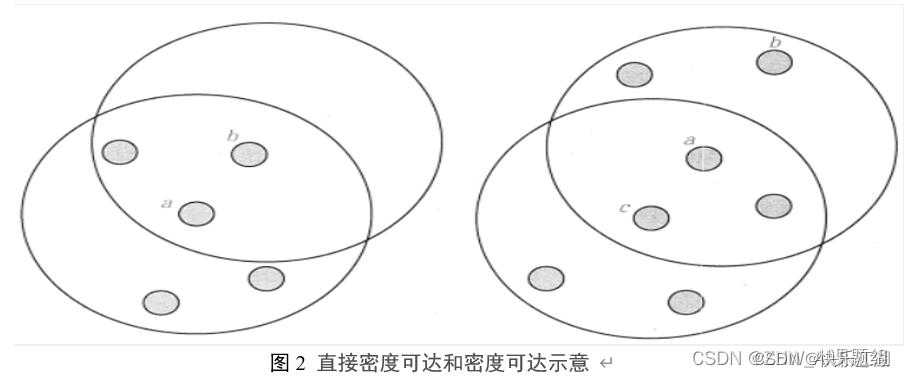
B:直接密度可达、密度可达、密度相连
直接密度可达:如果点 p p p在核心点 q q q的 E p s Eps Eps邻域内,则称数据对象 p p p从数据对象 q q q出发是直接密度可达的
- 注意是 p p p直接可达 q q q,但不能是 q q q直接可达 p p p,除非 q q q也是核心点
密度可达:如果存在数据对象链( p 1 p_1 p1, p 2 p_2 p2, … , p n p_n pn , p n + 1 p_n+1 pn+1),其中 p i + 1 p_i+1 pi+1是从 p i p_i pi关于 E p s Eps Eps和 M i n P t s MinPts MinPts直接密度可达的,则称数据对象 p n p_n pn是从数据对象 p 1 p_1 p1关于 E p s Eps Eps和 M i n P t s MinPts MinPts密度可达的
- 实际上直接密度可达的“传播”
密度相连:若从某核心点 p p p出发,点 q q q和点 k k k都是密度可达的,那么 q q q和 k k k就是密度相连的
如下图:
- 左图:点 a a a为核心点,点 b b b为边界点,所以 a a a直接密度可达 b b b(但 b b b不直接可达 a a a, b b b不是核心点)
- 右图: c c c直接密度可达 a a a, a a a直接密度可达 b b b,所以 c c c密度可达 b b b
(3)算法流程
A:流程
DBSCAN输入为
- 参数 D D D:输入的数据集
- 参数 ε \\varepsilon ε:邻域半径
- 参数 M i n P t s MinPts MinPts:密度阈值
其中 ε \\varepsilon ε和 M i n P t s MinPts MinPts这两个参数的选择非常重要,选择时可以参考如下方法,但是在实际使用时通常时多次尝试即可
- ε \\varepsilon ε:可以根据距 K K K距离来设定,找出 突变点( K K K距离:对于给定的数据集 P P P= p 1 , p 2 , . . . , p n \\p_1, p_2 , ... , p_n\\ p1,p2,...,pn,计算点 p ( i ) p(i) p(i)到数据集 D D D的子集 S S S中所有点之间的距离,距离按从小到大的顺序排序,则 d ( k ) d(k) d(k)就称之为 K 距 离 K距离 K距离)
- M i n P t s MinPts MinPts:一般情况下小一点合适
算法流程如下,整体来说还是很容易理解的


B:演示
现在以下面的样本数据为例,演示DBSCAN算法工作流程
- ε \\varepsilon ε= 3
- M i n P t s MinPts MinPts = 3
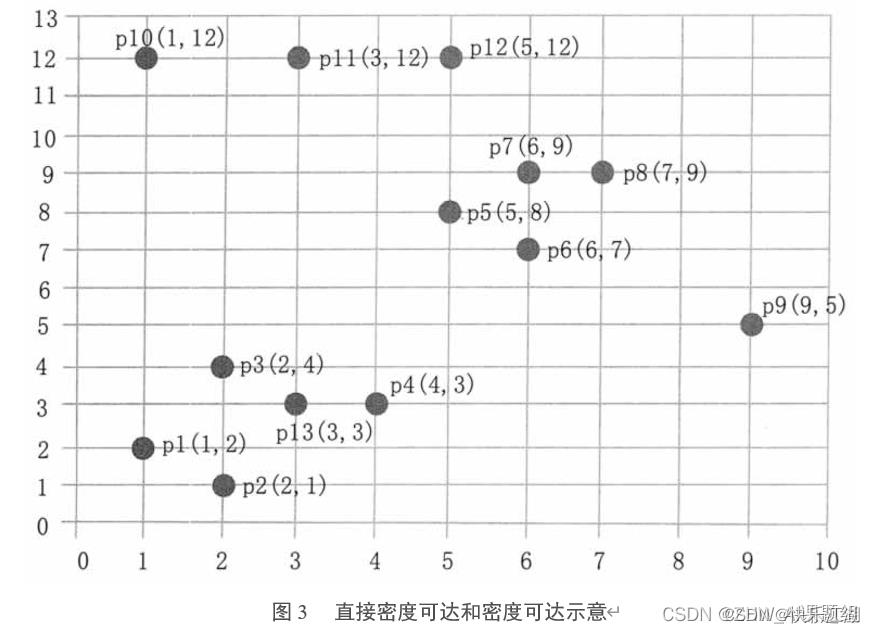
步骤①: 顺序扫描数据集样本点,首先取到 p 1 ( 1 , 2 ) p1(1, 2) p1(1,2)
- 计算每一点到 p 1 p1 p1的距离,例如 d ( p 1 , p 2 ) = 1.414 d(p1, p2)=1.414 d(p1,p2)=1.414
- 根据每个样本点到 p 1 p1 p1的距离和所设邻域 ε \\varepsilon ε= 3,得到 p 1 p1 p1的 E p s Eps Eps邻域为 p 1 , p 2 , p 3 , p 13 \\p1, p2, p3, p13\\ p1,p2,p3,p13
- 所设 M i n p t s Minpts Minpts=3,而 p 1 p1 p1的 E p s Eps Eps邻域有4个点,所以 p 1 p1 p1为核心点
- 因此以 p 1 p1 p1为核心点建立簇 C 1 C_1 C1,找出所有从 p 1 p1 p1密度可达的点( p 1 p1 p1邻域内的点都是 p 1 p1 p1直接密度可达的点,所以都属于 C 1 C_1 C1)
- p 2 p2 p2的邻域为 ( p 1 , p 2 , p 3 , p 4 , p 13 ) (p1, p2, p3, p4, p13) (p1,p2,p3,p4,p13),且 p 1 p1 p1直接密度可达 p 2 p2 p2、 p 2 p2 p2直接密度可达 p 4 p4 p4,所以 p 1 p1 p1密度可达 p 4 p4 p4,因此 p 4 p4 p4也属于 C 1 C_1 C1
-
p
3
p3
p3、
p
4
p4
p4、
p
13
p13
p13也是核心点,其其邻域的点已经都在