Tesla 以 FSD 全自动驾驶为起点的布局
Posted Alex_996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tesla 以 FSD 全自动驾驶为起点的布局相关的知识,希望对你有一定的参考价值。
Tesla在全自动驾驶方面的策略已经和其他厂商形成了本质上的不同,不只是不使用激光雷达这一类主动传感器那么简单,而是要借此实现能够泛化、通用的人工智能,这篇文章就借着全自动驾驶这个内容深入聊聊,Tesla是怎么借着全自动驾驶这张牌对未来布局的。
首先先从前段时间一直被各个媒体炒的比较凶的幻影刹车讲起,所谓幻影刹车指的是在车辆行驶正前方明明没有任何障碍物,而车辆的安全系统以为有障碍物,从而刹车减速的错误驾驶行为。幻影刹车是一种系统做出False Positive假阳性判定的表现,这个问题经常会被很多媒体拿起来说事儿,因为他确实是个很严肃的问题,容易成为事故的隐患。

这个问题几乎每次被提起来都和Tesla绑在一起,好像只有Tesla的车才有这个问题,但其实随便到一些传统品牌的车友会去看看,就会发现对幻影刹车的抱怨其实很普遍,不是Tesla独有的问题,而之所以每次都是Tesla上新闻,主要是大家对他的期望比较高,毕竟智能和安全是很多用户选择他出来的主要原因。其次呢,Tesla 现在主打的是 Tesla Vision,只用视觉的感知系统,这种高调的和主流认知的不同,更容易吸引更多的质疑,甚至是不理解。
Tesla 纯视觉自动驾驶方案
对于 Tesla 的车主们幻影刹车的讨论,主要的抱怨还是集中在 Autopilot 辅助驾驶上,并不是说这个问题在 FSD Beta 全自动驾驶测试版上没有,只是出现的不是那么的频繁。这其实从侧面反映了 Tesla 依靠视觉算法来估测距离的功能还并不准确,因为幻影刹车的主要问题就是对距离估测的不准确。
只使用2D视觉信息进行3D空间估测在算法方面一直是一个困难的课题,Tesla的做法是使用配备有激光雷达的工程车辆对视觉算法估测出来的距离进行验证,过程很类似于监督学习,视觉算法对每个像素点估计距离,对了没有奖励,错了就重新来,周而复始,直到视觉算法对距离的感知达到一个比较稳定的水平,之后就是在这个基础上不断的完善。

Tesla 在视觉感知方面走的要比其他厂商更远,尤其是在使用视觉算法估距离这方面。可以简单的看一下这段动图,其中一块一块像积木的东西,学名叫体素(Volume Pixel),也就是立体像素的意思,所展示的就是 Tesla 的算法对摄像头所拍摄到的画面中每一个二维像素进行距离估测的结果。这个效果来自于 Rice_Fry 大神的 Twitter,他把 HydraNets 中一个头部网络的输出,进行了加工和可视化,可以说这算是把 Tesla 在 AI Day 上所说的图像信息投射入向量空间再进行3D重塑这个想法最直接的表示。
为什么不要激光雷达?
使用视觉算法对物体实现像素级别的距离估测,实际上算是模拟的激光雷达的效果。那直接加个真的激光雷达不就完事了么?为什么要费这么大劲搞个模拟的?当然成本是一方面。但是除此之外,Tesla 搞法看起来确实是有点儿舍近求远意思,也没有遵循著名统计学家——弗拉基米尔·瓦普尼克(机器学习先驱)所说的:在解决问题的时候,要避免通过解决的另一个更难的问题来作为过渡。经常把这句话提起来的是 Mobileye(以色列一家汽车科技研发公司),现在也是采用视觉算法为主,激光雷达加新型雷达为辅,两套方案的打法。
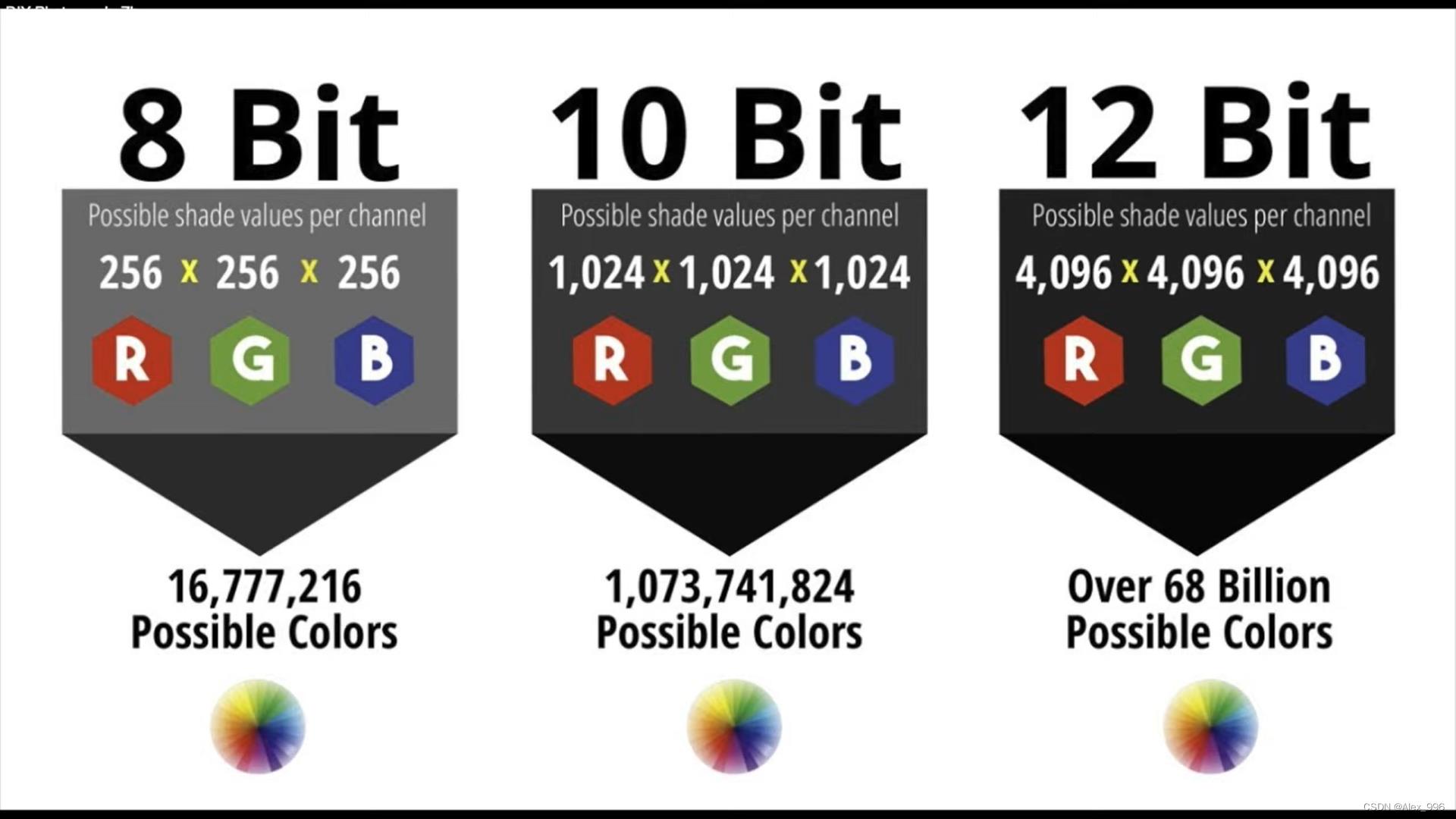
这就很难不让人质疑 Tesla 在只用视觉方案这件事儿上的执着,是不是有点儿欠考虑?咱们在就这个问题深究之前,先来看看 Tesla 最近在中做出的一些改进。在 FSD 10.9 的 release notes 中,Tesla 提到通过在神经网络的结构中直接使用10位光子信息来取代8位色调映射信息,从而在静态物体的识别上精准度上升1.7%,召回率提高了3.9%,而实现的方法是通过在软件上的改动,直接使用10位的光子信息,不再需要 ISP 来进行色调映射(Tone Mapping)的后期处理。

这句话听起来挺简单的,但包含的信息量巨大。首先是色调映射,简单说就是把光的范围信息进行转化,从而起到调整和匹配的作用。大概是这么个效果,如果以左为的图为原始图像,那中间的和右边的就是色调映射后的效果。这个功能的实现一般是由存储在 ISP 中的传统算法来完成,是图像后处理流程的一部分。ISP 是 Image Signal Process 的简写,也就是图像信号处理器,ISP直接放在图像传感器后面进行各种对图像信号的处理,比如大家比较熟悉的白平衡、图像锐化、逆马赛克的处理都是在 ISP 完成的。

ISP 最早要解决的问题只是简单的如何让摄像头拍出来的画面更好看,说白了就是被人类的眼睛服务,不过这两年随着硬件算法的进步以及在需求上面改变,更多的厂商开始重视ISP的功能,要求ISP不但要为眼睛服务,还要能为算法服务。这其中比较高调的就是苹果,早在推出A5芯片的时候,苹果就开始强调自主研发ISP的重要性,而从结果上看,苹果的这个策略确实是有效的,在iPhone 4S的时代,苹果手机的拍照能力在众多厂商中确实是比较出彩的,原因也很简单,一来开发 ISP 可以把算法的话语权控制在自己手里,其次,ISP 离图像的原始信号很近,任何改进所产生的效果都会是立竿见影的。

不过 ISP 离原始信号再怎么近也还是有距离的,ISP 中存储的算法计算起来也是要花时间的,虽说一般的认知是 ISP 中的算法都是硬件加速为基础的底层算法,速度是飞快,就算把 ISP 整个给移除,也就是在处理的时间上节省了3~4毫秒的样子。Tesla 现在的做法就等于提出,既然 ISP 是一大堆算法组成的流程,我的视觉感知也是算法组成的流程,那我能不能跨过 ISP 这个中间人,直接去视觉信号的源头得到我所需要的信息呢。
要实现这个目的,就要从 ISP 再往前退一步:摄像头的传感器是怎么拍摄到画面的?其实啊,这就和水枪打靶游戏差不多一个意思,打中靶心的水量越大,也就越容易推到靶子。把光子当成水枪射出的水,把像素看成靶心,这事儿就好理解了,各路的光通过镜头的收集投射进传感器,光子在经历了颜色分类后,落在光敏二极管上,光子越多,能量越大,所产生的电信号也就越强,从而激活的像素也就越亮,这就是所谓的光电转化。

在这儿得到的就是图像的原始数据,其所包含的海量数据对算法来说可是求之不得的,就拿 Tesla 从8位跳到10位图像信息来说,8位空间可以表示1600万个不同的颜色,而10位空间的颜色表示超过了10亿个,信息量上达到了64倍的增长,而对于这个规模信息量的深度挖掘则体现了 Tesla 现阶段系统设计上的理念,简单的说,就是在 Tesla 看来实现驾驶这个任务所需要的所有信息全部都包含在的视觉图像中,而 Tesla 要做的就是最大程度的挖掘和利用这些信息。
这话听起来好像还是在说 Tesla 给自己加了个只用摄像头的限制,而且感觉有那么点儿从结果倒推原因的嫌疑,但实际上 Tesla 的做法是在强调如何在简单原始的信息和行为之间,建立一个类似于经验积累的系统,而没有采用传统的把复杂问题化为多个简单问题,然后在不同空间内求解的方法。
激光雷达和车联网的限制
激光雷达这类主动传感器的作用就是准确的感知物体之间的距离,为什么驾驶需要这个?因为根据人类的经验,物体之间的距离对安全的驾驶决策很有必要,那人类在驾驶时是怎么感知距离的?答案是依靠日积月累的日常经验所形成的感知,而 Tesla 的想法就是那我就模仿人类直接训练这个感知不就得了。
除了使用激光雷达来感知距离这种将问题转化的方法,其他的辅助手段还有 Mobileye 的 REM (Road Experience Management) 系统,这个系统就是把路上其他人类驾驶员的行车轨迹,拿给本车的自动驾驶系统做参考,是一种不问为什么,只是简单的对行为进行模拟的方法。
在我看来,上面这两种做法从目前来说都是十分有利于开发出自动驾驶系统的,而且是比 Tesla FSD 更早甚至体验更好的 Level 4 自动驾驶系统。之所以这么说,主要还是因为无论是使用主动传感器还是 REM 这一类的 V2V 实时信息共享系统,这些个方法的本质都是基于对人类经验总结的倒推,所关注的是怎么实现结果的问题。从实现产品目的的角度想,是一种走捷径,抄近道的做法。

在这段视频中,Tesla 完全忽略了地面上的地标障碍物,径直就撞上去了,从视频中看 FSD Beta 在这儿所犯的错误是对可行驶路面判断的失误,一来对地面划线没有能够准确的识别,二来这个版本的 FSD Beta 应该是没有对这一类的地标障碍物进行过学习,把它判定成雪糕筒的置信率又有点低,从而就直接忽略了,而如果使用激光雷达这个事故我觉得是完全可以避免的。

还有在这儿,FSD Beta 没有意识到自己是在往非机动车道上开,而如果使用了 Mobileye 的 REM 系统,本车大概会知道:今天有100辆车开过这条路,没有一辆车往这条道上开,虽然不知道是什么原因,但我也不往那儿开就是了,从而也就回避了要从视觉画面中摘出信息来理解这是非机动车道不能开的问题。说实在话,Mobileye 的 REM 系统在这儿都是大材小用,现在稍微靠谱一点儿的导航地图都可以很简单的识别非机动车道,从而避免这一类的问题。
更进一步,布局强人工智能
那是不是说 Tesla 只依靠视觉系统的执着,把自己逼进了一个死胡同吗?说是死胡同,我觉得那倒也不至于,Mobileye 的 REM 系统现在也是主推视觉系统,不过骑虎难下也是有点,因为从自动驾驶产品定义的角度考虑,就算 Tesla 出于各种原因不使用激光雷达,那开发类似 REM 的 V2V 系统也是可以做到的,而之所以在只使用视觉这条路上一去不复返,我觉得主要还是 Tesla 发现自己在这件事儿上早期的执着所推导出的结果已经远远超出了原来的产品定义。如果大家细品品就不难发现,Tesla 现在实际上是在说视觉信息已经够用了,我就需要训练的可以理解这些信息并加以利用的脑子。如果说其他公司是在机械的为实现自动驾驶而拼装功能,那 Tesla 所要挑战的就是可以泛化出能够自动驾驶的智能。
很多人在评论 Tesla 的技术方案时都会提到,Tesla 的做法是要解决一个更通用、更广义的问题,这里所指的广义问题往远了看,实际上就是如何制造智能这件事儿,Tesla 之所以可以借着自动驾驶开始考虑如何人造智能,我觉得倒也不是一开始的计划好的,就如说刚才所说的,Tesla 在只使用视觉系统这件事儿上的执着,算是给自己逼出来个海阔天空。
说根到底,这执着的本身还是来自于马老师以第一性原理为基础的思考模式,马老师所提倡的 First Principle Reasoning 的重点在于Reasoning这部分,也就是论证和推理的过程,其本质和咱们的老话透过现象看本质很像,只不过是特别强调了要基于科学,尤其是物理原理的,透过现象看本质。

如果按照这个想法说,那驾驶这件事儿的本质是什么?如果对人类驾驶这件事儿进行高度抽象,那驾驶是不是可以理解为被光子所激活的像素和行为之间形成的一种因果关联?如果你觉得这话说的通的话,那 Tesla 所要做的就是使用善于学习关联的神经网络,来试图建立从视觉感知到行为的联系,而咱们刚才所说的和人类日积月累的经验很类似的感知,实际上就可以被看成是对人类来说非常原始的新手村级别的智能,而在这么个推断的过程中,Tesla 也意识到最终的产品将会是智能本身,其他都是载体。
对于智能的开发,尤其是可泛化,通用一类的智能,现在并没有明确的路径,很多的研究都会强调通过数据和算法所形成的所谓经验积累,应该是建立的与现实环境的互动基础之上,也就是在强调人类在学习中试错这个方法的重要性,要实现这个,就需要可以收集各种数据的介质和强大高效的算力。
先说说收集数据的事儿,对于驾驶这件事儿,各位 Tesla 的车主实际上就是那勤劳的小蜜蜂,只要您在路上开,就是在帮 Tesla 收集数据。这事儿啊好理解,但是这些数据强调了和驾驶有关的信息,要实现泛化和通用,就要收集可以代表通用的数据,这个重担就落在了 Tesla Bot 的肩上,就如 Tesla AutoPilot 的视觉团队负责人 Andrej Karpathy 在最近招人的博文中所提到的,Tesla Bot 将成为最强力的人工智能开发平台。

而对算力的需求就更直白了,而且还还是刚需。OpenAI 使用强化学习的方法训练出强悍的人工智能玩 DOTA2,完虐人类玩家,看着确实很吓人,让人觉得这类的人工智能赶超人类简直是轻而易举,但如果你简单的翻一下 OpenAI 实现这套东西的方法,就会发现这种类似于左右互搏的训练方法所需要的训练时间是以年为单位的,想要缩短训练时间,就必须使用并行计算的方法。Tesla 也需要这样的并行算力,不但要并行,而且还要能灵活的适应不同大小的神经网络,从而提高效率,最好是还能为自家的 FSD 系统做出各种优化。事实证明这样十全十美的系统自然是没有的,于是 Tesla 就本着有条件要上,没有条件创造条件也要上的原则,自己开发了 Dojo 道场系统。
有了充分的数据和强大的算力,剩下的就是怎么充分利用数据来训练一个足够通用,足够泛化的强人工智能。
以上是关于Tesla 以 FSD 全自动驾驶为起点的布局的主要内容,如果未能解决你的问题,请参考以下文章