用 Elasticsearch 统计做了几次核酸检测?怎么破?
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 Elasticsearch 统计做了几次核酸检测?怎么破?相关的知识,希望对你有一定的参考价值。
1、两个实战场景问题
事出有因,近期的两个问题比较类似:
Q1:如何在 Elasticsearch 实现统计做了 5 次(含以上)核酸检测的人员名单及详情?

Q2:请教下大家,业务场景要记录每个人的每天的出勤情况,今天出勤标记为1或者当天日期,未出勤不记录,或者为0,有个个人信息索引,那么这个出勤情况改怎么存储,用数组?还是这种场景不适合es?要实现:查询在某段时间至少出勤几次的人,这个字段目前存的是日期数组,然后我们有需要要查询比如1号到15号,至少出现3次 满足条件的人?
这两个问题本质是一类问题,这类问题涉及技术选型、方案选型、实现细节等问题,本篇文章我们一并讨论一下。
2、关于选型
先看 mysql 怎么搞!以核酸检测为例,设计两个基础表(以下信息已经全部脱敏处理):
表1:用户基础信息表 user_info

表2:核酸检测信息表 nucleic_test_info
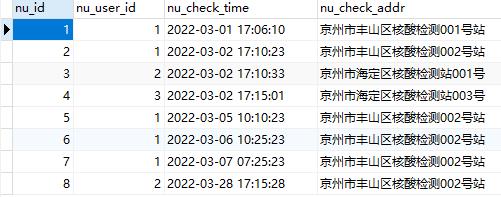
通过两个表关联,然后借助 having 条件判定加上时间条件判定过滤就能找到满足条件的数据。实现方式如下:
select s_id, s_id_number, s_name, nu_check_time from user_info, nucleic_test_info
where user_info.s_id = nucleic_test_info.nu_user_id
and nucleic_test_info.nu_user_id in
(select nu_user_id
from nucleic_test_info
group by nu_user_id
having count(nu_user_id) >= 5)
and nu_check_time >= "2022-03-01 00:00:00" and nu_check_time <= "2022-03-31 23:59:59";用户期望的查询结果如下:

这个问题,如果用 Elasticsearch 会转嫁为两个核心问题:
问题 1:选型问题——如上问题的选型 Elasticsearch 是否合适?
问题 2:如果非要选型 Elasticsearch,那么如何实现上述 MySQL 的业务逻辑呢?
我们先先讨论问题 1。
多表关联是 Mysql 的强项,但是 Elasticsearch 就有些捉襟见肘、力不从心。
选型的时候要注意各取所长,将各个技术栈的优势发挥到极致。
MySQL 支持事务ACID 特性且支持多表关联,但太多表关联会有性能问题,《阿里巴巴Java开发手册》有强调“超过三个表禁止 Join”
Elasticsearch 更擅长大规模数据量级别的全文检索,且ELKB 整合优势对于数据分析也方便快捷。之前的文章咱们分析过:探究 | Elasticsearch 与传统数据库界限也推荐再次读一遍。
选型的细节还有很多综合因素,需要结合业务进行讨论,所以,这里我没有展开。
但,这时候同学可能会有疑问?那类似多表关联问题,Elasticsearch 就搞不定了?
不是的!
Elasticsearch 支持的关联方式核心就如下几大类:
宽表方案
nested 嵌套文档实现
join 父子文档实现
业务层面自己实现
本文是建立在选型 Elasticsearch 作为核酸检测存储方案的基础上,从数据建模、数据写入、数据检索实现三个维度对不同的实现方案进行拆解剖析。
为方便读者自己动手实战,本文会有大篇幅的 DSL,如有不适感,建议先关注文字描述和截图。
3、Elasticsearch 宽表实现
3.1 宽表 Mapping 建模
宽表的方案本质是“冗余存储”,借助“空间换时间”实现高效检索。
所以,该方案写入数据部分会有大量的冗余个人信息存储。

宽表存储
# 宽表创建索引
PUT nucleic_testing_infos
"mappings":
"properties":
"s_id_number":
"type": "keyword"
,
"s_phone":
"type": "keyword"
,
"s_name":
"type": "keyword"
,
"s_wx_id":
"type": "keyword"
,
"s_address":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"
,
"nu_check_time":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
,
"nu_check_addr":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"
如上所示:字段中规中矩。
3.2 数据写入
# 宽表导入数据集
PUT nucleic_testing_infos/_bulk
"index":"_id":1
"s_id_number":"910105197612304XXX","s_phone":"13655551111","s_name":"王小一","s_address":"京州市丰山区35号","s_wx_id":"wang_01","nu_check_time":"2022-03-01 17:06:10","nu_check_addr":"京州市丰山区核酸检测001号站"
"index":"_id":2
"s_id_number":"910105197612304XXX","s_phone":"13655551111","s_name":"王小一","s_address":"京州市丰山区35号","s_wx_id":"wang_01","nu_check_time":"2022-03-02 17:10:23","nu_check_addr":"京州市丰山区核酸检测002号站"
"index":"_id":3
"s_id_number":"910105197612304XXX","s_phone":"13655551111","s_name":"王小一","s_address":"京州市丰山区35号","s_wx_id":"wang_01","nu_check_time":"2022-03-05 10:10:23","nu_check_addr":"京州市丰山区核酸检测002号站"
"index":"_id":4
"s_id_number":"910105197612305XXX","s_phone":"13655552222","s_name":"张小二","s_address":"京州市海定区002号","s_wx_id":"zhang_02","nu_check_time":"2022-03-02 17:10:33","nu_check_addr":"京州市丰山区核酸检测002号站"
"index":"_id":5
"s_id_number":"910105197612305XXX","s_phone":"13655552222","s_name":"张小二","s_address":"京州市海定区002号","s_wx_id":"zhang_02","nu_check_time":"2022-03-28 17:15:28","nu_check_addr":"京州市丰山区核酸检测002号站"
"index":"_id":6
"s_id_number":"910105197612303XXX","s_phone":"13655553333","s_name":"刘三","s_address":"京州市海定区003号","s_wx_id":"liu_03","nu_check_time":"2022-03-02 17:15:01","nu_check_addr":"京州市海定区核酸检测站003号"如上所示,为了保证检索的遍历,个人信息会有大量的“冗余”。
3.3 检索实现
宽表具体的实现
POST nucleic_testing_infos/_search
"size": 0,
"query":
"bool":
"must": [
"range":
"nu_check_time":
"gte": "2022-03-01 00:00:00",
"lte": "2022-03-31 23:59:59"
]
,
"aggs":
"terms_aggs":
"terms":
"field": "s_id_number",
"size": 10,
"min_doc_count": 3
,
"aggs":
"top_hits_aggs":
"top_hits":
"_source":
"includes": [
"s_id_number",
"s_phone",
"s_name",
"s_address",
"s_wx_id",
"nu_check_time",
"nu_check_addr"
]
,
"size": 10
检索部分实现了 MySQL where 条件子句的功能;
借助于基于身份证号的 terms 分桶聚合实现;
参数:min_doc_count 实现了类似 MySQL having 条件的功能;
top_hits 聚合的目的是获取聚合后的详情信息。
4、Elasticsearch 宽表数组方案
既然上面的方案涉及到冗余存储,会有大量的空间浪费。
那自然有同学会想到:“我用数组存储核酸检测时间,地点我不考虑了,不就可以节约存储了”。
行,没问题,你说的都对。
但是实现起来,你看看下面的检索就知道——这也太太太复杂了吧?!
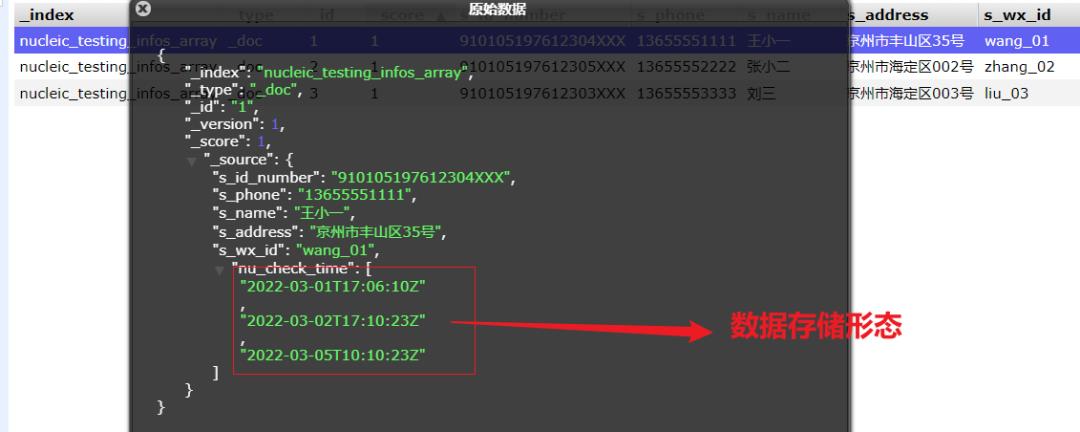
宽表数组形态
4.1 宽表数组方案
DELETE nucleic_testing_infos_array
PUT nucleic_testing_infos_array
"mappings":
"properties":
"s_id_number":
"type": "keyword"
,
"s_phone":
"type": "keyword"
,
"s_name":
"type": "keyword"
,
"s_wx_id":
"type": "keyword"
,
"s_address":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"
,
"nu_check_time":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
4.2 宽表数组写入
PUT nucleic_testing_infos_array/_bulk
"index":"_id":1
"s_id_number":"910105197612304XXX","s_phone":"13655551111","s_name":"王小一","s_address":"京州市丰山区35号","s_wx_id":"wang_01", "nu_check_time": ["2022-03-01T17:06:10Z", "2022-03-02T17:10:23Z", "2022-03-05T10:10:23Z"]
"index":"_id":2
"s_id_number":"910105197612305XXX","s_phone":"13655552222","s_name":"张小二","s_address":"京州市海定区002号","s_wx_id":"zhang_02","nu_check_time": ["2022-03-02T17:10:33Z", "2022-03-28T17:15:28Z"]
"index":"_id":3
"s_id_number":"910105197612303XXX","s_phone":"13655553333","s_name":"刘三","s_address":"京州市海定区003号","s_wx_id":"liu_03","nu_check_time":["2022-03-02T17:15:01Z"]4.3 宽表数组检索实现
POST nucleic_testing_infos_array/_search
"query":
"bool":
"filter":
"script":
"script":
"source": """
double amount = doc['nu_check_time'].size();
boolean flag = false;
int icount = 0;
String start_time = params.start_time;
String end_time = params.end_time;
ZonedDateTime start_zdt = ZonedDateTime.parse(start_time);
ZonedDateTime end_zdt = ZonedDateTime.parse(end_time);
long start_litmemills = start_zdt.toInstant().toEpochMilli();
long end_litmemills = end_zdt.toInstant().toEpochMilli();
for (item in doc['nu_check_time'])
long litmemills = item.toInstant().toEpochMilli();
if(litmemills <= end_litmemills && litmemills >= start_litmemills)
icount++;
if (icount >= params.length)
flag = true;
return (amount >= params.length && flag);
""",
"lang": "painless",
"params":
"length": 3,
"start_time": "2022-03-01T00:00:00Z",
"end_time": "2022-03-31T23:59:59Z"
建模、写入不必多说。
着重说一下检索部分,检索部分用脚本实现。
第一:统计了数组大小,数组大小必须的大于我们要求的检索值大小,否则没有意义。
第二:统计各个时间字段是否在给定检索要求的时间范围内,如果在,就加1。
第三:比较时间大小,转成了时间戳处理的方案,否则不好处理,仅字符串的比对会有很大的“瑕疵”。
5、Elasticsearch Nested 嵌套实现
5.1 nested 建模
DELETE nucleic_testing_infos_nested
PUT nucleic_testing_infos_nested
"mappings":
"properties":
"s_id_number":
"type": "keyword"
,
"s_phone":
"type": "keyword"
,
"s_name":
"type": "keyword"
,
"s_wx_id":
"type": "keyword"
,
"s_address":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"
,
"check_time_flatted":
"type": "date"
,
"check_in":
"type": "nested",
"properties":
"nu_check_time":
"type": "date",
"copy_to": "check_time_flatted"
,
"nu_check_addr":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"
这里必须强调的一点是:Nested 中元素的遍历非常“头痛”,“谁碰谁知道”。
所以这里通过“曲线救国“实现,将复杂的 Nested 数组问题借助 copy_to 拉平存储。
这点用过后会发现这个方案的巧妙之处。
思路参考:
https://stackoverflow.com/questions/64447956/how-to-iterate-through-a-nested-array-in-elasticsearch-with-filter-script

Nested 嵌套文档存储
Nested 嵌套文档建模推荐阅读:
Elasticsearch Nested 选型,先看这一篇!
干货 | Elasticsearch Nested类型深入详解
干货 | Elasticsearch Nested 数组大小求解,一网打尽!
5.2 Nested 写入数据
PUT nucleic_testing_infos_nested/_bulk
"index":"_id":1
"s_id_number":"910105197612304XXX","s_phone":"13655551111","s_name":"王小一","s_address":"京州市丰山区35号","s_wx_id":"wang_01","check_in":["nu_check_time":"2022-03-01T17:06:10Z","nu_check_addr":"京州市丰山区核酸检测001号站","nu_check_time":"2022-03-02T17:10:23Z","nu_check_addr":"京州市丰山区核酸检测002号站","nu_check_time":"2022-03-05T10:10:23Z","nu_check_addr":"京州市丰山区核酸检测002号站"]
"index":"_id":2
"s_id_number":"910105197612305XXX","s_phone":"13655552222","s_name":"张小二","s_address":"京州市海定区002号","s_wx_id":"zhang_02","check_in":["nu_check_time":"2022-03-02T17:10:33Z","nu_check_addr":"京州市丰山区核酸检测002号站","nu_check_time":"2022-03-28T17:15:28Z","nu_check_addr":"京州市丰山区核酸检测002号站"]
"index":"_id":3
"s_id_number":"910105197612303XXX","s_phone":"13655553333","s_name":"刘三","s_address":"京州市海定区003号","s_wx_id":"liu_03","check_in":["nu_check_time":"2022-03-02T17:15:01Z","nu_check_addr":"京州市海定区核酸检测站003号"]5.3 Nested 检索实现
POST nucleic_testing_infos_nested/_search
"query":
"bool":
"must": [
"script":
"script":
"lang": "painless",
"inline": """
int icount = 0;
int totalCount = 3;
String start_time = '2022-03-01T00:00:00Z';
String end_time = '2022-03-31T23:59:59Z';
ZonedDateTime start_zdt = ZonedDateTime.parse(start_time);
ZonedDateTime end_zdt = ZonedDateTime.parse(end_time);
long start_litmemills = start_zdt.toInstant().toEpochMilli();
long end_litmemills = end_zdt.toInstant().toEpochMilli();
for (item in doc['check_time_flatted'])
long litmemills = item.toInstant().toEpochMilli();
if(litmemills <= end_litmemills && litmemills >= start_litmemills)
icount++;
if(icount >= totalCount)
return true;
"""
]
检索的时候,基本就是照搬宽表数组的实现方案,不再赘述。
缺点:更新数据是更新的整篇文档,不是子文档独立更新。
而核酸检测的数据本质是:更新核酸检测时间信息,也就是只更新子文档就可以。
6、Join 父子文档实现
6.1 join 父子文档建模
DELETE nucleic_testing_infos_join
PUT nucleic_testing_infos_join
"mappings":
"properties":
"s_id_number":
"type": "keyword"
,
"s_phone":
"type": "keyword"
,
"s_name":
"type": "keyword"
,
"s_wx_id":
"type": "keyword"
,
"s_address":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"
,
"my_join_field":
"type": "join",
"relations":
"user": "nucleic_test"
,
"nu_check_time":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
,
"nu_check_addr":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"

Join 类型建模参考:Elasticsearch 6.X 新类型Join深入详解
6.2 Join 父子建模批量导入数据
PUT nucleic_testing_infos_join/_doc/1?refresh
"s_id_number": "910105197612304XXX",
"s_phone": "13655551111",
"s_name": "王小一",
"s_address": "京州市丰山区35号",
"s_wx_id": "wang_01",
"my_join_field":
"name": "user"
PUT nucleic_testing_infos_join/_doc/2?refresh
"s_id_number": "910105197612305XXX",
"s_phone": "13655552222",
"s_name": "张小二",
"s_address": "京州市海定区002号",
"s_wx_id": "zhang_02",
"my_join_field":
"name": "user"
PUT nucleic_testing_infos_join/_doc/3?refresh
"s_id_number": "910105197612303XXX",
"s_phone": "13655553333",
"s_name": "刘三",
"s_address": "京州市海定区003号",
"s_wx_id": "liu_03",
"my_join_field":
"name": "user"
PUT nucleic_testing_infos_join/_doc/4?routing=1
"nu_check_time": "2022-03-01 17:06:10",
"nu_check_addr": "京州市丰山区核酸检测001号站",
"my_join_field":
"name": "nucleic_test",
"parent": "1"
PUT nucleic_testing_infos_join/_doc/5?routing=1
"nu_check_time": "2022-03-02 17:10:23",
"nu_check_addr": "京州市丰山区核酸检测002号站",
"my_join_field":
"name": "nucleic_test",
"parent": "1"
PUT nucleic_testing_infos_join/_doc/6?routing=1
"nu_check_time": "2022-03-05 10:10:23",
"nu_check_addr": "京州市丰山区核酸检测002号站",
"my_join_field":
"name": "nucleic_test",
"parent": "1"
PUT nucleic_testing_infos_join/_doc/7?routing=2
"nu_check_time": "2022-03-02 17:10:33",
"nu_check_addr": "京州市丰山区核酸检测002号站",
"my_join_field":
"name": "nucleic_test",
"parent": "2"
PUT nucleic_testing_infos_join/_doc/8?routing=2
"nu_check_time": "2022-03-28 17:15:28",
"nu_check_addr": "京州市丰山区核酸检测002号站",
"my_join_field":
"name": "nucleic_test",
"parent": "2"
PUT nucleic_testing_infos_join/_doc/9?routing=3
"nu_check_time": "2022-03-02 17:15:01",
"nu_check_addr": "京州市海定区核酸检测站003号",
"my_join_field":
"name": "nucleic_test",
"parent": "3"
6.3 Join 父子建模检索
POST nucleic_testing_infos_join/_search
"query":
"has_child":
"type": "nucleic_test",
"min_children": 3,
"max_children": 10,
"query":
"range":
"nu_check_time":
"gte": "2022-03-01 00:00:00",
"lte": "2022-03-31 23:59:59"
父子文档的检索实现相比其他几种方案都要短不少。
实现方面有两个核心参数需要强调:
参数1:min_children, max_children 最小孩子数以及最大孩子数。这是7.X 版本才有的特性。方面统计父文档下子文档数量多少。
参数2:range 区间范围检索,用于过滤子文档的时间是否在检索要求的时间范围内。
7、 小结
除了MySQL 和 Elasticsearch,相关问题必然还会有其他实现方式,本文没有做全量覆盖。而仅就关系型数据库 MySQL 和 大数据全文检索引擎 Elasticsearch 为例展开讨论。
综上四种方案,父子文档相对灵活,应是选型中优先选择的。方案的对比如下:

如果有不同的建模建议,也欢迎留言交流讨论。
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
2、如何从0到1打磨一门 Elasticsearch 线上直播课?(口碑不错)

更短时间更快习得更多干货!
和全球近 1600+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
以上是关于用 Elasticsearch 统计做了几次核酸检测?怎么破?的主要内容,如果未能解决你的问题,请参考以下文章
复旦博士用130行代码搞定核酸统计,2分钟解决人工一小时工作量