核酸检测多少人为一组混检合适?
Posted 陆嵩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了核酸检测多少人为一组混检合适?相关的知识,希望对你有一定的参考价值。
今天在想一个有趣的问题。核酸检测的混检,必然是当患病率越低时,则混到一个管子的人数越多越好,因为这样检测的期望次数就会更少。那么问题来了,当患病率多高时,混检就失去了意义?当混检没失去意义时,检测多少次才会令期望的检测次数最低。
知乎上有人给出了这个问题的 答案。然而,这个答案我并不是非常地满意,他们只是考虑总人数比较多的时候,用样本概率去近似估计条件概率,有一定的近似成分在里面。能精确逼近的,为什么要用估计?我不喜欢这个。某种意义上来说,他们给出的答案是 “不对” 的。“不对” 加引号是因为,即使不对,在样本数足够大的情况下,几乎是对的。
来,我们来考虑一下这个问题。不妨假设总人数为 N N N,患病(敏感词汇,用患病替代)的人数为 M M M,假设混检的策略采用 k k k 个人一组进行混检,检出患病,这 k k k 个人则进行一次额外的检测。问,给定 N N N 和 M M M 的情况下,总的检测次数(期望意义下)和 k k k 是什么样的一个关系?为了方便,假设下述的所有相除数量关系都是可以整除的,这个不是重要的。
如果我们以所有人数作为考虑,计算他们总检测次数的期望,你会发现,它的检测次数出现的情况非常多,小到 N / k + k N/k+k N/k+k,大到 N / k + M k N/k+Mk N/k+Mk。而要计算每个次数出现的概率,要算很多组合数,非常麻烦。因为,我们不妨换一个角度,考虑每个人消耗检测次数的期望值,再把它乘以总人数 N N N,那么就得到这个整体的检测次数的期望。
对于一个人来说,他消耗的检测次数要么是
1
/
k
1/k
1/k,要么是
1
+
1
/
k
1+1/k
1+1/k,只有这两种情况,相对简单多了。
1
/
k
1/k
1/k 当且仅当他的这一组里面,没有人患病。它的概率是:
P
(
1
/
k
)
=
C
N
−
M
k
C
N
k
=
∏
i
=
0
k
−
1
N
−
M
−
i
N
−
i
P(1/k) = \\fracC_N-M^kC_N^k=\\prod_i=0^k-1\\fracN-M-iN-i
P(1/k)=CNkCN−Mk=i=0∏k−1N−iN−M−i
同理,只要这一管子里面有人患病,那么他消耗的检测次数就会变成
1
+
1
/
k
1+1/k
1+1/k。这种情况发生的概率为:
P
(
1
+
1
/
k
)
=
1
−
C
N
−
M
k
C
N
k
=
1
−
∏
i
=
0
k
−
1
N
−
M
−
i
N
−
i
.
P(1+1/k) = 1- \\fracC_N-M^kC_N^k=1-\\prod_i=0^k-1\\fracN-M-iN-i.
P(1+1/k)=1−CNkCN−Mk=1−i=0∏k−1N−iN−M−i.
那么,一个人的消耗的检测次数的数学期望为:
E
(
k
)
=
1
/
k
∗
P
(
1
/
k
)
+
(
1
+
1
/
k
)
∗
P
(
1
+
1
/
k
)
=
k
+
1
k
+
∏
i
=
0
k
−
1
M
−
N
+
i
N
−
i
E(k) = 1/k*P(1/k)+(1+1/k) *P(1+1/k) =\\frack+1k+\\prod_i=0^k-1\\fracM-N+iN-i
E(k)=1/k∗P(1/k)+(1+1/k)∗P(1+1/k)=kk+1+i=0∏k−1N−iM−N+i
MMP,这个似乎没办法再化简。不是我不行,我用 MATLAB 符号计算试了一下,确实没法化简。用到的代码如下:
clc
clear
close all
syms N M
k = 5;
Pk1 = 1;
for i = 0:k-1
Pk1 = Pk1*(N-M-i)/(N-i);
end
Pk1_ = 1-Pk1;
E = 1/k*Pk1+(1+1/k)*Pk1_;
Esim = simplify(E)
Efac = factor(Esim);
latex(Esim)
latex(Efac)
那么,总的检测次数的数学期望就是 N ∗ E ( k ) N*E(k) N∗E(k),一般我们考虑 E ( k ) E(k) E(k) 就可以了。我们用两种方法来验证一下这个结果,第一个方法是找一些简单的值和手算做对比,第二个方法是用程序做一个大数据量下的仿真。
当 M = 1 M=1 M=1, N = 4 N=4 N=4, k = 2 k=2 k=2 时, N ∗ E ( k ) = 4 N*E(k)=4 N∗E(k)=4,和我们手算的结果一样。所用到的程序如下。
NE(M,N) = N*E;
NEfun = matlabFunction(NE);
NEfun(2,6)
当 M = 2 M=2 M=2, N = 6 N=6 N=6, k = 3 k=3 k=3 时, N ∗ E ( k ) = 6.8 N*E(k)=6.8 N∗E(k)=6.8,和我们手算的结果 6.5 不一样。手算的过程为, 6 6 6 个人两组,至少要做两次。两个患病的进入一个管子的概率如同时抛两枚硬币,硬币朝向是相同的概率为 0.5。故而,有 0.5 的可能要多做 3 次,有另外 0.5 的可能要多做 6 次。一次总的次数 2 + 3 ∗ 0.5 + 6 ∗ 0.5 = 6.5 2+3*0.5+6*0.5 = 6.5 2+3∗0.5+6∗0.5=6.5。
这里的结果发生了不一致,到底是谁对谁错呢?让我们用程序仿真来模拟一下。
clc
clear
close all
M = 2;
N = 6;
k = 3;
Ms = 1:M;
s = 0;
NN = 1000000;
N_k = N/k;
for ii=1:NN
R = reshape(randperm(N),k,[]);
res = 0;
for i=1:N_k
if(intersect(R(:,i),Ms)>0)
res = res+1;
end
end
s = s+res*k+N_k;
s/ii
end
模拟的结果是 6.8,说明我们手算的那个思路是不对的,我来看看为什么。其实很简单,2个管子,6 个人,每个管子 3 个人,2 个患病的人进入同一个管子的概率不是 1/2,而是 1 / 2 ∗ 2 / 5 ∗ 2 = 2 / 5 1/2*2/5*2=2/5 1/2∗2/5∗2=2/5。这个和抛硬币是不一样的,仔细想想就知道了,这里不再赘述。一言以蔽之,抛硬币没有一管三人的约束,是不一样的。
接下来,我们来看一下,在
M
M
M 和
N
N
N 固定的情况下,
E
E
E 和
k
k
k 是什么样一个限制关系,以及
E
(
k
)
E(k)
E(k) 的极值点在哪。上面的论述都是基于
k
>
1
k>1
k>1 的时候,当
k
=
1
k=1
k=1 的时候,因为就一个人,即使测出患病,也没必要再测一次。所以,需要对公式做一个修正。考虑
E
(
k
)
=
k
+
1
k
+
∏
i
=
0
k
−
1
M
−
N
+
i
N
−
i
,
k
>
1
E
(
k
)
=
1
,
k
=
1.
E(k) =\\frack+1k+\\prod_i=0^k-1\\fracM-N+iN-i,k>1\\\\ E(k) =1,k=1.
E(k)=kk+1+i=0∏k−1N−iM−N+i,k>1E(k)=1,k=1.
事实上,
E
E
E 关于
k
k
k 求导
E
′
(
k
)
E'(k)
E′(k) 是一件非常麻烦的事情,不是初等数学可以做的。所以,我们寄希望于用 MATLAB 画一下图,再看看结果。为了把细节看清楚,我分了两张图画。
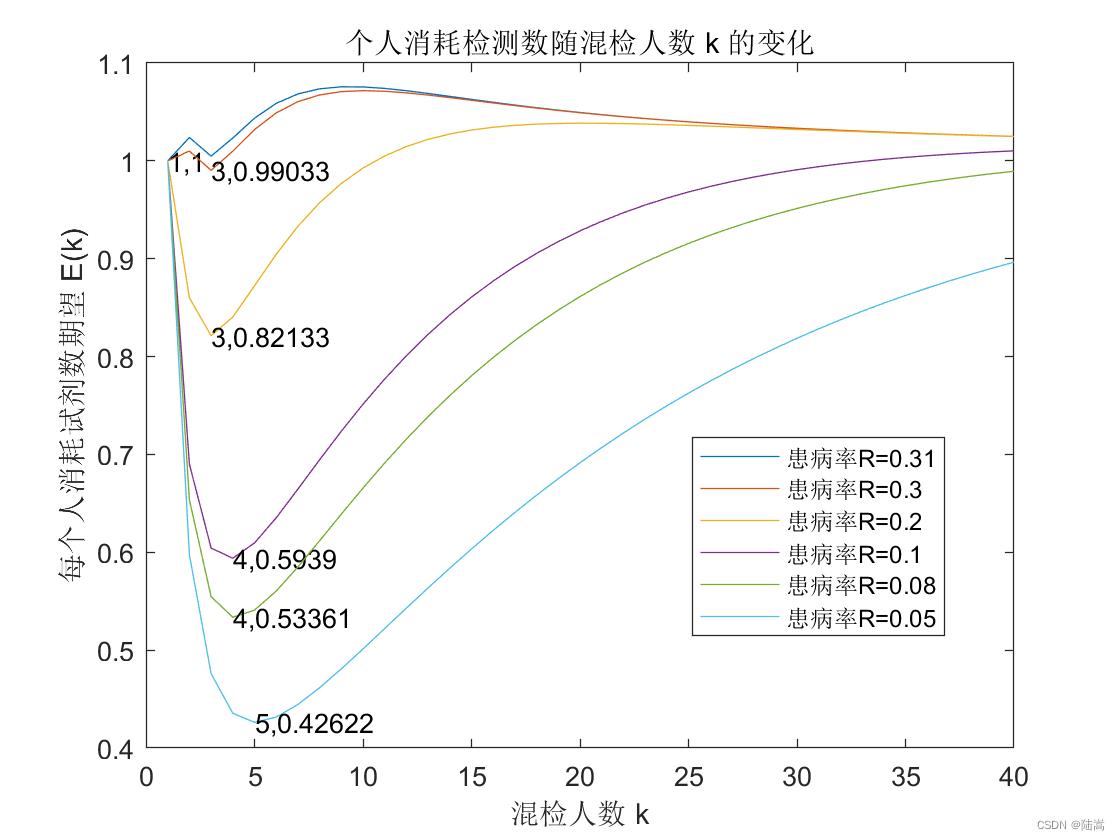
从图上可以看得出来,当患病率高于 0.3 的时候,就已经不适合混检了。
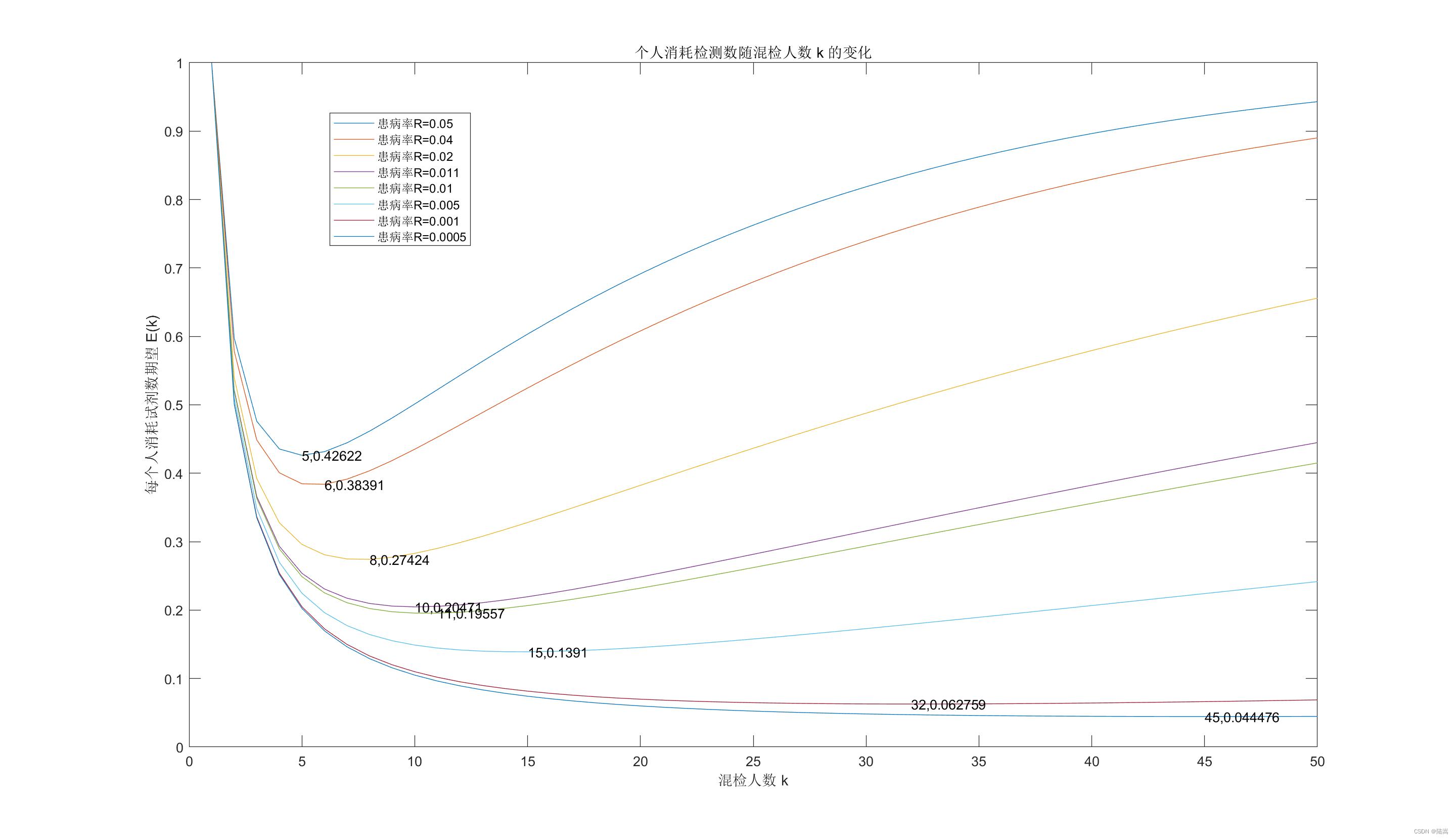
可以看得出来,患病率越低,可以达到的极值点越小。且随着
k
k
k 的增加,
E
(
k
)
E(k)
E(k) 先减后增,最后总是趋向于 1 的。当患病率低到 0.01 左右的时候,差不多 10 个人混检是比较合理的。
clc;clear;close all;
Rs = [0.05 0.04 0.02 0.011 0.01 0.005 0.001 0.0005];
%Rs = 4/100000;
for R = Rs
N = 40000000000000;
M = round(N*R);
K = 50;
for k=1:K
y(k) = E(N,M,k);
end
plot(1:K,y);
title('个人消耗检测数随混检人数 k 的变化')
xlabel('混检人数 k')
ylabel('每个人消耗试剂数期望 E(k)')
hold on;
[val,ind] = min(y);
text_points(i以上是关于核酸检测多少人为一组混检合适?的主要内容,如果未能解决你的问题,请参考以下文章