搭建Hadoop分布式集群的详细教程
Posted 程序员小木
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搭建Hadoop分布式集群的详细教程相关的知识,希望对你有一定的参考价值。
目录
三、克隆集群节点HadoopSlave1与HadoopSlave2
一、创建虚拟机,安装Centos
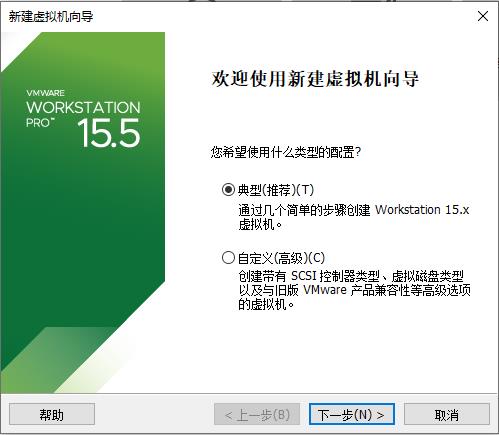
步骤一 新建虚拟机

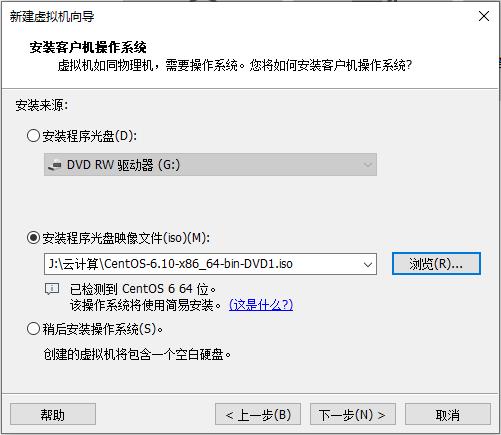
步骤二 设置CentOS光盘镜像文件(ISO)
步骤三 填写用户信息(设为hadoop)

步骤四 命名虚拟机

步骤五 设置磁盘容量

步骤六 自定义硬件,完成虚拟机创建


步骤七 开始启动虚拟机,并安装CentOS

步骤八 安装完成,登录系统:

二、VMware VMnet8模式共享主机网络配置
NAT网络模式:
- 宿主机可以看做一个路由器,虚拟机通过宿主机的网络来访问 Internet;
- 可以安装多台虚拟机,组成一个小型局域网,例如:搭建 hadoop 集群、分布式服务。
步骤一 VMnet8 设置静态 IP

步骤二 Centos 网络设配器为 NAT 模式
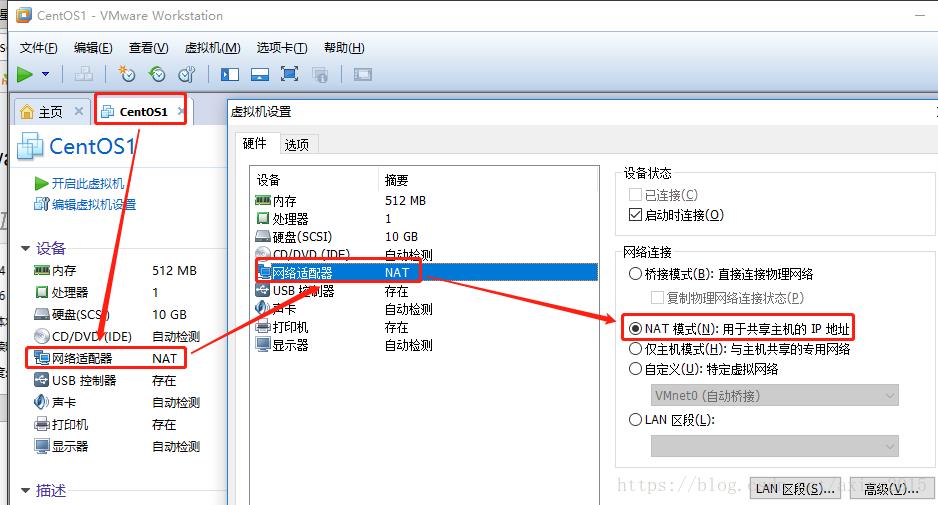
步骤三 VMware 虚拟网络设置

步骤四 启动虚拟机

步骤五 修改网络设置

步骤六 验证结果
# ping www.baidu.com

三、克隆集群节点HadoopSlave1与HadoopSlave2
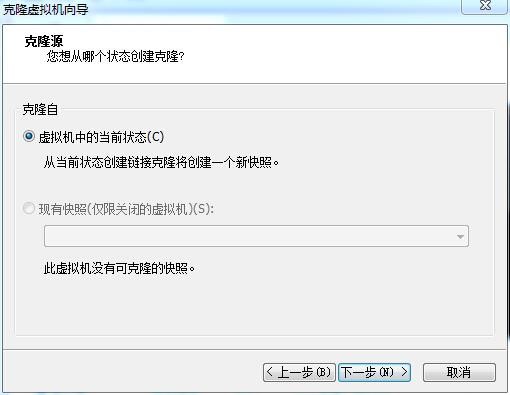
步骤一 关闭HadoopMaster服务器,在该节点单击鼠标右键,选择【管理】-【克隆】选项

步骤二 克隆虚拟机向导
步骤三 创建完整克隆
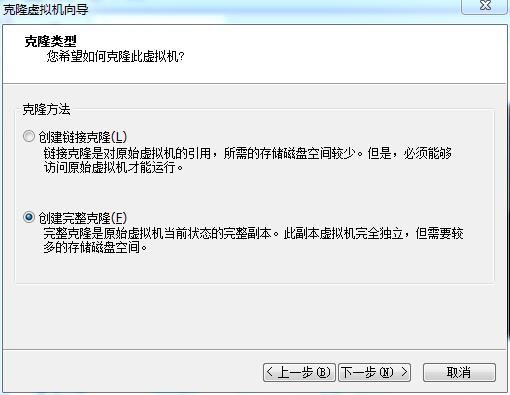
步骤四 将虚拟机重命名为HadoopSlave1,并选择一个存储位置
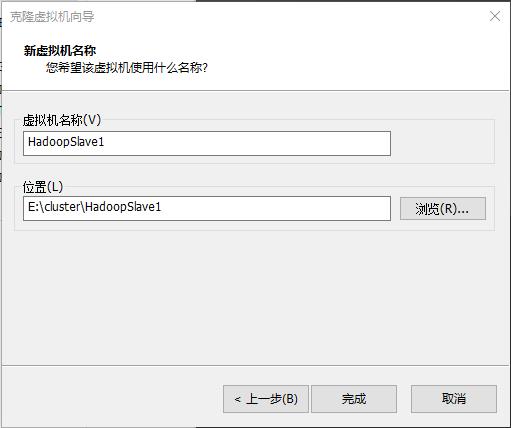
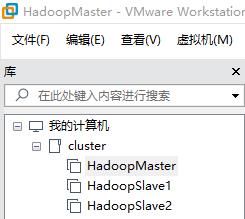
步骤五 克隆虚拟机重命名为HadoopSlave2,完成Hadoop分布式集群的虚拟硬件环境搭建
四、Linux系统配置
步骤一 配置时钟同步
安装crontab:
yum install vixie-cron
yum install crontabs说明: vixie-cron软件包是cron的主程序;crontabs软件包是用来安装、卸装、或列举用来驱动 cron 守护进程的表格的程序。cron 是linux的内置服务,但它不自动起来,可以用以下的方法启动、关闭这个服务:
/sbin/service crond start //启动服务
/sbin/service crond stop //关闭服务
/sbin/service crond restart //重启服务
/sbin/service crond reload //重新载入配置查看crontab服务状态:
service crond status手动启动crontab服务:
service crond start用户可通过crontab来设置自己的计划任务,并使用-e参数来编辑任务。在这之前需要先了解一下设置的“语法”,当使用crontab-e进入编辑模式时,需要编辑执行的时间和执行的命令。在下面的格式中,前面5个*可以用来定义时间,第一个*表示分钟,可以使用的值是1~59,每分钟可以使用*和*/1表示;第二个*表示小时,可以使用的值是0~23;第三个*表示日期,可以使用的值是1~31;第四个*表示月份,可以使用的值是1~12;第五个*表示星期几,可以使用的值是0~6,0代表星期日;最后是执行的命令。当到了设定的时间时,系统就会自动执行定义好的命令,设置crontab的基本格式如下所示。
# +---------------- minute 分钟(0 - 59)
# | +------------- hour 小时(0 - 23)
# | | +---------- day 日期(1 - 31)
# | | | +------- month 月份(1 - 12)
# | | | | +---- week 星期(0 - 7) (星期天=0 or 7)
# | | | | |
# * * * * * 要运行的命令
(1)配置自动时钟同步
0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
或者
0 1 * * * /usr/sbin/ntpdate aliyun.com
(2)手动时间同步
/usr/sbin/ntpdate cn.pool.ntp.org
或者
/usr/sbin/ntpdate cn.pool.ntp.org

步骤二 配置主机名
在计算机网络中,能够唯一标识主机的是它自己的IP地址,而每台主机都有一个网络的主机名,它跟IP地址的作用是一样的。通过IP地址或者网络主机名,都可以访问这台主机。HadoopMaster、HadoopSlave1和HadoopSlave2都不是它们各自的网络主机名,这3台的网络主机名默认都是LOCALHOST。它们的名字是重复的,因为这是它们的默认网络主机名。此时,不可能单从名字上区分这3台主机,因此,需要改变这3台主机的名称,根据集群的架构来命名。将这三台主机分别命名为master、slave1和slave2。
以root用户身份登录HadoopMaster节点,直接使用vim编辑器打开network网络配置文件,命令如下:
vim /etc/sysconfig/network
打开network文件,配置信息如下,将HadoopMaster节点的主机名修改为master,即下面第二行代码所示:
NETWORKING=yes #启动网络
HOSTNAME=master #主机名按Esc键,输入:wq保存退出。
确认修改生效,命令如下:
hostname master在操作之前要关闭当前的终端,重新打开一个终端:
hostname
HadoopSlave1和HadoopSlave2节点也同样修改
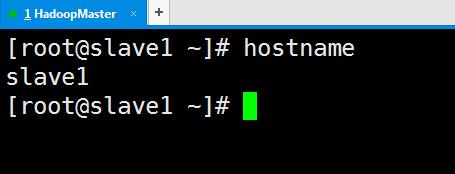
步骤三 配置HadoopSlave1和HadoopSlave2网络环境,并关闭三台主机的防火墙
HadoopSlave1

HadoopSlave2

防火墙是计算机系统中位于内部网络与外部网络之间的一道防线。任何计算机操作系统都有防火墙,它依照特定的规则,允许或限制传输的数据通过。分布式集群环境中,每个节点的防火墙若不关闭,那么集群中节点之间就会受到防火墙的阻碍,无法进行通信。在分布式集群中,各个节点之间的通信,即数据同步,是频繁发生的,如果每个节点都有防火墙,那么势必会造成通信成本的大大增加,不利于集群的分布式存储和计算。
基于这样的原因,一般会将分布式集群环境中各个节点的防火墙全部关闭。
步骤四 配置Hosts列表
主机列表的作用是让集群中的每台服务器彼此之间都知道对方的主机名和IP地址。因为在Hadoop分布式集群中,各服务器之间会频繁通信,做数据的同步和负载均衡。
以root用户身份登录三个节点,将下面3行代码添加到主机列表/etc/hosts 文件中。
192.168.40.128 master
192.168.40.129 slave1
192.168.40.130 slave2验证主机hosts是否配置成功
ping master
ping slave1
ping slave2步骤五 安装JDK
JDK(Java SE Development Kit)是Java的开发工具箱,是整个Java的核心,包括了Java运行环境、Java工具和Java基础类库,Hadoop分布式集群的程序是用Java语言开发出来的,所以,Hadoop分布式集群要正常运行,必需要有Java运行时的环境。
将jdk-7u79-linux-x64.tar.gz复制到新建的/usr/java 目录下解压,修改用户的系统环境变量文件/home/hadoop/.bash_profile,
export JAVA_HOME=/usr/java/jdk1.7.0_79
export JRE_HOME=/usr/java/jdk1.7.0_79/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$JRE_HOME/bin:$JAVA_HOME/bin:$PATH通过source/home/hadoop/.bash_profile使命令生效,验证JDK安装是否成功及环境变量是否配置成功,打开Terminal终端,输入命令javac

说明节点上hadoop用户的JDK环境变量配置成功。
步骤六 免密钥登录配置
免密钥登录是指从一台节点通过SSH方式登录另外一台节点时,不用输入该节点的用户名和密码,就可以直接登录进去,对其中的文件内容直接进行操作。没有任何校验和拦截。
从root用户切换到hadoop用户,输入su hadoop,在终端生成密钥,输入以下命令:
ssh-keygen –t rsassh-keygen是生成密钥的命令;-t rsa表示使用rsa算法进行加密。

生成的密钥在/home/hadoop/.ssh/目录下,私钥为id_rsa,公钥为id_rsa.pub
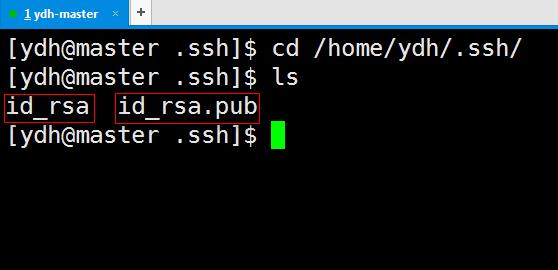
复制公钥文件到authorized_keys文件中,命令如下:
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
修改authorized_keys文件的权限,只有当前用户hadoop有权限操作authorized_keys文件,命令如下:
chmod 600 /home/hadoop/.ssh/authorized_keys
将HadoopMaster主节点生成的authorized_keys公钥文件复制到HadoopSlave1和HadoopSlave2从节点,命令如下:
scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:/home/ydh/.ssh/
scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:/home/ydh/.ssh/如果出现提示,则输入yes并按回车键,输入密码,这里密码是hadoop。
此时,HadoopMaster节点的公钥文件信息就被复制到HadoopSlave1和HadoopSlave2节点上了。
以hadoop用户身份登录HadoopSlave1、HadoopSlave2节点,进入到/home/hadoop/.ssh目录,修改authorized_keys文件的权限为当前用户可读可写,输入以下命令:
chmod 600 /home/hadoop/.ssh/authorized_keys此时,在HadoopSlave1、HadoopSlave2节点上就存放了HadoopMaster节点的公钥,那么HadoopMaster节点就可以以SSH方式直接登录HadoopSlave1、HadoopSlave2节点。验证免密钥登录,在HadoopMaster节点的Terminal终端上输入以下命令验证免密钥登录。
[hadoop@master ~]$ ssh slave1
Last login: Sat Feb 1 01:23:58 2020 from slave1
[hadoop@slave1 ~]$ exit
logout
Connection to slave1 closed.
[hadoop@master ~]$ ssh slave2
Last login: Fri Jan 31 09:23:24 2020 from slave1
[hadoop@slave2 ~]$ exit
logout
Connection to slave2 closed.
[hadoop@master ~]$
五、Hadoop的部署配置
步骤一 解压Hadoop安装文件
将Hadoop安装文件通过SSH工具上传到HadoopMaster节点hadoop用户的主目录下。进入hadoop用户主目录,输入以下命令进行解压:
tar –zxvf hadoop-2.5.2.tar.gz步骤二 配置环境变量hadoop-env.sh
打开Hadoop的环境变量文件,只需要配置JDK的路径。
vim /home/hadoop/hadoop-2.5.2/etc/hadoop/hadoop-env.sh在文件靠前的部分找到以下代码:
export JAVA_HOME=$JAVA_HOME将这行代码修改为:
export JAVA_HOME=/usr/java/jdk1.7.0_79保存文件,此时Hadoop具备了运行时的环境。
步骤三 配置环境变量yarn-env.sh
YARN主要负责管理Hadoop集群的资源。这个模块也是用Java语言开发出来的,所以也要配置其运行时的环境变量JDK。
打开Hadoop的YARN模块的环境变量文件yarn-env.sh,只需要配置JDK的路径。
vim /home/hadoop/hadoop-2.5.2/etc/hadoop/yarn-env.sh
在文件靠前的部分找到以下代码:
#export JAVA_HOME
将这行代码修改为:
export JAVA_HOME=/usr/java/jdk1.7.0_79保存文件,此时Hadoop的YARN模块具备了运行时的环境。
步骤四 配置核心组件core-site.xml
Hadoop集群的核心配置,是关于集群中分布式文件系统的入口地址和分布式文件系统中数据落地到服务器本地磁盘位置的配置。
分布式文件系统(Hadoop Distributed FileSystem,HDFS)是集群中分布式存储文件的核心系统,将在后面章节详细介绍,其入口地址决定了Hadoop集群架构的主节点,其值为hdfs://master:9000,协议为hdfs,主机为master,即HadoopMaster节点,端口号为9000。
打开Hadoop的核心配置文件core-site.xml。
vim /home/hadoop/hadoop-2.5.2/etc/hadoop/core-site.xml
在<!-- Put site-specific property overrides in this file. -->下方,输入
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoopdata</value>
</property>
</configuration>HDFS文件系统数据落地到本地磁盘的路径信息/home/hadoop/hadoopdata,该目录需要单独创建。
步骤五 配置文件系统hdfs-site.xml
在分布式的文件系统中,由于集群规模很大,所以集群中会频繁出现节点宕机的问题。分布式的文件系统中,可通过数据块副本冗余的方式来保证数据的安全性,即对于同一块数据,会在HadoopSlave1和HadoopSlave2节点上各保存一份。这样,即使HadoopSlave1节点宕机导致数据块副本丢失,HadoopSlave2节点上的数据块副本还在,就不会造成数据的丢失。
配置文件hdfs-site.xml有一个属性,就是用来配置数据块副本个数的。在生产环境中,配置数是3,也就是同一份数据会在分布式文件系统中保存3份,即它的冗余度为3。也就是说,至少需要3台从节点来存储这3份数据块副本。在Hadoop集群中,主节点是不存储数据副本的,数据的副本都存储在从节点上,由于现在集群的规模是3台服务器,其中从节点只有两台,所以这里只能配置成1或者2。
打开hdfs-site.xml配置文件。
vim /home/hadoop/hadoop-2.5.2/etc/hadoop/hdfs-site.xml
在<!-- Put site-specific property overrides in this file. --> 下方,输入
<configuration>
<property>
<!--配置数据块的副因子(即副本数)为2-->
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>步骤六 配置YARN资源系统yarn-site.xml
YARN的全称是Yet Another Resource Negotiator,即另一种资源协调者,运行在主节点上的守护进程是ResourceManager,负责整个集群资源的管理协调;运行在从节点上的守护进程是NodeManager,负责从节点本地的资源管理协调。
YARN的基本工作原理:每隔3秒,NodeManager就会把它自己管理的本地服务器上的资源使用情况以数据包的形式发送给主节点上的守护进程ResourceManager,这样,ResourceManager就可以随时知道所有从节点上的资源使用情况,这个机制叫“心跳”。当“心跳”回来的时候,ResourceManager就会根据各个从节点资源的使用情况,把相应的任务分配下去。“心跳”回来时,携带了ResourceManager分配给各个从节点的任务信息,从节点NodeManager就会处理主节点ResourceManager分配下来的任务。客户端向整个集群发起具体的计算任务,ResourceManager是接受和处理客户端请求的入口。
打开yarn-site.xml配置文件。
vim /home/hadoop/hadoop-2.5.2/etc/hadoop/yarn-site.xml
在<!-- Site specific YARN configuration properties -->下方,输入
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>yarn.nodemanager.aux-services是NodeManager上运行的附属服务,其值需要配置成mapreduce_shuffle,才可以运行MapReduce程序。
yarn.resourcemanager.address 是ResourceManager对客户端暴露的访问地址,客户端通过该地址向ResourceManager提交或结束MapReduce应用程序。
yarn.resourcemanager.scheduler.address是ResourceManager对ApplicationMaster(客户端将MapReduce应用程序提交到集群中,ResourceManager接受客户端应用程序的提交后,将该应用程序分配给某一个NodeManager,对该MapReduce应用程序进行初始化,进而产生一个应用程序初始化Java对象,将这个Java对象称为ApplicationMaster)暴露的访问地址,ApplicationMaster通过该地址向ResourceManager申请MapReduce应用程序在运行过程中所需要的资源,以及程序运行结束后对使用资源的释放等。
yarn.resourcemanager.resource-tracker.address 是ResourceManager对NodeManager暴露的访问地址,NodeManager通过该地址向ResourceManager发送心跳数据,汇报资源使用情况以及领取ResourceManager将要分配给自己的任务等。
yarn.resourcemanager.admin.address 是ResourceManager对管理员admin暴露的访问地址,管理员可通过该地址向ResourceManager发送管理命令等。
yarn.resourcemanager.webapp.address 是ResourceManager YARN平台提供用户查看正在运行的MapReduce程序的进度和状态的WEB UI系统的访问地址,可通过该地址在浏览器中查看应用程序的运行状态信息。
步骤七 配置计算框架mapred-site.xml
YARN主要负责分布式集群的资源管理,将Hadoop MapReduce分布式并行计算框架在运行中所需要的内存、CPU等资源交给YARN来协调和分配,通过对mapred-site.xml配置文件的修改来完成这个配置。
通过以下命令打开mapred-site.xml配置文件。
vim /home/hadoop/hadoop-2.5.2/etc/hadoop/mapred-site.xml
在<!-- Put site-specific property overrides in this file. -->下方,输入
<configuration>
<!—MapReduce计算框架的资源交给YARN来管理-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>步骤八 在HadoopMaster配置slaves,复制hadoop到从节点。
主节点的角色HadoopMaster已在配置HDFS分布式文件系统的入口地址时进行了配置说明,从节点的角色也需要配置,此时,slaves文件就是用来配置Hadoop集群中各个从节点角色。
打开slaves配置文件。
vim /home/hadoop/hadoop-2.5.2/etc/hadoop/slaves
用下面的内容替换slaves文件中的内容:
slave1
slave2在Hadoop集群中,每个节点上的配置和安装的应用都是一样的,这是分布式集群的特性,所以,此时已经在HadoopMaster节点上安装了Hadoop-2.5.2的应用,只需要将此应用复制到各个从节点(即HadoopSlave1节点和HadoopSlave2节点)即可将主节点的hadoop复制到从节点上。
scp –r /home/hadoop/hadoop-2.5.2 ydh@slave1:~/
scp –r /home/hadoop/hadoop-2.5.2 ydh@slave2:~/步骤九 配置Hadoop启动的系统环境变量
和JDK的配置环境变量一样,也要配置一个Hadoop集群的启动环境变量PATH。此配置需要同时在HadoopMaster、HadoopSlave1和HadoopSlave2上进行操作,操作命令如下:
vim /home/hadoop/.bash_profile
将下面的代码追加到.bash_profile文件的末尾:
#Hadoop Path configuration
export HADOOP_HOME=/home/hadoop/hadoop-2.5.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH输入:wq保存退出,并执行生效命令:
source /home/hadoop/.bash_profile
登录HadoopSlave1和HadoopSlave2节点,依照上述配置方法,配置Hadoop启动环境变量。
步骤十 配置数据目录
HDFS分布式文件系统存储数据最终落地到各个数据节点上的本地磁盘位置信息/home/hadoop/hadoopdata,该目录是需要自己创建的。
要在HadoopMaster、HadoopSlave1和HadoopSlave2上分别创建数据目录/home/hadoop/ hadoopdata。
mkdir /home/hadoop/hadoopdata六、Hadoop集群的启动
步骤一 格式化文件系统
启动集群时,首先要做的就是在HadoopMaster节点上格式化分布式文件系统HDFS:
hdfs namenode –format步骤二 启动Hadoop
Hadoop是主从架构,启动时由主节点带动从节点,所以启动集群的操作需要在主节点HadoopMaster完成,命令如下:
cd /home/hadoop/hadoop-2.5.2
sbin/start-all.sh
执行命令后,在提示处输入yes
步骤三 查看进程是否启动
在HadoopMaster的Terminal终端执行jps命令,在打印结果中会看到4个进程,分别是ResourceManager、Jps、NameNode和SecondaryNameNode。
在HadoopSlave的终端执行jps命令,在打印结果中会看到3个进程,分别是NodeManager、DataNode和Jps。


表示主、从节点进程启动成功。
步骤四 Web UI查看集群是否成功启动
在HadoopMaster上启动Firefox浏览器,在浏览器地址栏中输入http://master:50070/,检查NameNode和DataNode是否正常;在浏览器地址栏中输入http://master:18088/,检查YARN是否正常。

步骤五 运行PI实例检查集群是否启动成功
在HadoopMaster节点上,进入hadoop安装主目录,执行下面的命令:
cd hadoop-2.5.2/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.5.1.jar pi 10 10
最后输出为:
Estimated value of Pi is 3.20000000000000000000

至此,hadoop分布式集群搭建完成。
以上是关于搭建Hadoop分布式集群的详细教程的主要内容,如果未能解决你的问题,请参考以下文章