[机器学习与scikit-learn-6]:数据集获取的主要方式-2-计算机生成数据集
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习与scikit-learn-6]:数据集获取的主要方式-2-计算机生成数据集相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123238517
目录
2.3 案例2:生成分类数据:make_classification
2.4 案例4: 生成回归数据:make_regression
第1章 scikit-learn数据获取的主要方式
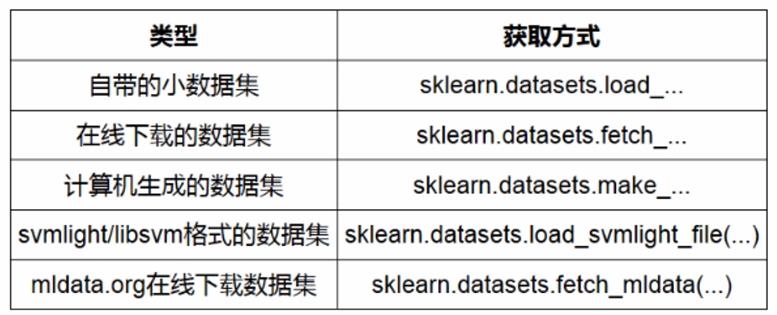
自带的小数据集:安装后,这些数据集一并安装,xxx.load_xxx()
在线下载的数据集:下载远程数据集
计算机生成的数据集:通过某种数学算法,生成数据集
svmlight/svm格式的数据集: 从文件冲去数据集
mldata.org: 在线下载由mldata.org提供的大型数据集
第2章 计算机自动生成数据集
2.1 概述
有时候,我们在调试和训练模型时,没有真实的数据,为了能够调试和验证模型,有时候我们需要手工生成模拟数据,scikit-learn提供了API, 用于自动生成指定特征的数据集(模拟数据集)。
自动生成数据集的好处有:
- 非常灵活:可以控制样本数量,特征数量,类别数量,问题难易程度等等。。。
- 无穷无尽:再也不用担心我没有数据集了。。
- 为算法提供模拟数据
2.2 常见的生成函数
- make_blobs 可用于聚类和分类
- make_classification 可用于分类
- make_circles 可用于分类
- make_moons 可用于分类
- make_multilabel_classification 可用于多标签分类
- make_regression 可用于回归
2.3 案例1:生成聚类数据:make_blobs
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib
# 生成数据 make_blobs
from sklearn.datasets import make_blobs# 生成数据集
# n_samples:样本总数
# centers:中心点坐标,与分类数一致
# n_features:分类数
# cluster_std:正态分布的标准方差
# random_state:随机种子,确保每次运行,生成的随机数是一样的
X, labels=make_blobs(n_samples=200,centers=[[1,1],[-1,-1],[1,-1]], n_features=2, cluster_std=0.3, random_state = 0)
# 生成的数据集,自动带上标签
print('X.shape',X.shape)
print("labels",labels.shape)
# 分类的类型汇总
print("labels",set(labels))X.shape (200, 2) labels (200,) labels 0, 1, 2
# 通过pandas可视化数据
df = pd.DataFrame(np.c_[X,labels],columns = ['feature1','feature2','labels'])
df.plot.scatter('feature1','feature2', s = 100, c = list(df['labels']), cmap = 'rainbow',colorbar = False, alpha = 0.8,title = 'dataset by make_blobs')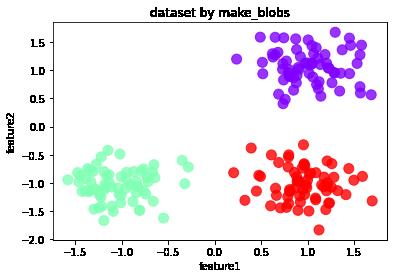
备注:生成成块聚合数据
2.3 案例2:生成分类数据:make_classification
#生成数据集 make_classification
from sklearn.datasets import make_classification
# n_samples:样本数
# n_features:特征数目
# n_classes:分类数目
# n_redundant:冗余数
X,labels=make_classification(n_samples=300,n_features=2, n_classes = 2, n_redundant=0, n_informative=2, random_state=0, n_clusters_per_class=2)
print(X.shape)
print(labels.shape)
print(set(labels))(300, 2) (300,) 0, 1
df = pd.DataFrame(np.c_[X, labels],columns = ['feature1','feature2','labels'])
df['labels'] = df['labels'].astype('i2')
df.plot.scatter('feature1','feature2', s = 100, c = list(df['labels']),cmap = 'rainbow',colorbar = False,alpha = 0.8,title = 'dataset by make_classification')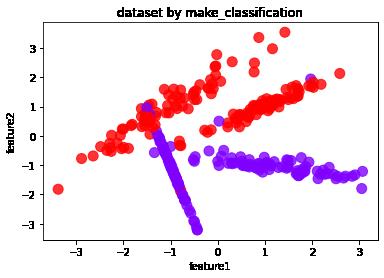
2.3 案例3:生成环形数据:make_circles
#生成数据集 make_circles
from sklearn.datasets import make_circles
X,labels=make_circles(n_samples=200,noise=0.2,factor=0.2,random_state=1)
print("X.shape:",X.shape)
print("labels:",set(labels))X.shape: (200, 2) labels: 0, 1
df = pd.DataFrame(np.c_[X,labels],columns = ['feature1','feature2','labels'])
df['labels'] = df['labels'].astype('i2')
# 生成圆周数据
df.plot.scatter('feature1','feature2', s = 100, c = list(df['labels']),cmap = 'rainbow',colorbar = False, alpha = 0.8,title = 'dataset by make_circles')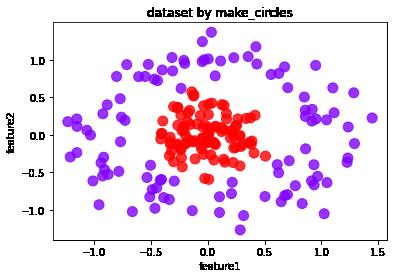
2.4 案例4: 生成回归数据:make_regression
# 生成数据集 make_regression
from sklearn.datasets import make_regression
# 生成数据集
# n_samples:样本个数
# n_features:输入数据的维度,这里是1维x轴
# n_targets:输出数据的维度,这里是1为y轴
# bias:数据偏置大小
# noise:叠加的噪声大小
# random_state:随机种子
X,Y,coef = make_regression(n_samples=100, n_features=1, n_informative=1, n_targets=1, bias=5, effective_rank=None, tail_strength= 0, noise= 10, shuffle=True, coef=True, random_state=None)
print("X.shape:",X.shape)
print("Y.shape:",Y.shape)X.shape: (100, 1) Y.shape: (100,)
X.shape: (100, 1)
Y.shape: (100,)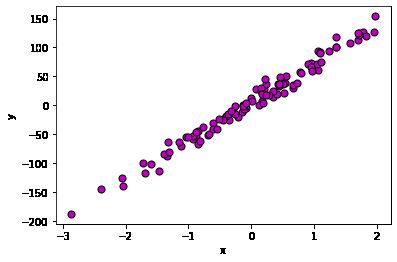
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123238517
以上是关于[机器学习与scikit-learn-6]:数据集获取的主要方式-2-计算机生成数据集的主要内容,如果未能解决你的问题,请参考以下文章