TensorFlow by Google Machine Learning Foundations: Ep #8 - Tokenization for Natural Language Process
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow by Google Machine Learning Foundations: Ep #8 - Tokenization for Natural Language Process相关的知识,希望对你有一定的参考价值。
机器学习基础:第 8 集 - 自然语言处理的标记化





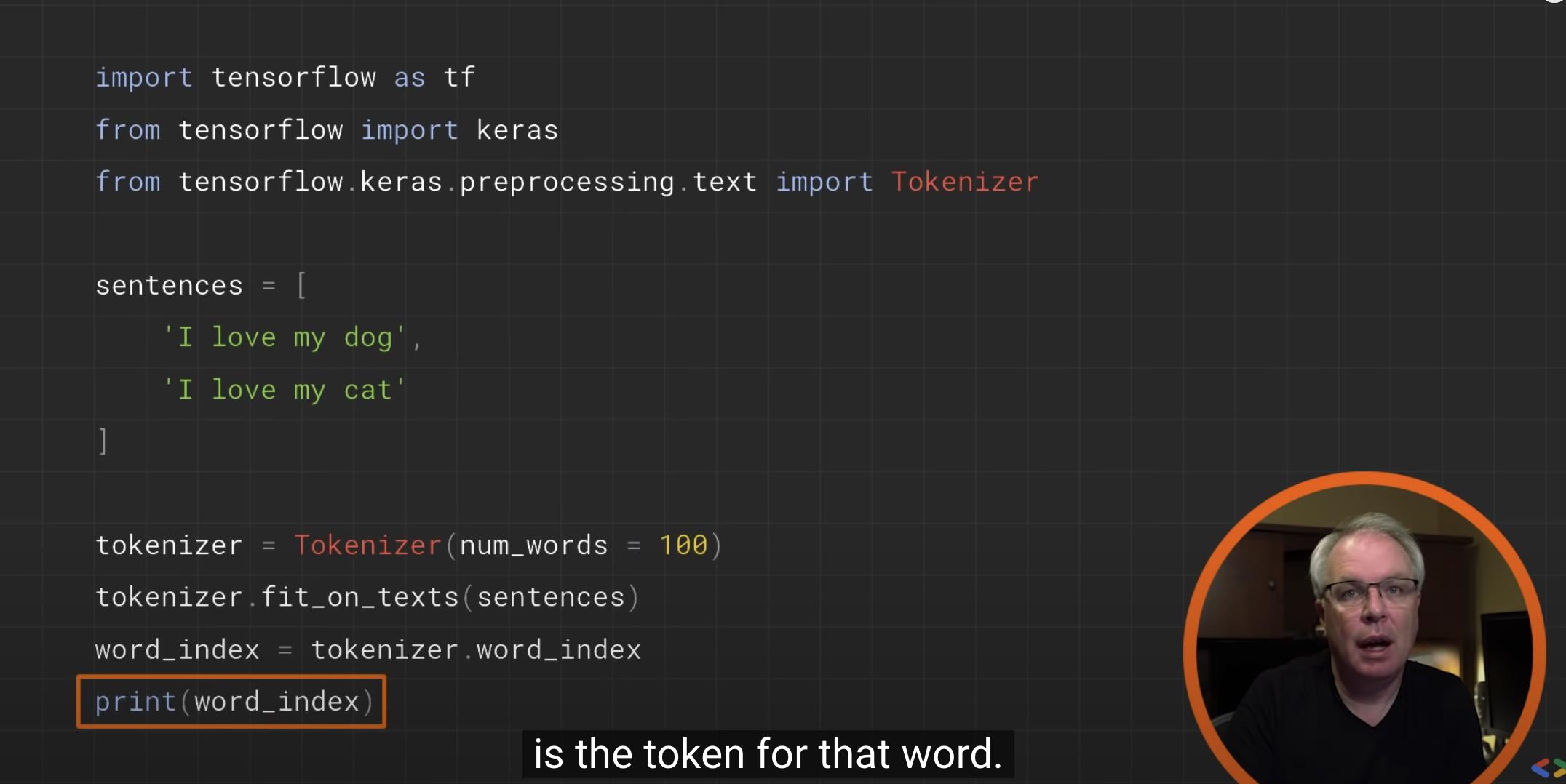



练习
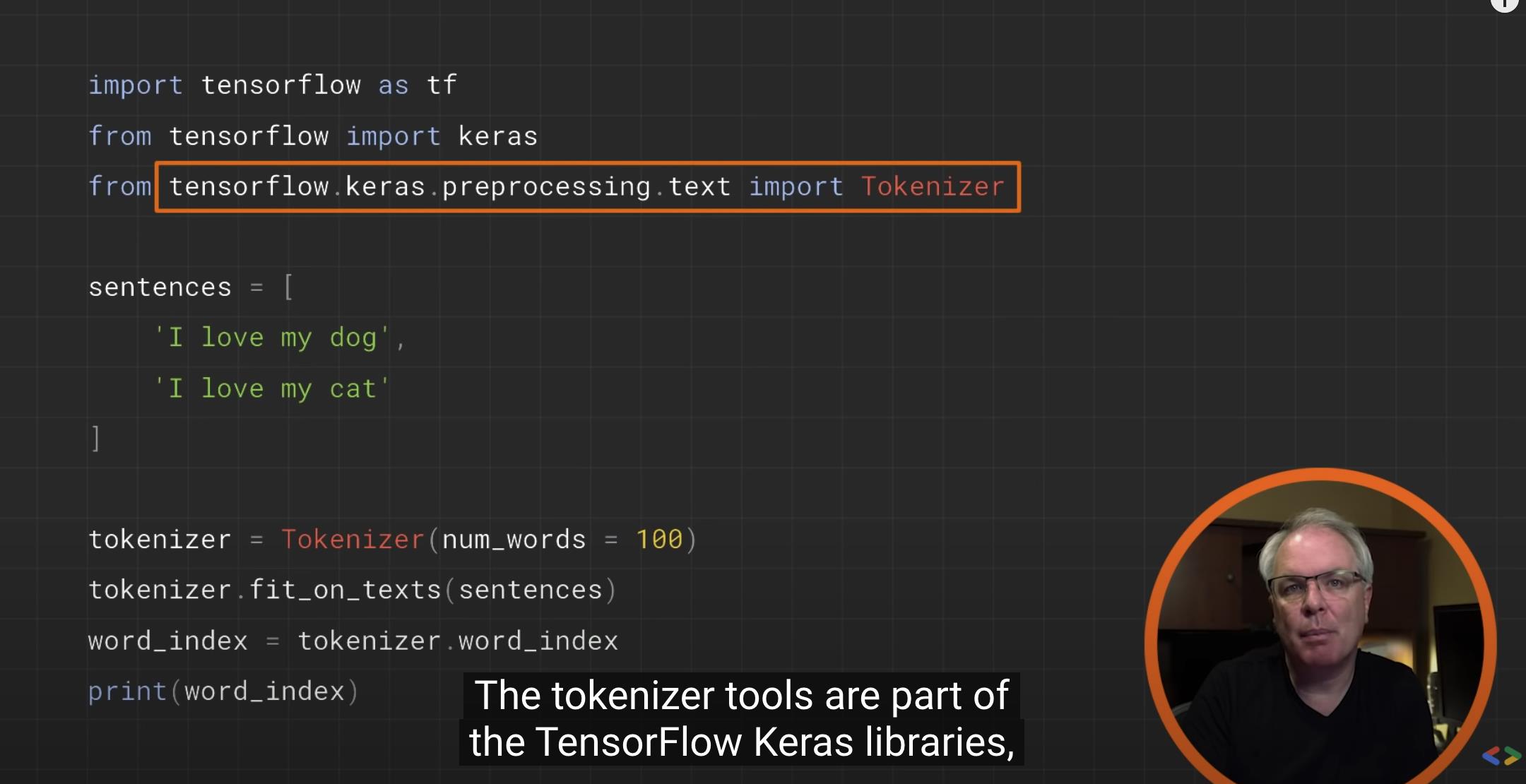
from tensorflow.keras.preprocessing.text import Tokenizer
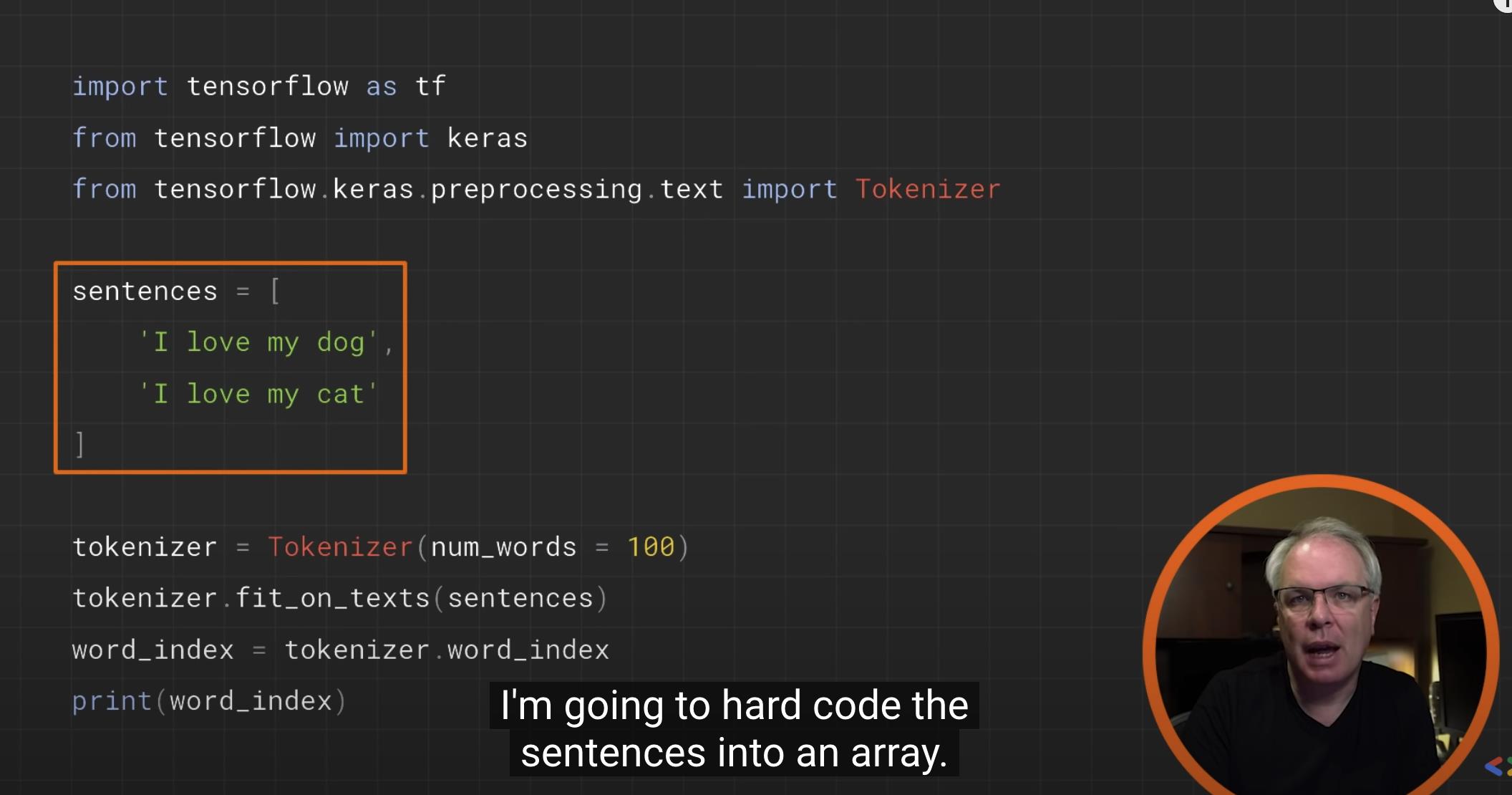
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!',
'hello, hello, hello, hello I am in China now'
]
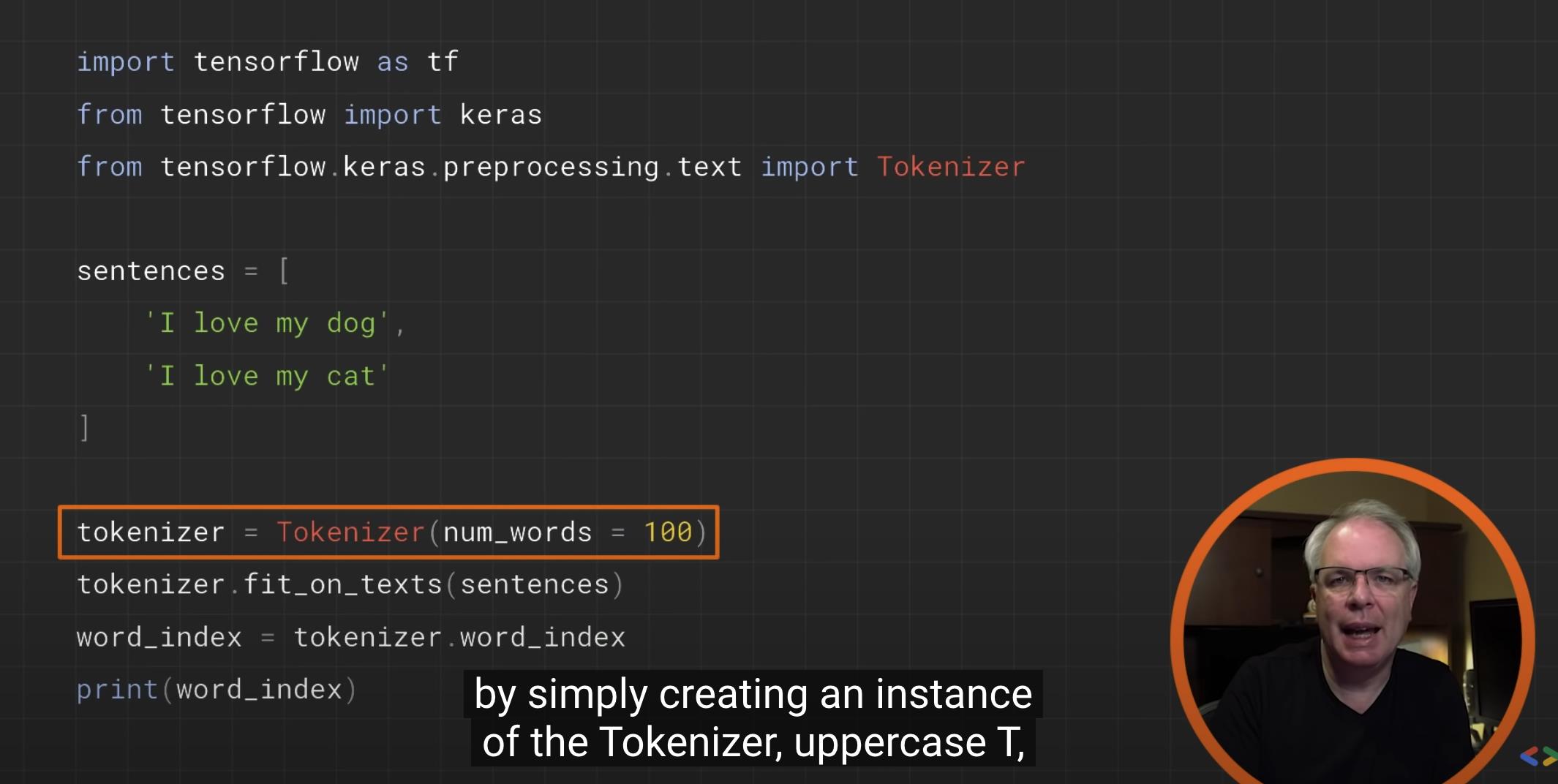
tokenizer = Tokenizer(num_words = 100)
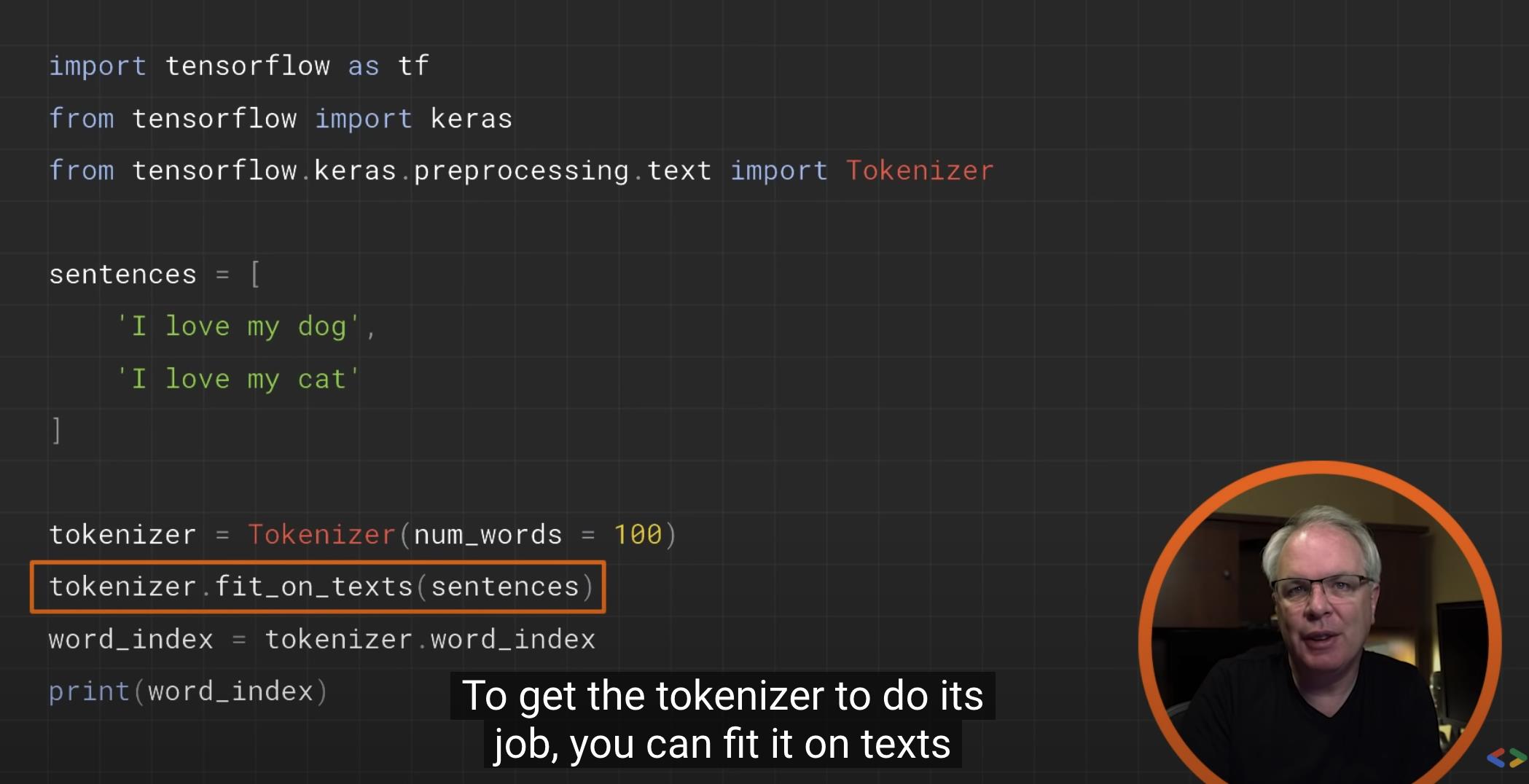
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)

参考
https://youtu.be/f5YJA5mQD5c
以上是关于TensorFlow by Google Machine Learning Foundations: Ep #8 - Tokenization for Natural Language Process的主要内容,如果未能解决你的问题,请参考以下文章
TensorFlow by Google神经网络深度学习的 Hello World Machine Learning Foundations: Ep #1 - What is ML?
TensorFlow by Google CNN卷积神经网络 Machine Learning Foundations: Ep #3 - Convolutions and pooling
TensorFlow by Google一个计算机视觉示例Machine Learning Foundations: Ep #2 - First steps in computer vision(代码
如何在 TensorFlow 中使用“group_by_window”函数