各位大佬,Spark的重点难点系列暂时更新完毕
Posted 王知无(import_bigdata)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了各位大佬,Spark的重点难点系列暂时更新完毕相关的知识,希望对你有一定的参考价值。
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

本文已经加入「大数据成神之路PDF版」中提供下载。
你可以关注公众号,后台回复:「PDF」 即可获取。
更多PDF下载可以参考:《重磅,大数据成神之路PDF可以分类下载啦!》
这个系列写的断断续续,感觉内容还有很多没有涉及。
因为之前写Spark系列的文章太多了,很多东西对大家来说早就是耳熟能详。另外因为社区发展的重心的原因,关于Spark的Streaming和Structured Streaming部分我甚至只字未提。
这个列表包括:
【Spark重点难点】你以为的Shuffle和真正的Shuffle
【Spark重点难点06】SparkSQL YYDS(中)!
【Spark重点难点07】SparkSQL YYDS(加餐)!
【Spark重点难点08】Spark3.0中的AQE和DPP小总结
我在写这个系列的时候,也查了很多资料。2018-2019年我还在做基于Spark的实时计算平台期间对Spark的理解应该是巅峰水平,下了不少功夫,当时组里还在社区参与了一些讨论。
但是这两年因为Flink的崛起,关注开始慢慢少了。但是这也不代表Spark就会沉沦,茫茫多的外企和国内企业还是有非常多业务跑在Spark上,未来写Spark的文章可能是更多的聚焦在和例如Hudi、IceBerg、Pulsar这些新兴的数据组件的结合过程中。
目前组里有大项目在开发中,希望在年前上线。一直脱不开身去学习新的东西,写东西的频率也保证不了,会在年后有所缓解。
新的篇章已经有构思了,期待我后面的「Flink和数据湖小巨头们」系列文章的激烈碰撞吧!
目前也在尝试将一些生产日志数据等非核心链路数据入湖,我已经偷偷潜伏进数据湖的各种社区了!
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊!
《大数据成神之路》正在全面PDF化。
你只需要关注并在后台回复「PDF」就可以看到阿里云盘下载链接了!
另外我把发表过的文章按照体系全部整理好了。现在你可以在后台方便的进行查找:
电子版把他们分类做成了下面这个样子,并且放在了阿里云盘提供下载。
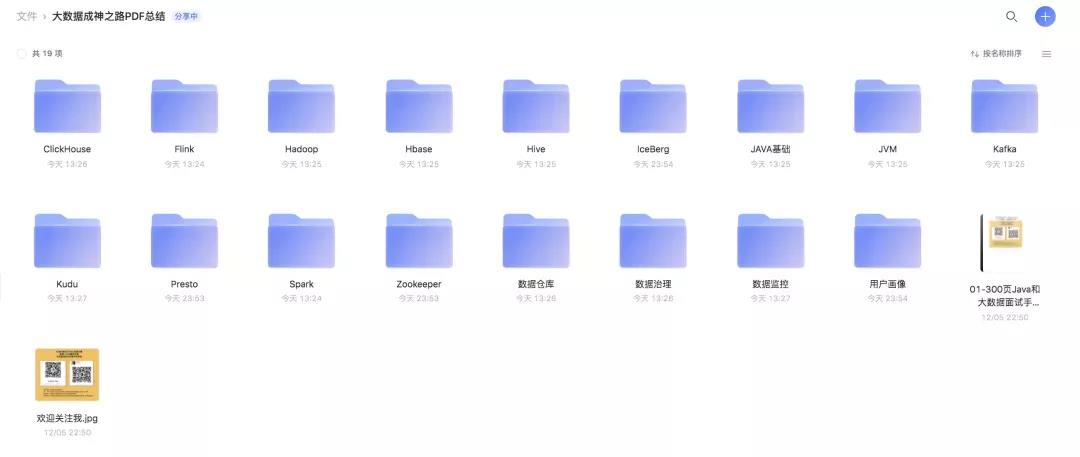
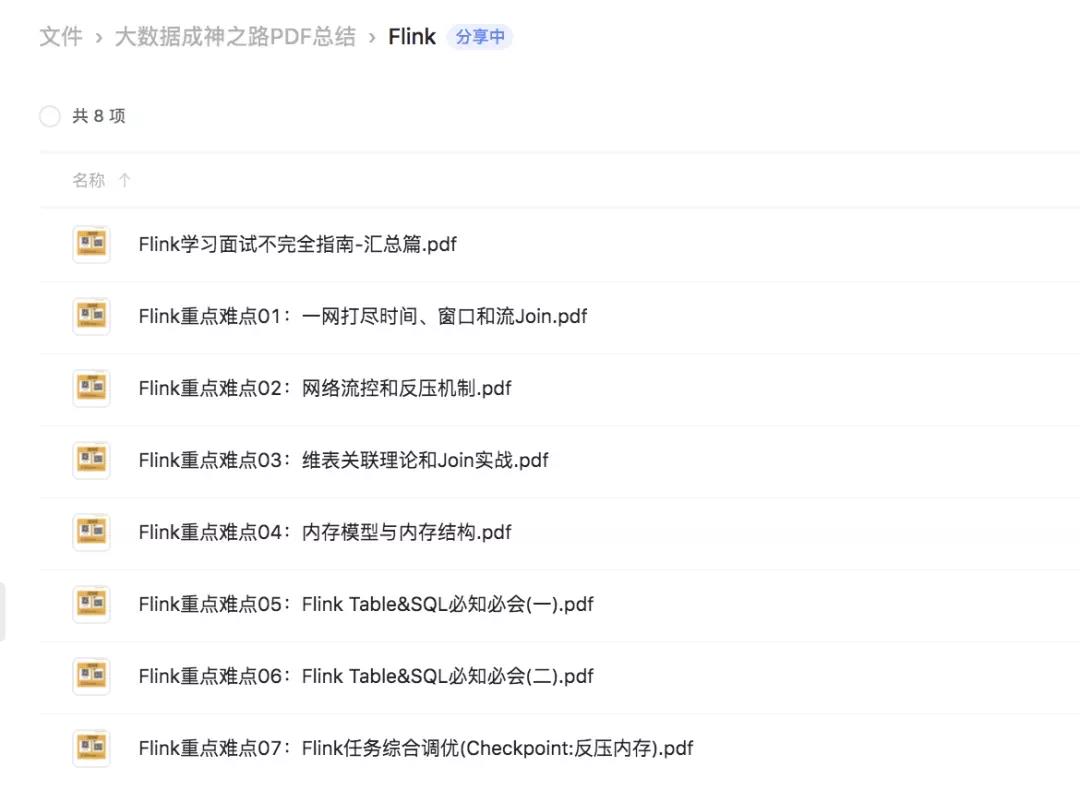
我们点开一个文件夹后:
Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
4万字长文 | ClickHouse基础&实践&调优全视角解析
以上是关于各位大佬,Spark的重点难点系列暂时更新完毕的主要内容,如果未能解决你的问题,请参考以下文章