Elasticsearch 和 MongoDB 对比
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 和 MongoDB 对比相关的知识,希望对你有一定的参考价值。
在我开始接触 Elasticsearch 时,我也有疑问:那就是 Elasticsearch 和 MongoDB 两个都是以 NoSQL 形式来管理数据库的,那么它们之间到底是有什么区别呢?根据 DB-Engine 的报告,Elasticsearch 在搜索领域排名第一,遥遥领先于其它的数据库:
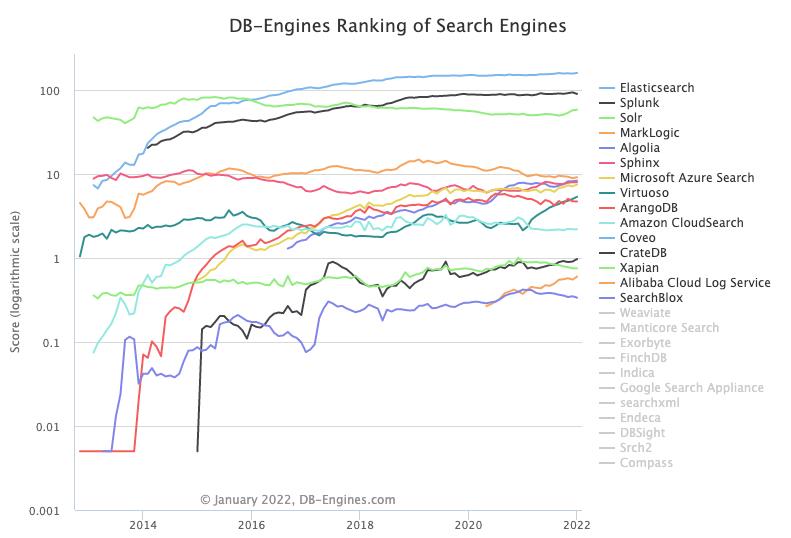
而在数据库管理方面,MongoDB 比 Elasticsearch 更为普及:

在今天的文章中,我们来讲述一下它们之间的比较。
Elasticsearch 和 MongoDB 是用于管理 NoSQL 数据的两个最流行的分布式数据存储。 这两种技术都具有高度可扩展性,并且以面向文档的设计为核心。 然而,这两种技术之间存在差异,了解这些差异以便为你的用例选择正确的技术非常重要。 这篇博文将对比 Elasticsearch 与 MongoDB,并检查这两个数据库在多个领域的差异。
关于 Elasticsearch
Elasticsearch 是一个开源、Java 编写的分布式 RESTful 搜索引擎。 它建立在 Apache Lucene 之上,并使用索引和分片概念通过 HTTP Web 界面和数据分发扩展了 Lucene 的功能。 Elasticsearch 中的索引类似于数据库。 它在命名空间下组织数据,具有定义的模式(schema),并且可以划分为多个分片以进行水平扩展。 Elasticsearch 中的每条记录都存储为 JSON 对象,称为 “文档”(document)。
Elasticsearch 的一些核心功能包括:
- 分布式搜索
- 高可用性
- REST 接口
- 强大的查询 DSL
- 多租户
- 地理搜索
- 水平扩展
尽管拥有丰富的功能集列表,但 Elasticsearch 并不是适用于所有场景的完美数据存储。 在为你的应用程序选择正确的数据存储时,需要考虑一些限制。
关于 MongoDB
MongoDB 是一个用 C++ 编写的面向文档的数据库,其设计目的是处理分布在多个地理位置的 TB 级数据。 在 MongoDB 中,可以创建多个数据库,每个数据库可以有多个集合(表)。 与 Elasticsearch 一样,MongoDB 中的每条记录都作为我们称为 “文档”(document)的 JSON 对象进入存储。 MongoDB 也是无模式(schemaless)数据库,支持内置的安全功能,如身份验证、访问控制和加密。
MongoDB的一些核心特性是:
- 分布式文档存储
- 高可用性
- 无模式(schemaless)
- 强大的查询和聚合
- 水平扩展
- 内置安全性
- 强大的索引功能
- 地理搜索
- GridFS 存储任何大小的文档
MongoDB 最大的限制是它无法快速提供全文搜索,并且缺乏一些搜索功能,比如对文本进行标记。
Elasticsearch 与 MongoDB:详细比较
如上图所示,这些技术在设计和功能上有很多相似之处。 也就是说,它们在性质上差异很大。 Elasticsearch 主要是一个搜索服务器,而 MongoDB 主要是一个数据库。 让我们看看它们在其他领域的区别。
用例
你的用例对于决定哪种技术最合适至关重要。 当需要全文搜索时,Elasticsearch 永远是更好的选择。 Elasticsearch 在日志分析方面也赢得了竞争,因为它不仅提供了广泛的聚合查询,还支持 Kibana、Logstash 和 Beats 等产品——所有这些都使日志分析变得更加容易。
另一方面,当数据是 NoSQL 格式并且你需要一个高度可扩展的数据库,需要 CRUD 操作而不支持全文搜索时,MongoDB 是一个可靠的选择。 MongoDB 还借助基于文本的索引支持全文查询,但它的搜索速度很慢,并且缺少搜索服务器附带的分词器和分析器。
配置文件
Elasticsearch 和 MongoDB 的安装包在各种 Linux、windows 和 Mac 操作系统下都可用。 安装软件包后,可以开始使用默认配置,但这里有一些重要的配置参数,您应该在将它们投入生产之前对其进行修改。 以下所有配置选项均按 Linux 操作系统显示。
如果你是 Linux 系统,你将在 /etc/elasticsearch/config 目录下找到 Elasticsearch 的配置文件,如下所示:
config |-- elasticsearch.keystore |-- elasticsearch.yml |-- jvm.options |-- log4j2.properties |-- role_mapping.yml |-- roles.yml |-- users `-- users_roles
然而,所有 MongoDB 配置只能在 /etc/mongod.conf 下的单个文件中完成。
备份恢复
默认情况下,Elasticsearch 和 MongoDB 都提供备份和恢复功能。
Elasticsearch 在插件的帮助下使用 _snapshot REST 端点执行增量备份,其备份目标可以从文件系统到云存储而有所不同。 快照的好处是它们本质上是增量的。 你可以轻松删除旧快照,并且快照恢复配置超级简单。 但是,快照 API 不提供可查询的备份。
例如,
要在 S3 存储桶中进行 Elasticsearch 备份,你必须使用以下命令在每个 Elasticsearch 节点上安装 S3 存储库插件:
sudo bin/elasticsearch-plugin install repository-s3然后在你的 AWS s3 存储桶中注册一个存储库:
curl -X PUT "localhost:9200/_snapshot/test_s3_repository?pretty" -H 'Content-Type: application/json' -d'
"type": "s3",
"settings":
"bucket": "s3_bucket_name"
一旦存储库注册了存储库,就可以使用以下命令开始拍摄快照:
curl -X PUT "localhost:9200/_snapshot/test_s3_repository/snapshot_1?pretty"MongoDB 提供了多种执行备份的方法。 第一个是“mongodump”工具,它随 MongoDB 安装一起提供,是 DevOps 团队最常用的解决方案。 虽然 mongodump 有一些限制——它不进行增量备份并且对大型数据库无效——但它提供了 1) 可查询备份、2) 整个数据库备份和 3) 单个集合等功能。
要在 MongoDB 中实现增量备份,需要使用 MongoDB oplog,它是一个 capped 集合。 还可以通过拍摄文件系统的快照来创建 MongoDB 部署的备份。 这会复制 MongoDB 的底层数据文件。 MongoDB 的企业版允许你访问其他选项,例如 MongoDB Atlas、MongoDB Cloud Manager 和 MongoDB Ops Manager。
要使用 mongodump 进行备份,你只需运行以下命令:
mongodump --db <database_name> --host <mongohost_ip_address>但是,与 Elasticsearch 快照不同,mongo 转储将保存在本地磁盘上,而不是保存到 S3 存储桶或任何其他云存储中。
支持处理关系数据
NoSQL 数据存储有利于扩展、写入和读取查询的高吞吐量。但是,它们不能处理关系数据,也不具备关系数据库提供的 ACID 属性。关系数据库将数据存储在行和列中。虽然你可以轻松规范化,但 Elasticsearch 和 MongoDB 支持文档模型。因此,他们专注于以非规范化格式保存数据。
虽然这些数据存储中的数据建模没有硬性规定,但习惯上依赖于在文档中保留重复数据或执行应用程序端连接。
尽管有其局限性,但 Elasticsearch 有两个用于处理关系数据的内置功能:1) nested 和 2) joined 模型。
MongoDB 还有两种处理关系数据的方法。一种是嵌入式文档模型,其中相关对象作为子文档进入存储。另一种是参考模型,它包括从一个文档到另一个文档的链接或参考。
数据存储架构:Lucene 与 C++
Elasticsearch 建立在 Lucene 之上,并使用 Lucene 段在倒排索引中写入数据。元数据信息(例如索引映射、设置和其他集群状态)写入 Lucene 之上的 Elasticsearch 文件中。
Lucene 段的问题在于它们本质上是不可变的,并且每次提交都会创建一个新段(segment)。这些片段根据合并设置在幕后合并。这使得数据更新成为繁重的操作,因为当每个文档更新到位时,会生成一个新文档并覆盖以前的文档。
为了避免生成过多的段和大量的 I/O,Elasticsearch 为每个索引维护一个事务日志,避免每个索引操作上的低级别 Lucene 提交。事务日志对于在发生崩溃或数据损坏事件时恢复数据也很有用。
MongoDB 的底层存储模型与 Elasticsearch 完全不同。 MongoDB 是用 C++ 编写的,并使用内存映射文件将磁盘上的数据文件映射到内存中的字节数组。它使用双向链表数据结构来组织数据。每个文档都包含一个链接列表,链接到每个其他文档以及引擎盖下的实际 BSON 编码数据。 MongoDB 使用日志日志来帮助在硬关机的情况下进行数据库恢复。最终,如果系统内存不足或其他系统资源的利用率非常高,MongoDB 进程将自行关闭。
这些差异表明 MongoDB 是为 1) 高写入和 2) 更新吞吐量而构建的,而不会导致高 CPU 和磁盘 I/O 问题。
文件大小
Elasticsearch 支持的默认最大文档大小最多为 100 MB,尽管你可以将此最大值增加到 2GB — Lucene 的限制。 但是,重要的是要记住,非常大的文档通常会产生其他问题。
默认情况下,MongoDB 支持最大 16 MB 的文档存储。 你可以使用 GridFS 功能存储更大的文档。
许可模型、监控和安全
Elasticsearch 是一个免费及开源的软件。目前你可以使用较为宽松的 Elastic 许可 v2 及 SSPL。详细阅读,请参阅文章 “Elastic:隆重推出授权更加简单且宽松的 Elastic 许可 v2;SSPL 仍可选择使用”。
MongoDB 也是免费使用的,其社区版附带服务器端公共许可证 (SSPL) v1.0。社区版包含所有核心 MongoDB 功能,如基本监控工具和安全性。如果您计划探索和使用 MongoDB 管理、高级监控、内存数据库引擎和 BI-Connector 等高级功能,你可以选择 MongoDB 企业版。
编程语言:Java vs. Lucene
Elasticsearch 是用 Java 编写的,MongoDB 是用 C++ 编写的; 但是,这两种技术都以多种语言提供广泛的客户端支持。 Elasticsearch 有适用于 Java、javascript、Ruby、GO、.NET、php、Perl、Python 和 Rust 的客户端。 此外,还有几个社区贡献的客户端可用于 C++、Scala 和 R 等语言。
MongoDB 为 C、C++、Scala 和 Swift 等语言提供了更广泛的驱动程序。 MongoDB 也有多个社区贡献的客户端。
概括
Elasticsearch 和 MongoDB 都针对特定用例进行了设计,但在某些常见场景中,选择一种工具而不是另一种可能会更复杂。 在此博客中,我们审查并比较了这两种技术的各种特性,以帮助你做出这些更困难的决定。
总而言之,MongoDB 是一个非常流行且可扩展的 NoSQL 数据库,是面向文档的数据库的领导者。 当用例需要具有高吞吐量事务的高度可扩展的数据库时,它通常是最佳解决方案。 在处理全文搜索、日志分析、发现异常和根本原因检测方面,Elasticsearch 无疑是赢家。
以上是关于Elasticsearch 和 MongoDB 对比的主要内容,如果未能解决你的问题,请参考以下文章
如何在mongodb和elasticsearch之间进行同步?
Playframework + Morphia + MongoDb + ElasticSearch = Disater?