python正则表达式入门
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python正则表达式入门相关的知识,希望对你有一定的参考价值。
🙊今天我们来学习python的正则表达式的部分,先说下为什么要学习这一部分呢,当然是因为正则表达式处理文本类型的数据实在是太方便了。为以后进入nlp领域打打基础!
先给大家推荐一个网站: 用于正则表达式验证.
大致就长这个样子。
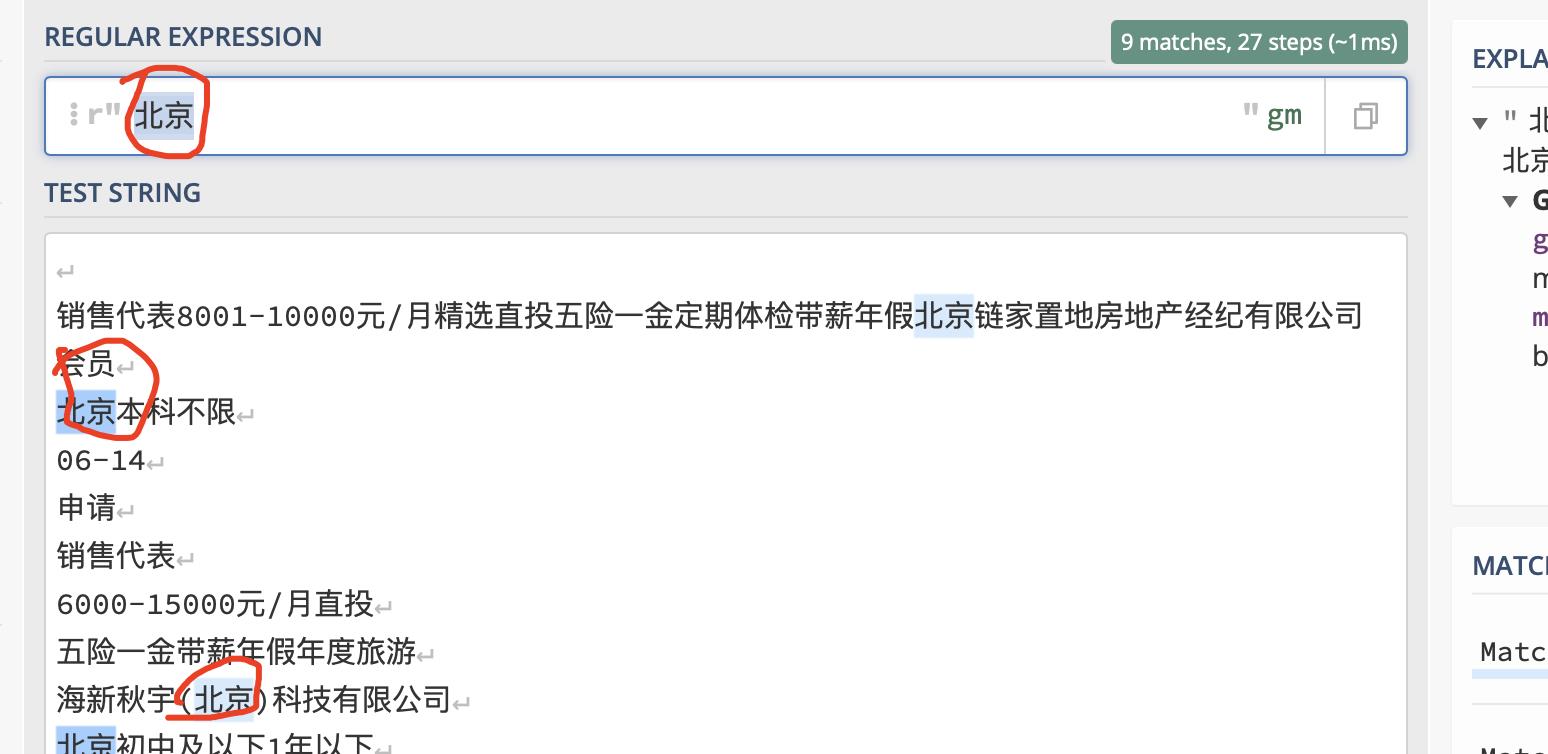
1.基础知识
- 普通字符:普通字符的含义就是字节匹配他们。
- 特殊字符:它们出现在正则表达式中,不是直接匹配他们,而是表达一些特殊的含义。
.表示匹配除了换行符之外的任何单个字符
例如匹配‘’.公司‘’(匹配三个字符)
#这里展示一下python怎么使用正则表达式
import re #正则表达式的库
content='''
苹果是红色
香蕉是黄色
叶子是绿色
天空是蓝色
'''
#将表达式转化为pattern对象,就可以调用后面的find之类的方法
p=re.compile(r'.色')
for i in p.findall(content):
print(i)
结果如下:

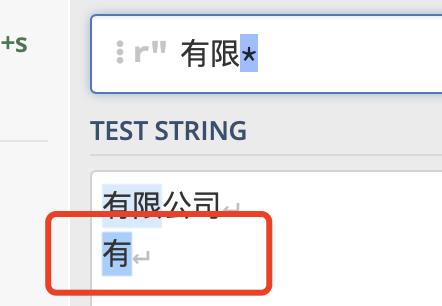
*表示匹配前面的子表达式任意次,包括0次
例如:匹配,.*表示匹配,以及后面的所有字符

当然前面可以跟普通字符 “好” 匹配 “好好好…”
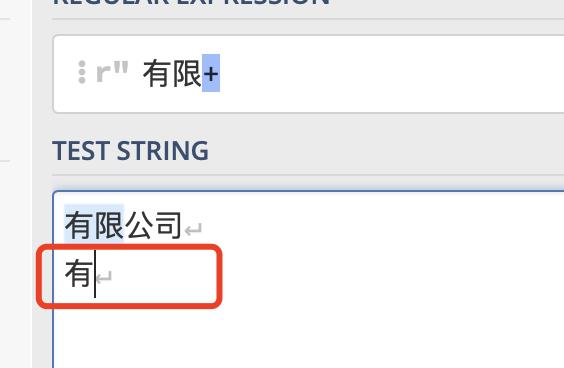
+表示匹配前面的子表达式一次或者多次,不包括0次
区别就是不包括0次。
+号的(不能0次)
*号的(可以0次)
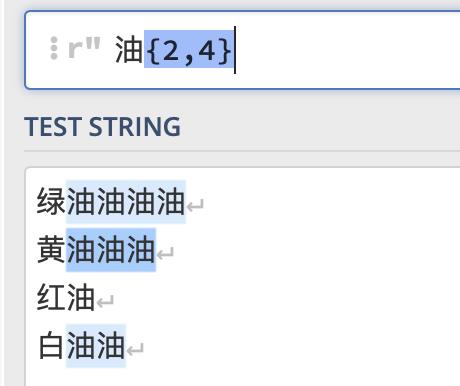
匹配前面的字符指定的次数
例如:表达式"油2,4"表示匹配油字最少2次最多4次
2.贪婪模式和非贪婪模式
不知道大家看懂了下面的这张图吗?
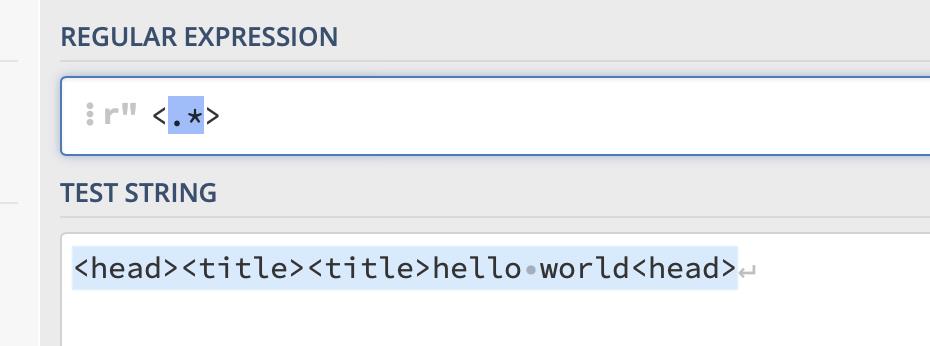
我们只想一个一个匹配
<head><title>
标签,但是它却帮我吗全部都匹配上了,这是因为它只看见了第一个 “< ”和左后一个“>”中间部分全部看成了任意字符,这就是贪婪模式,它会最大限度地匹配字符。
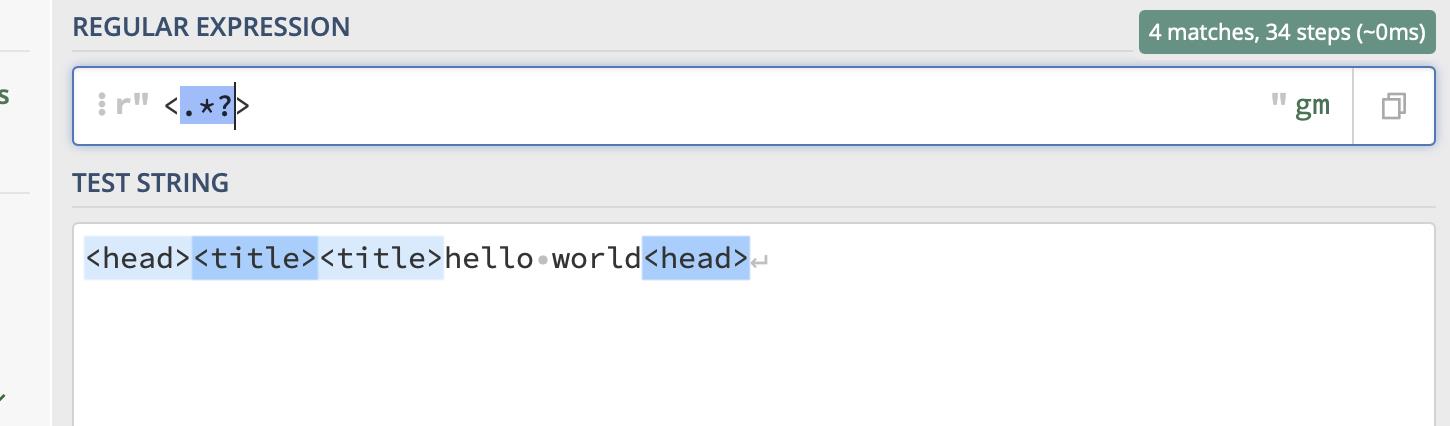
要想变成非贪婪模式,需要在‘+’,”*“后面加一个‘?’ 这样子就是匹配4个字符。
3.反斜杠的用途
反斜杠 \\ 在正则表达式中多种用途,比如转义
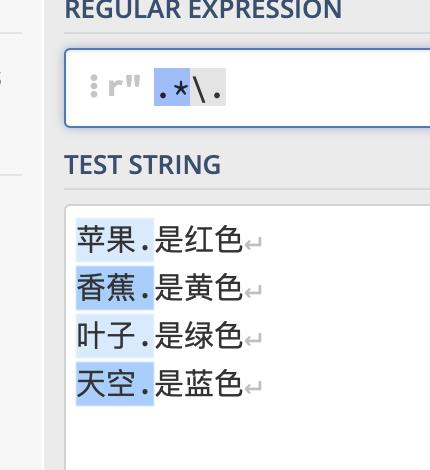
例如:我们需要寻找.之前的所有元素 需要使用
.
∗
/
.
.*/.
.∗/.斜杠是为了告诉程序后面一个字符代表普通字符.的含义
反斜杠可以和一些字符组合表示一些特殊字符

4.中括号的用法
中括号可以用来表示条件或[0123] 或者[0-3]代表这个字符可以是0,1,2,3
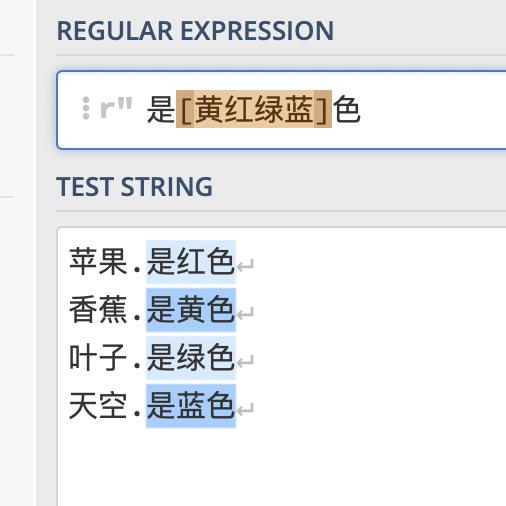
也可以存放字符[黄红绿蓝]、[a-z]这一类
例如:匹配包含‘’是[黄红绿蓝]色‘’的字符
需要说明一些元字符在[]中就是失去了自己的意义,变成普通字符了
例如. + *不需要转义。‘
例如查找“.是”的字符
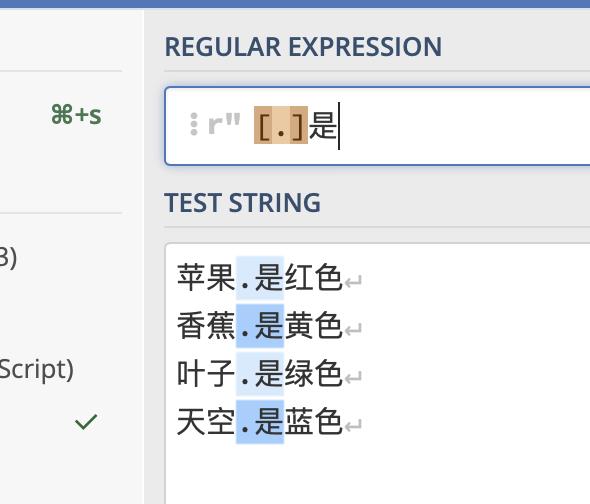
如果在[]中使用^字符,则表示非的概念
例如:匹配非数字字符
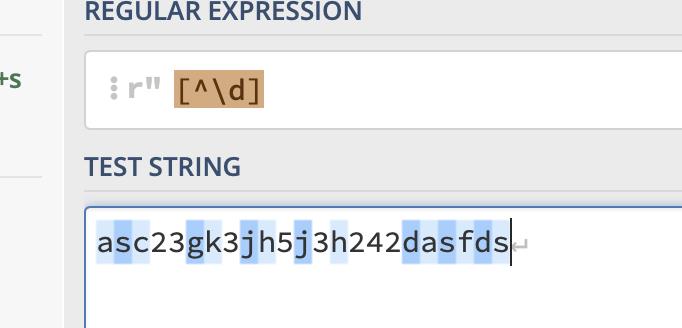
5.匹配启始和结束位置
^表示匹配文本启始的位置但在不同模式下效果不一样
正则表表达式主要有2种模式:单行模式和多行模式
单行模式:是指把整个文本看作是一组数据,只匹配所有数据的开头
多行模式:是指把每一行看成是一组数据,匹配每一行的开始
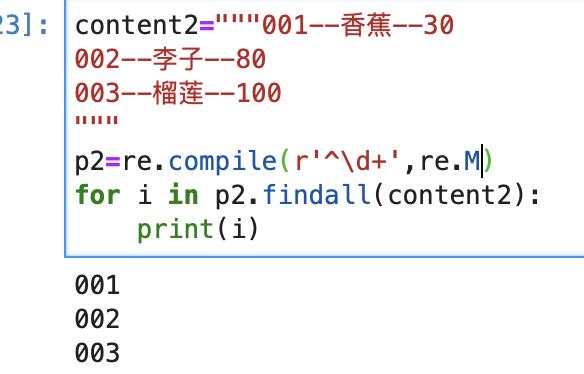
例如:我们使用单行模式匹配,只匹配了第一行的001
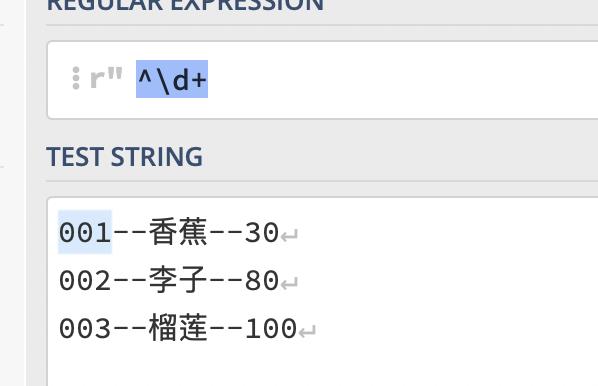
例如:我们使用多行匹配,匹配到了001、002、003
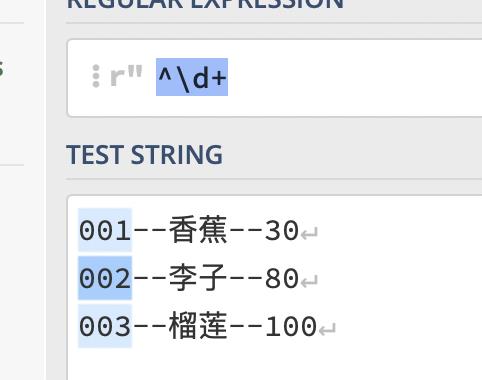
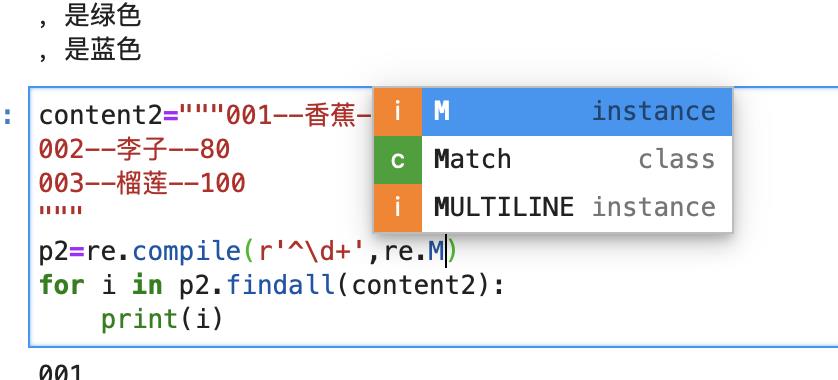
问题来了,在python中如何制定是是单行还是多行模式呢?
在compile里面增加参数re.M或者re.MULTILINE都行。
结果如下:
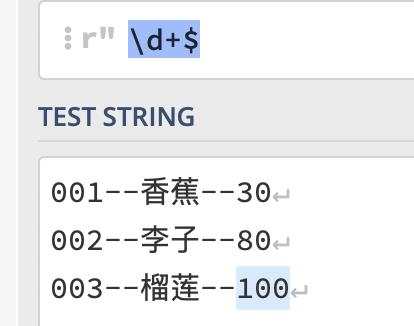
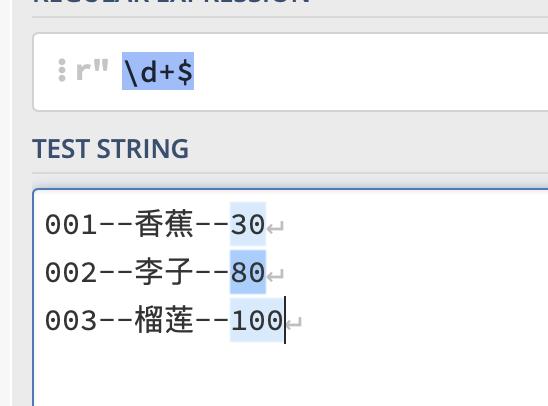
$表示文件的结尾,用法和^类似,也分多行模式和单行模式
单行模式
多行模式
6.括号的用法—组选择
组选择:是指从正则表达式匹配的结果中再选择出我们所需要的字符,例如:我们需要匹配逗号前面的字符,我们可能会写“.*,”可是这样匹配出来的字符中含有逗号,可我们不想要这个逗号,这时就需要用组选择。
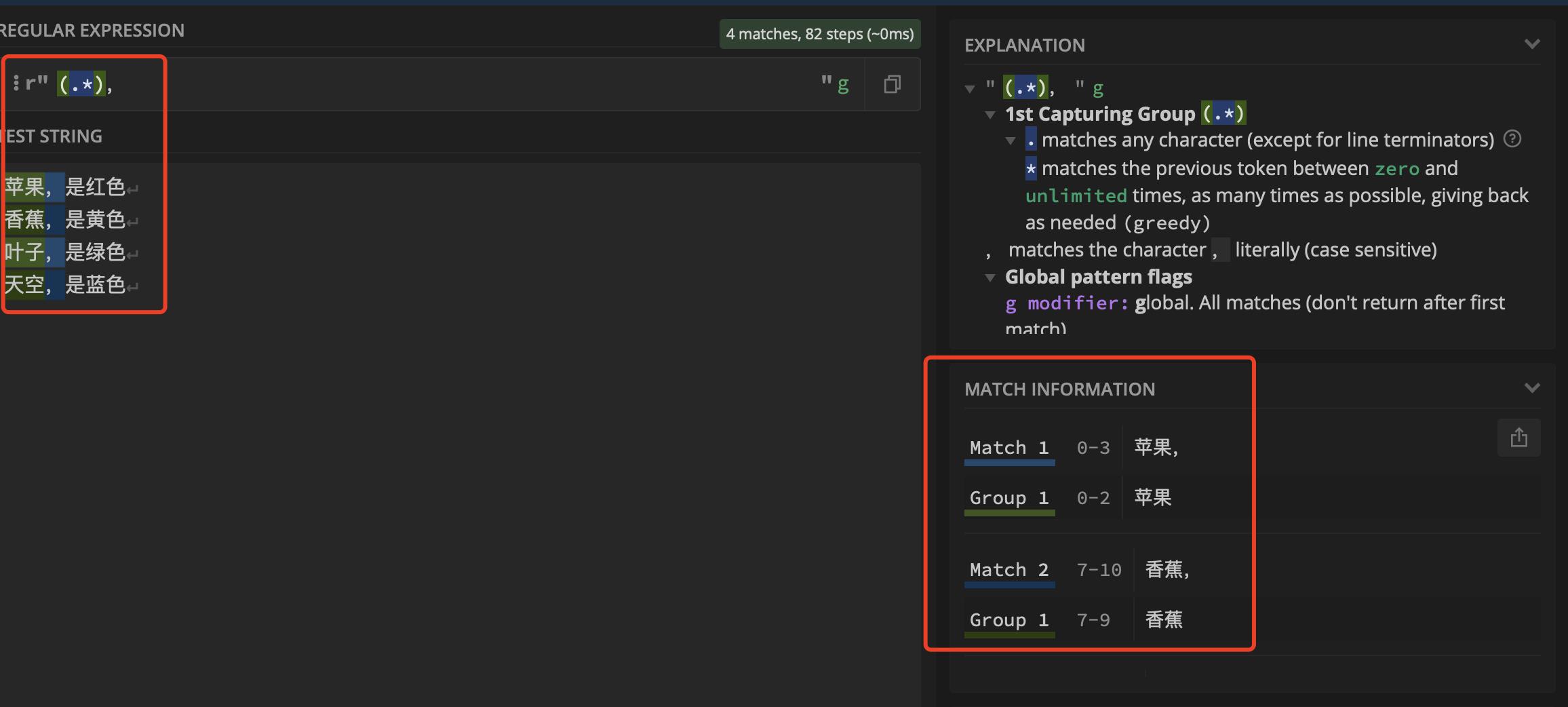
看一看python的写法

如果遇见多个分组,那么每一行的数据就会变成元组,你可以通过元组下标来取出对应的字符。

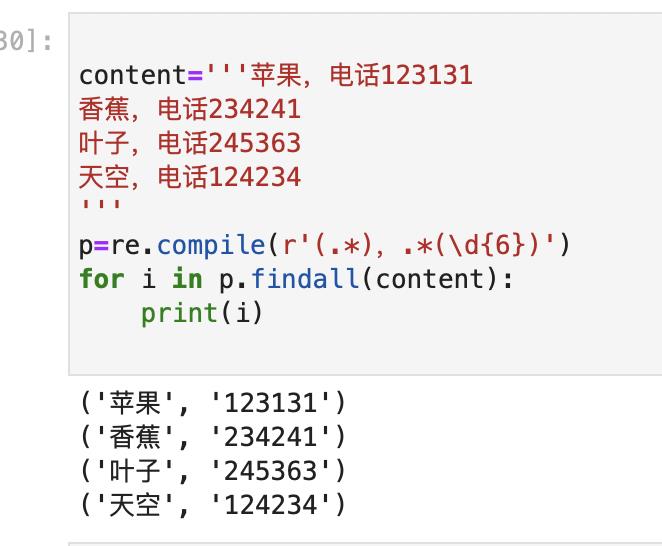
来一个小练习:给你一组数据,请从中选出人名和电话号码
苹果,电话123131
香蕉,电话234241
叶子,电话245363
天空,电话124234
python实现如下:
7.正则表达式切割字符
字符串对象的split()方法只适用于非常简单的字符串分割情形,当你需要更加灵活的切割字符的时候,就需要用正则表达式了
例如:
#我们这里有一组数据
names=‘关羽;张飞,马超,老夫子,李元芳 狄仁杰’
这应该如何切割呢?
我们可以利用re.split用正则表达式的符号来制定分隔符。

总结
这一这章节主要是进行正则表达式的基础学习,当作一个小小的入门教程还是很不错的,日后碰见复杂的用法会继续添加。
以上是关于python正则表达式入门的主要内容,如果未能解决你的问题,请参考以下文章