模型训练目标检测实现分享一:详解 YOLOv1 算法实现
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型训练目标检测实现分享一:详解 YOLOv1 算法实现相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],回复001获取Google编程规范
O_o >_< o_O O_o ~_~ o_O
大家好,我是极智视界,本文详细介绍一下 YOLOv1 算法的设计与实现,包括训练。
本文是目标检测类算法实现分享的第一篇,从 用回归做物体检测 算法开山鼻祖 YOLOv1 讲起。YOLO (You Only Look Once) 是充满艺术性和实用性的算法系列,而 YOLOv1 是个开头,在论文《You Only Look Once:Unified, Real-Time Object Detection》中提出。YOLO 目标检测算法以实时著称,并经不断发展能逐步兼顾精度。简单看一些 YOLO 官网的宣传效果:

下面开始,同样这里不止会讲原理还会讲实现及训练。
1、YOLOv1 原理
在论文中其实不止提出了 baseline YOLOv1 模型,还提出了 Fast YOLOv1,而 Fast YOLOv1 旨在让人们看到 YOLO 的效率极限。先来看论文中的实验数据,YOLOv1 的主要对标对象是 Fast R-CNN、DPM,下面是精度 (mAP) 和 性能 (fps) 数据:

训练测试数据集是 PASCAL VOC 0712,硬件是 Nvidia Titan X,这里我们主要关心 Real-Time Detectors,可以看到相比于 DPM 和 Fast R-CNN, YOLOv1 兼顾精度和推理效率,还可以注意到 Fast YOLOv1 的帧率达到了的 155 fps,相当于浮点推理单图 6.5 个 ms,这在当时相当快。
YOLOv1 相比于 Fast-RCNN 能够更加好的区分背景和待检测目标,然而 YOLOv1 并不是一个极度完美的网络,还有一些缺陷 (这跟网络设计相关),如下:
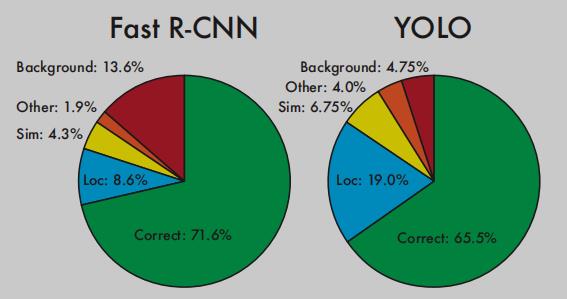
上图是 Fast R-RCNN vs YOLOv1 Error Analysis,可以看到主要有以下几点:
(1) YOLOv1 的预测准确度 Correct 没 Fast R-CNN 高;
(2) YOLOv1 的 Localization 错误率更高,这是由于 YOLOv1 采用直接对位置进行回归的方式进行预测,这不如滑窗式的;
(3) YOLOv1 对于背景预测的错误率更低;
以实验结论为导向,下面介绍 YOLOv1 的网络设计艺术。
1.1 网络结构设计
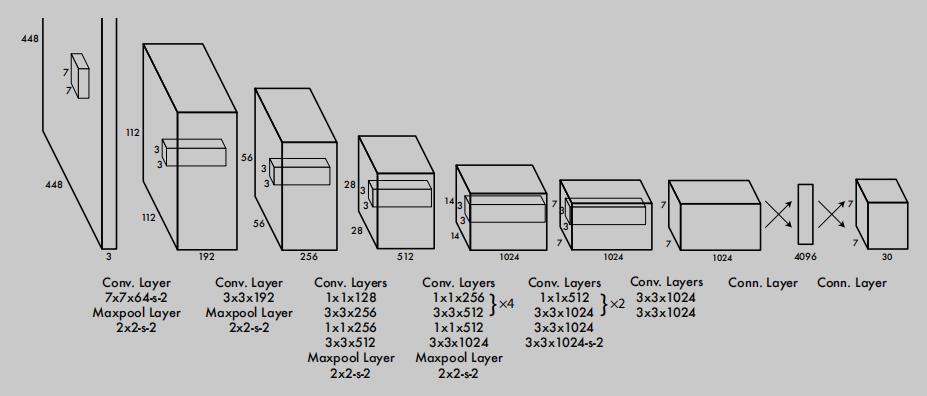
整个网络由 24 个卷积层 (受 GoogLeNet 启发,有很多 1 x 1 和 3 x 3 交替的结构) 和 2 个全连接层构成,输入图像尺寸为 448 x 448,输出为 7 x 7 x 30,说一下输出为啥是这个 shape。YOLOv1 会把输入图像划成 7 x 7 的 grid,每个 grid 负责预测 2 个目标,对于每个目标来说又有这些属性:x、y、h、w、置信度,然后再加上类别数 20,这样就形成了 7 x 7 x (2 x 5 + 20) = 7 x 7 x 30 的输出 tensor 了。如下:
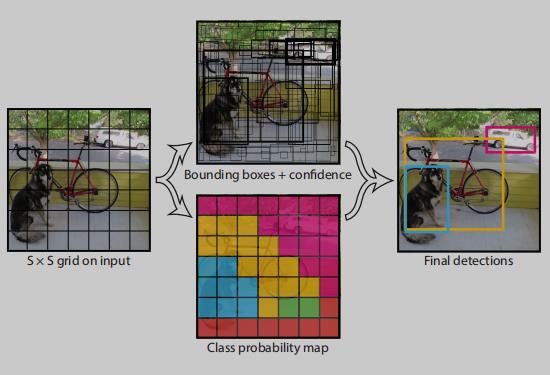
由于 YOLOv1 将图片划分为 7 x 7 个 grid,虽然每个 grid 负责预测两个目标,但最后会通过抑制只保留一个匹配度最高的 bounding box,也就是说一张图我最多就给你预测七七 49 个目标,那么想一下,如果有两个相邻的目标落在了同一个 grid 中,那么势必会漏检一个,所以 YOLOv1 对于邻近目标的检测效果不好。
1.2 损失函数设计
YOLOv1 的整个损失函数如下,这个比较经典:

一个个来说:
(1) 第一个和第二个都是位置损失。第一个是中心点位置损失,采用简单的平方和进行计算。其中 lij^obj 是一个控制参数,作用是当标签中该 grid 有待检测物体,则为 1,否则为零;
(2) 第二个是宽高损失。这里对 w、h 分别取了根号,原因是这样可以减缓倾向于调整尺寸比较大的预测框,这里的 lij^obj 和第一个中的一样;
(3) 第三个和第四个需要结合起来看,都是预测框的置信度损失。第三个是有目标的时候,第四个是没有目标的时候,我们知道,实际检测时 49 grid 中每个 grid 有目标和没目标也是个长尾问题,往往有目标的情况占少数,所以在这里设计给了 λobj = 5,λnoobj = .5 的权重平衡;
(4) 第五个是类别损失。
原理就讲这么多,接下来是实践。
2、YOLOv1 实现
github 地址:https://github.com/AlexeyAB/darknet
darknet 编译就不多说了,默认已经编译好了,这步不会的同学可以翻看我之前的文章,有相关介绍。
下面介绍一下制作 VOC0712 融合数据集。
2.1 制作 VOC0712 融合数据集
下载数据集
# download datasets
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
# 解压
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
制作 imagelist:
# 生成label及train.txt、test.txt、val.txt
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py
# 配置 2012train、2007_train、2007_test、2007_val 为训练集,2012_val 为验证集
cat 2007_* 2012_train.txt > train.txt
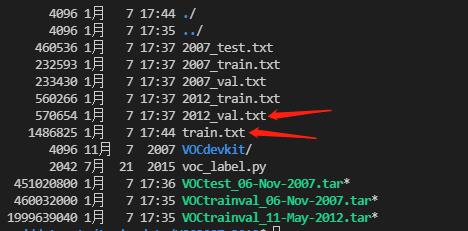
这个时候的目录结构是这样的:
2.2 训练
然后可以进行训练,这里需要注意的是 YOLOv1 的训练指令和 YOLOv2 和 YOLOv3/v4 的不太一样,YOLOv1 的训练指令如下:
./darknet yolo train cfg/yolov1/yolo.train.cfg
是不是稍微有点好奇,以上命令中并没有指定训练图片路径,这个路径是在代码内部写死的 (包括保存权重的路径 backup/ 也是写死的):

这个地方可以改成自己想指定的 train.txt 的路径,然后重新编译框架:
make clean
make -j32
然后再执行训练指令,开始训练:

可以看到已经开始训练了,这里我们使用了默认的训练配置:
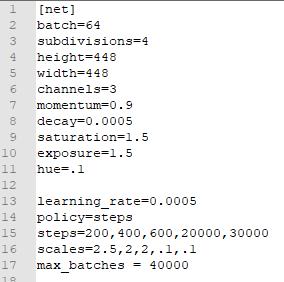
这里的一些参数可以根据自己的需要进行相应的修改。
2.3 验证
训练的过程比较漫长,等训练结束可以测试一下训练结果:
./darknet yolo test cfg/yolov1/yolo.cfg backup/yolo.weights
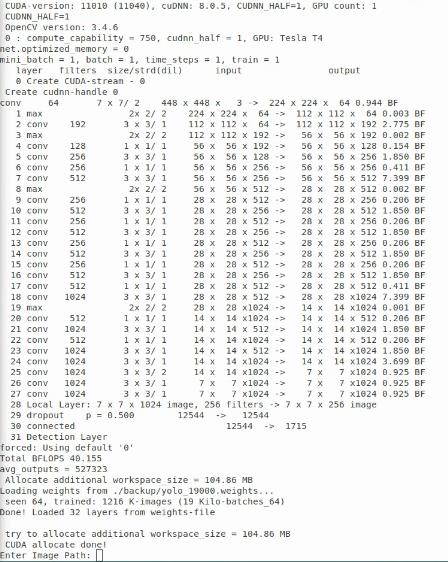
在 Enter Image Path 中输入待检测图片,如 data/dog.jpg 可以看到检测效果:

这样就完成了 YOLOv1 数据集准备、训练到验证的整个环节。
以上详细分享了 YOLOv1 的原理和实践,希望我的分享能对你的学习有一点帮助。
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型训练目标检测实现分享一:详解 YOLOv1 算法实现的主要内容,如果未能解决你的问题,请参考以下文章
模型训练目标检测实现分享二:听说克莱今天复出了?详解 YOLOv2 算法与克莱检测