模型训练目标检测实现分享二:听说克莱今天复出了?详解 YOLOv2 算法与克莱检测
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型训练目标检测实现分享二:听说克莱今天复出了?详解 YOLOv2 算法与克莱检测相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],回复001获取Google编程规范
O_o >_< o_O O_o ~_~ o_O
大家好,我是极智视界,本文介绍一下克莱复出与 YOLOv2 算法的设计与实践。
本文是目标检测类算法实现分享的第二篇,之前已经写过一篇,有兴趣的同学可以查阅:
(1) 《【模型训练】目标检测实现分享一:详解 YOLOv1 算法实现》;
从名字就可以看出 YOLOv2 是在 YOLOv1 的基础上的改进版,在论文《YOLO9000: Better, Faster, Stronger》中提出,同时提出了 YOLO9000 模型,这个模型结构和 YOLOv2 一样,只是训练方式做了创新,本文主要关注 YOLOv2,就不多说 YOLO9000 了。同样这里不止会讲原理还会讲实践,话不多说,下面开始。
文章目录
1、YOLOv2 原理
先来看实验数据:
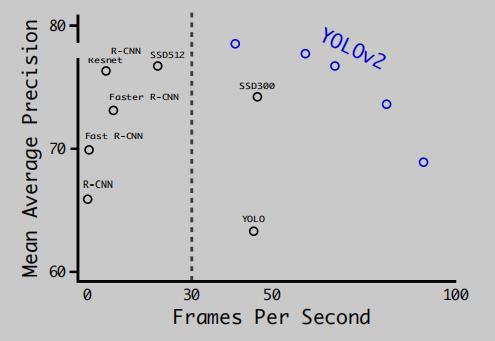
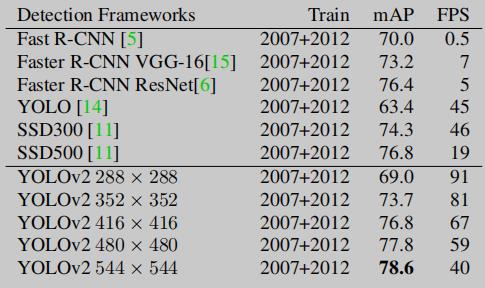
上图是 YOLOv2 和当时主流的检测模型的效率精度对比图 (数据集为 VOC0712),从效率精度综合考虑越往右上越好,可以看出 YOLOv2 在兼顾效率和精度方面做得很好。然后说一下为啥图上 YOLOv2 有好几个点,这分别对应不同的输入分辨率的结果,数据如下:
YOLOv1 有两个缺陷:
(1) 位置错误率高 / 偏移严重;
(2) 召回率低;
YOLOv2 针对以上两个缺陷进行了改进,来看看到底做了哪些改进能让 YOLOv2 有这么大的提升,新加 tricks 总览如下:

下面一一道来。
1.1 Batch Normalization
BN 层是现在检测网络中常用的算子,从 BN 出来的数据服从高斯分布,能够极大的加快模型收敛,同时也能提高模型的准确率。作者测试在 YOLO 的卷积层后加上 BN 层能使 mAP 提 2 个点,结构差不多是这样:
1.2 High Resolution Classifier
相对于 YOLOv1 backbone 在 ImageNet 数据集上预训练输入分辨率 224 x 224,YOLOv2 调整为先以 448 x 448 的分辨率在 ImageNet 数据集上训练 10 个 epoch,再用 COCO 检测数据集进行微调。作者测试更高分辨率的预训练能让 mAP 提 2 个点。
1.3 Convolutional With Anchor Boxes
YOLOv1 中采用全连接层直接对预测框进行回归预测,由于各种目标的长宽比相差很大,又没什么约束,预测框很难自适应不同的目标。YOLOv2 借鉴了 Faster R-CNN 中 RPN 网络先验框的概念,用 卷积 + Anchor Box 替换 YOLOv1 的全连接层。YOLOv2 在进行如此操作后,mAP 略有下降,召回率却大幅提升。
YOLOv2 在使用 Anchor 后还有两个问题:
(1) Anchor 尺寸手工选择,不能很好适应物体实际尺度;
(2) 使用 Anchor 对于位置预测具有不稳定性。
下面会针对以上这两点缺陷进行相应改善。
1.4 Dimension Clusters
这个 trick 主要是为了解决 Anchor 尺寸手工选择,不能很好适应物体实际尺度的问题。这里采用了 k-means 根据训练集中的先验框自动聚类来生成 Anchor 的宽高,具体怎么做的呢。为了预测框和真实框的 IOU 更高,设计 k-means 聚类的距离指标为:

然后选取不同数量的聚类中心,在 VOC 和 COCO 数据集上的测试数据如下:
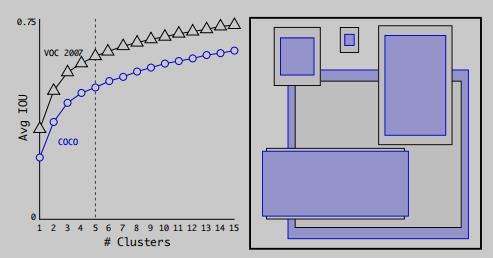
作者发现当聚类中心数 k = 5 时能够在模型复杂度和高的召回率之间获得一个好的平衡,这样就完成了 Anchor Box 的自动选择。
1.5 Direct location prediction
这个 trick 是为了解决 Anchor 对于位置预测的不稳定性。YOLOv1 中是这么计算预测框的中心位置的:假设需要计算的预测框的中心位置为 (x, y),网络输出的坐标偏移值为 (tx, ty)、先验框的尺度为 (xa, ya)、grid cell 的中心坐标为 (xa, ya),则有:

若这么计算,问题就来了,上面的算式是没有约束的,也就是最后算出的预测框中心位置极为不稳定,这也是 YOLOv1 中位置错误率高的重要原因。YOLOv2 对此进行了改进,使用 sigmoid 函数控制偏移值在 (0, 1) 之间,且偏移是相对于 grid cell 的左上顶点,采用这样的方式将预测框的中心点约束在当前的 grid cell 中,不会乱跑。用算式表达是这样的:假设 grid cell 的左上顶点为 (cx, cy),bounding box 先验的宽高为 pw 和 ph,网络对于 bounding box 预测的 5 个坐标值为 tx, ty, tw, th 和 to,那么预测框的位置可以这么计算:

1.6 Fine-Grained Features
YOLOv2 最后预测是在 13 x 13 的 feature map 上,这个优化是在从 26 x 26 x 512 到 13 x 13 x 2048 的过程中加入类似残差网络的恒等映射结构,以减少特征细粒度的损失,这里把它称为 passthrough 层,结构类似这样:

这个优化能带来 1 个点的性能提升。
1.7 Multi-Scale Training
这是源于 YOLOv2 把 YOLOv1 的全连接层给替了,只采用卷积和池化层,所以可以动态的调整输入分辨率。这里采用的训练技巧是每隔 10 个 batch 将输入分辨率调整为 320, 352, …, 608 中的一种,最大的分辨率为 608 x 608,最小的分辨率为 320 x 320,这是动态调整的,这样能更好的适应不同尺度的检测对象。
1.8 Darknet-19
论文提出了 YOLOv2 的 backbone:darknet-19。当时的检测框架的 backbone 以 VGG 为主,因 VGG-16 具有强大的特征提取能力,最为受欢迎,但它开销巨大,需要 30.96 billion 浮点运算。而 YOLOv1 的 backbone 是基于 GoogleNet 的结构,模型前向复杂度降低到 8.52 billion operations。YOLOv2 则进一步优化,借鉴 NIN (Network in Network) 的思想,采用 1 x 1 和 3 x 3 卷积交替的形式,结合 BN 层来稳定训练,形成了 darknet-19 的 backbone,模型前向复杂度进一步降低至 5.58 billion operations。
来看一下 darknet-19 的模型结构:
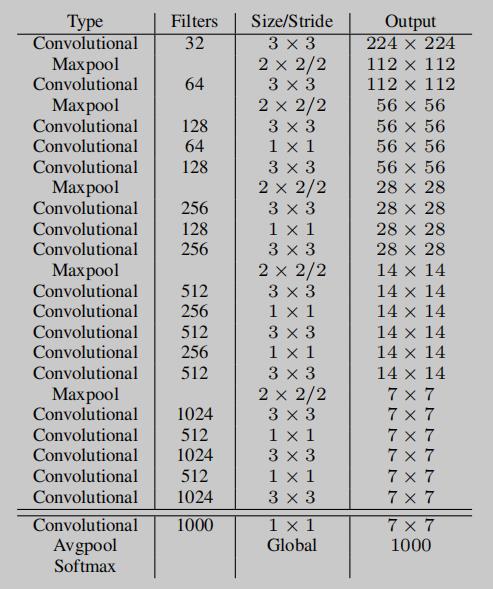
以上把 YOLOv2 的改进点说了一遍,下面进入实践环节。
2、YOLOv2 实践
以 darknet 训练 YOLOv2 为例,默认已准备好 darknet 环境和 VOC0712 数据集 (不会的可以查看我的上一篇)。
2.1 训练
YOLOv2 的训练指令和 YOLOv1 有一些不同,YOLOv1 的训练数据集路径和权重保存路径在代码中写死,而 YOLOv2 可以从指令传入,在 voc.data 配置中读取。
在 cfg 目录下建一个 yolov2 文件夹,并加入 voc.data、voc.names、yolov2_train.cfg (用于训练)、yolov2.cfg (用于推理)。最后形成的目录 tree 差不多是这样:
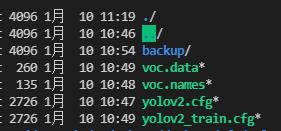
其中 voc.names 中是类别名字,而 voc.data 差不多长这样:
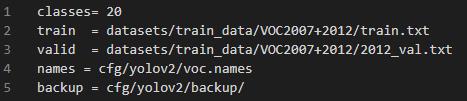
然后执行训练:
./darknet detector train cfg/yolov2/voc.data cfg/yolov2/yolov2_train.cfg -gpus 0
会有对应的 loss 变化图,可以直观的看收敛的怎么样:
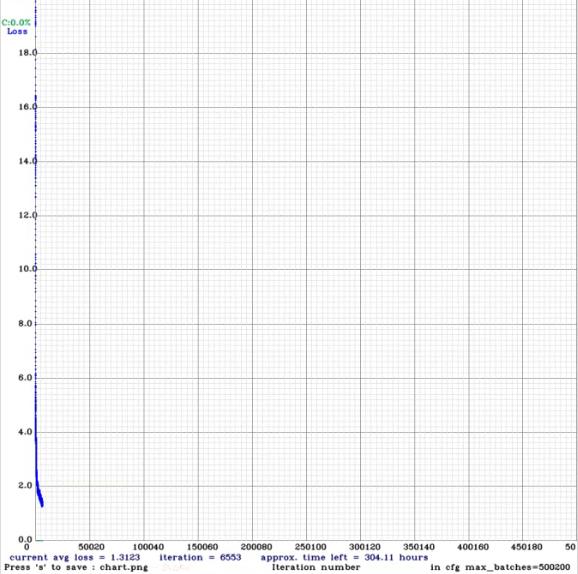
在 YOLOv2 的训练过程中,它会自行调整输入的分辨率,然后等训练完了可以看下效果。
2.2 验证
归莱!时隔 941 天后今天克莱重回 NBA 赛场,那就做一个克莱检测吧~
今日五佳球,克莱隔扣,宣告王者归来。执行检测 (由于训练数据集是 VOC0712,和 NBA 的检测场景还是差别很大,所以检测效果一般般):
./darknet detector demo cfg/voc.data cfg/yolov2/yolov2.cfg cfg/yolov2/backup/yolov2.weights data/nba_kelai.mp4
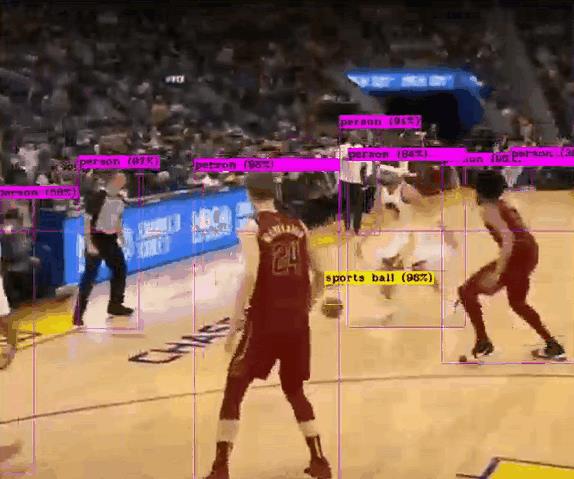

是不是有老科那味儿了~
好了,以上主要分享了克莱复出,顺便分享了 YOLOv2 算法原理和实践,希望我的分享能对你的学习有一点帮助。
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型训练目标检测实现分享二:听说克莱今天复出了?详解 YOLOv2 算法与克莱检测的主要内容,如果未能解决你的问题,请参考以下文章