Azure Data PlatformETL工具——Azure Data Factory “复制数据”工具(云中复制)
Posted 發糞塗牆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Azure Data PlatformETL工具——Azure Data Factory “复制数据”工具(云中复制)相关的知识,希望对你有一定的参考价值。
本文属于【Azure Data Platform】系列。
接上文:【Azure Data Platform】ETL工具(1)——Azure Data Factory简介
本文演示如何使用ADF 从Azure Blob Storage中复制数据到Azure SQL DB。
在上一文中,我们创建好了ADF服务, 下面演示一下最简单的ADF 操作,除了ADF 服务之外,本文将创建一个Azure Blob Storage和Azure SQL Database 作为数据传输的演示。
在ADF中,有一个“复制数据”工具,借助这个工具,可以把在不同地方(本地或云)的不同数据源中实现数据的传输。基本上支持你能想到的所有常规数据源,具体列表以这里为准:Supported data stores and formats。
这里引入一个概念:Integration Runtime (IR),集成运行时。
ADF当前支持3类IR:
- Azure Integration Runtime:主要涉及公网访问。
- Self-Hosted Integration Runtime: 用于源或目表存在本地数据源的访问。
- Azure SSIS Integration Runtime: 用于运行SSIS包。
ADF使用IR在不同的网络环境下安全地运行复制活动。并且选择最接近的可用区域作为数据源。可以理解为IR搭起了复制活动(copy activity)和链接服务(Linked services)的桥梁。
环境准备
接下来演示一个很常见的需求,从Azure Blob复制数据到SQL DB。这是基于云环境(Azure)内部的数据复制操作。为此,我们快速创建一个Azure Blob Storage和SQL DB,能用默认的就用默认。
创建Blob Storage
本系列假设你已经会基本的创建Azure服务,并且由于预算有限,会尽可能选择低配的服务。 创建Blob Storage如下图所示:
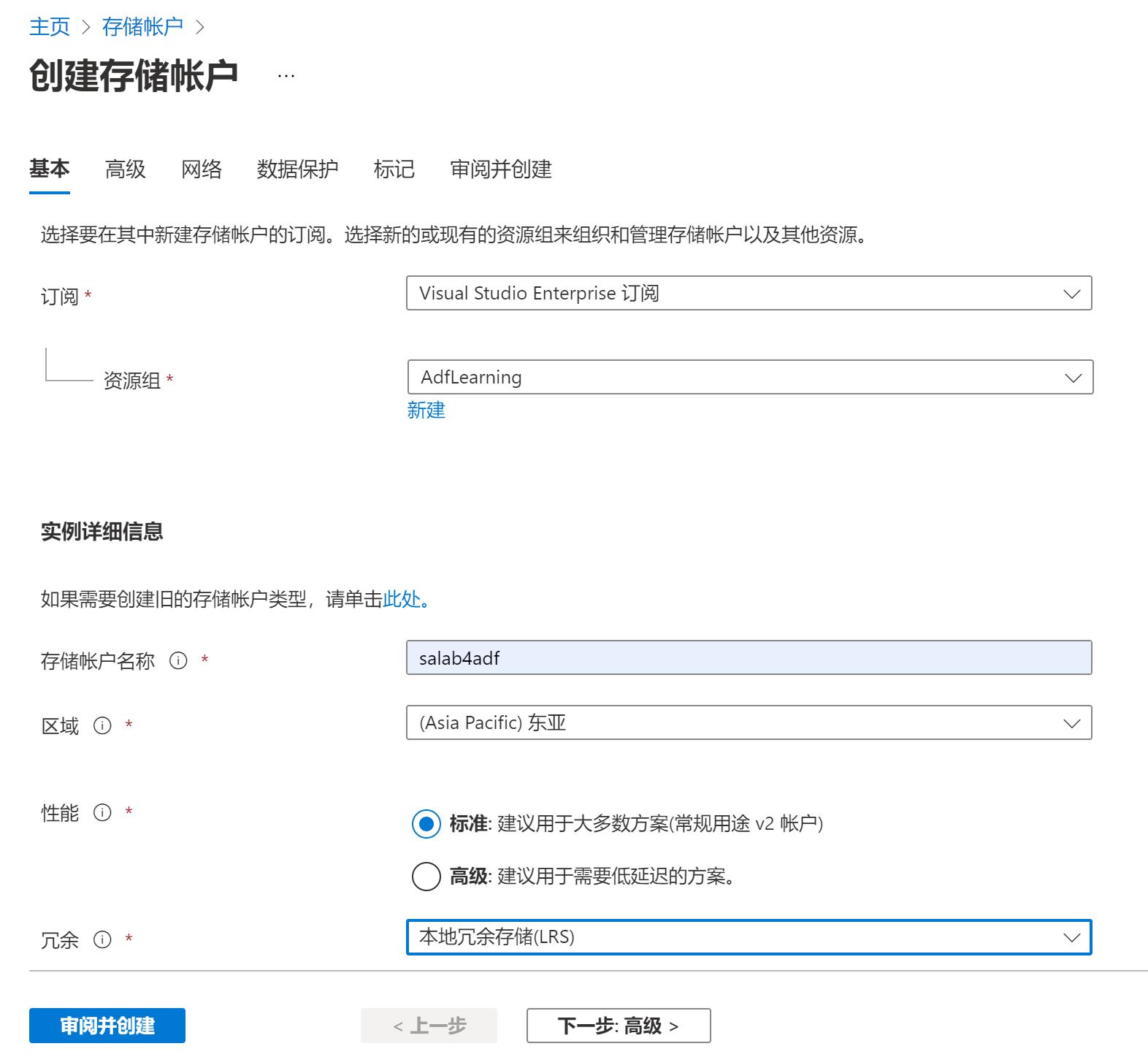
创建SQL DB
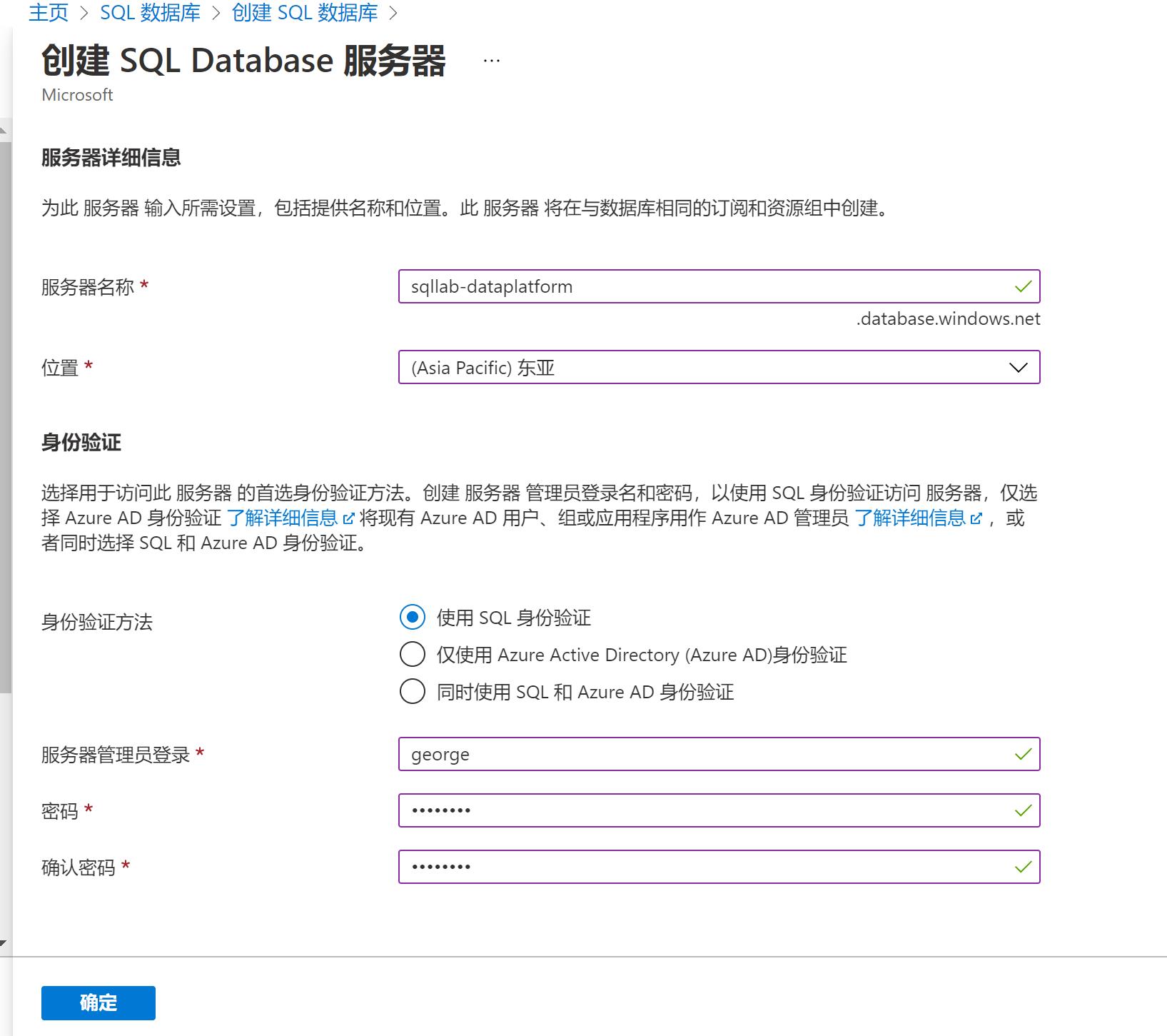
同样这里选择了最便宜的配置:
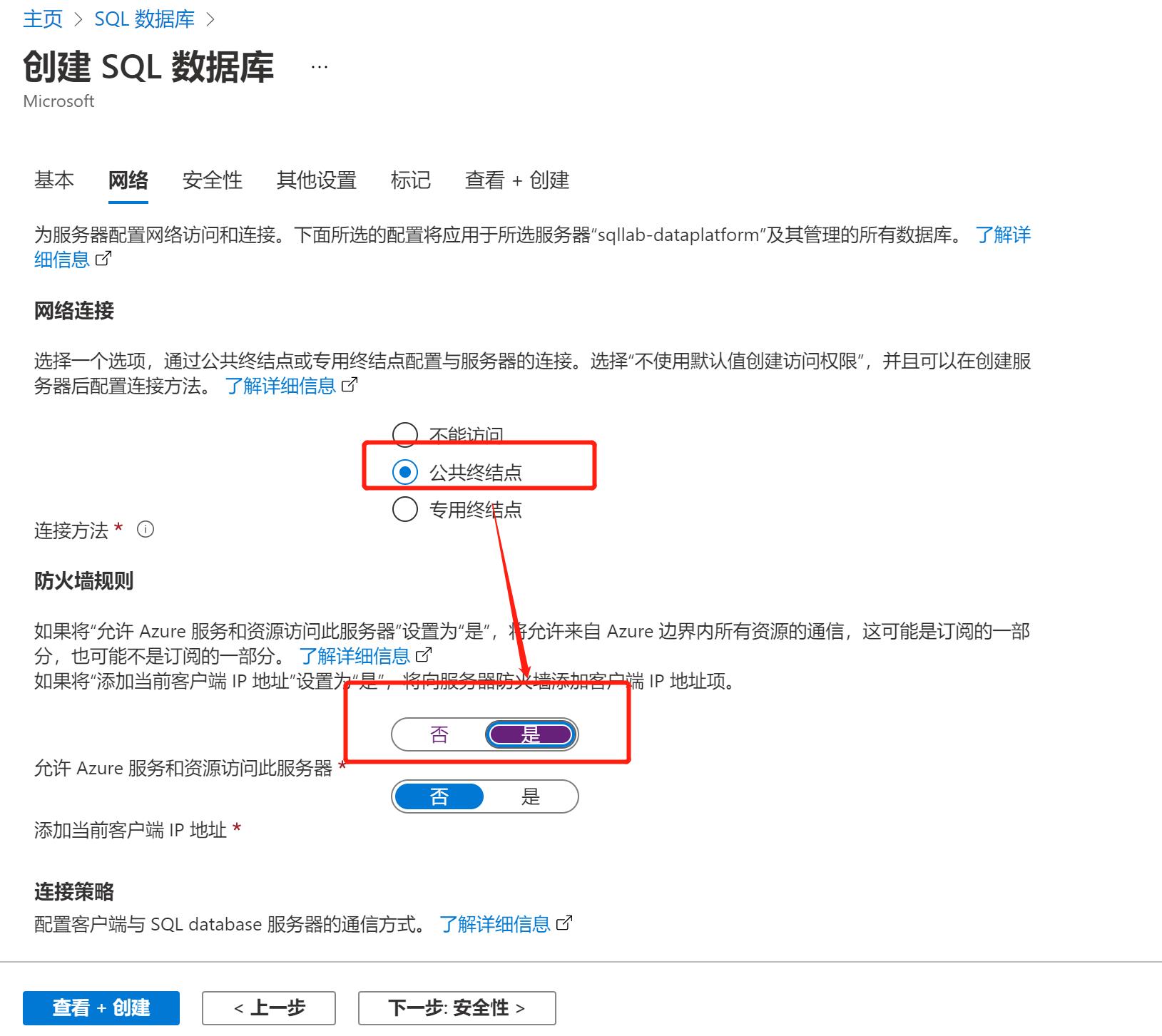
注意“网络”选项页中,默认是“不能访问”, 为了让Blob Storage能够访问DB,这里选择“公共终结点”然后在“防火墙规则”中对“允许Azure服务和资源访问此服务器”选择“是”
等资源创建好之后,我们就可以开始进行操作。
操作演示
首先我们连上DB 并创建一个测试表“ADFLab”, 如下图所示:
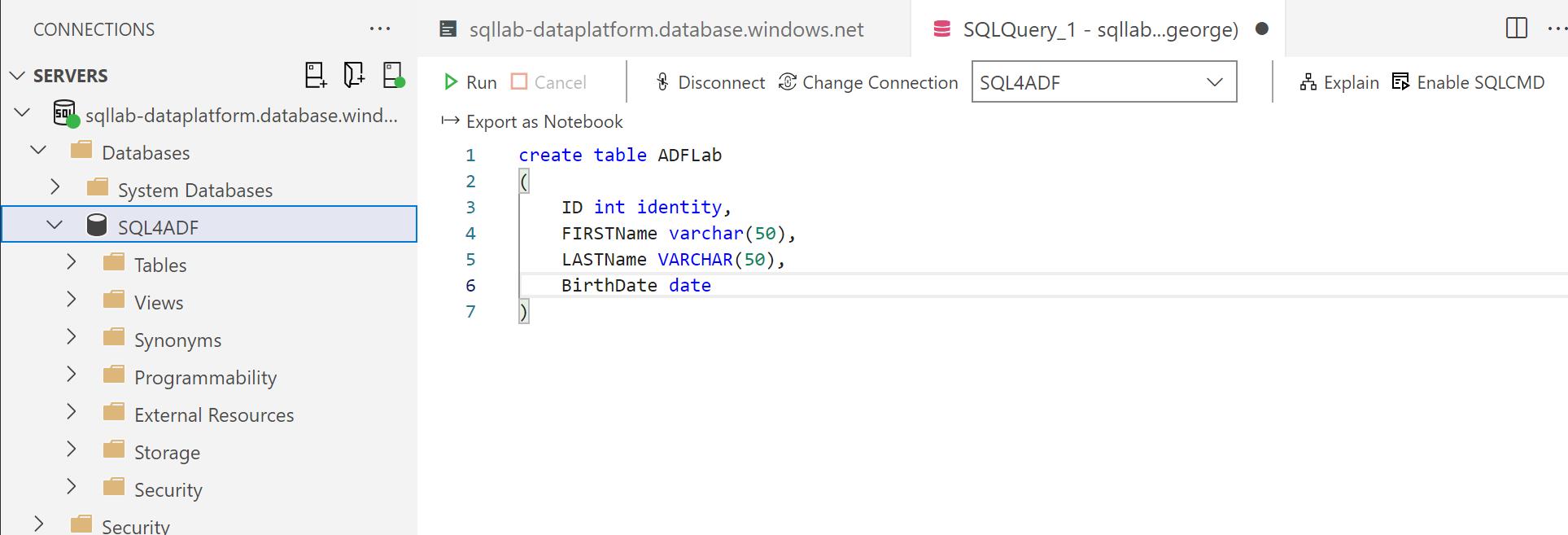
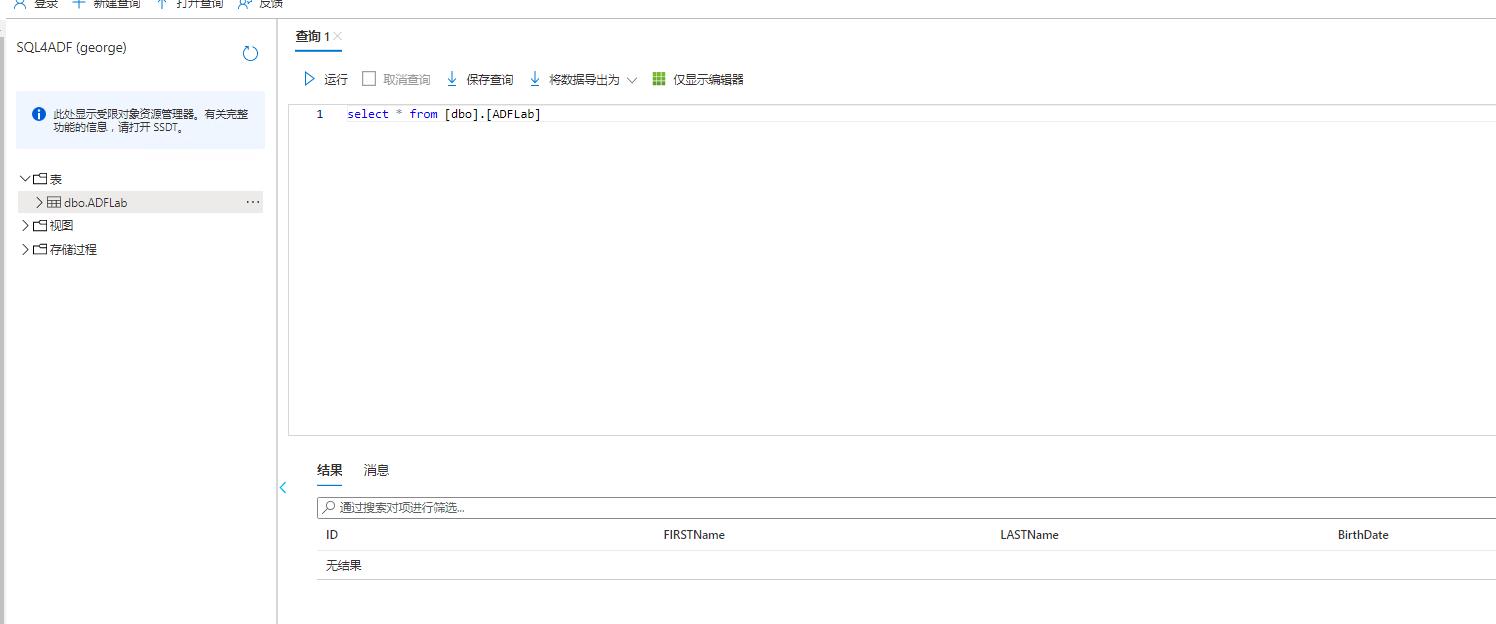
检查表中是否有数据:
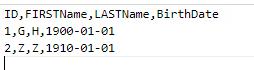
然后准备一个测试文件并上传到Blob Storage上。这是一个txt文件,并且以逗号“,”作为分隔符,在后面会看到,之所以用逗号,是因为复制数据这个工具默认就是以逗号为分隔符,如果使用其他作为分隔符,需要额外配置,文件内容如下:
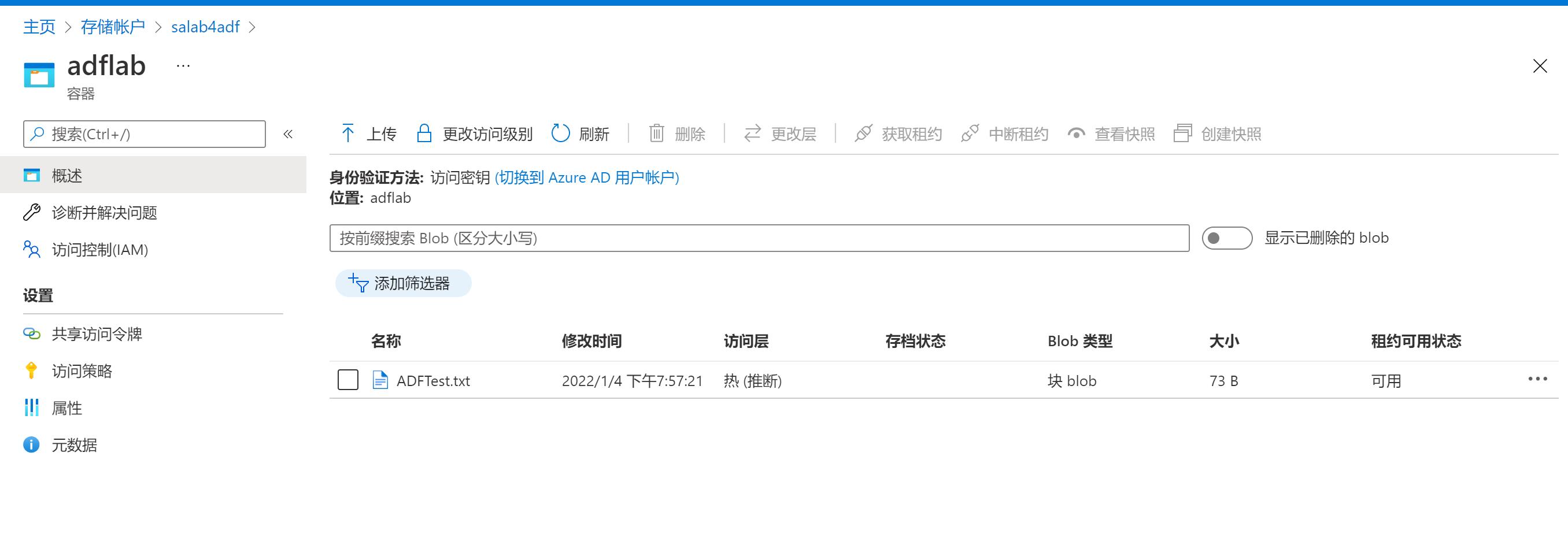
上传到Blob Storage的container(adflab)中:
做好准备之后,就开始ADF的开发工作了。
ADF 开发
要使用复制数据工具,首先创建Pipeline(管道),用于将blob container中的文件复制到Azure SQL DB中。
步骤1: 打开数据工厂的工作室:
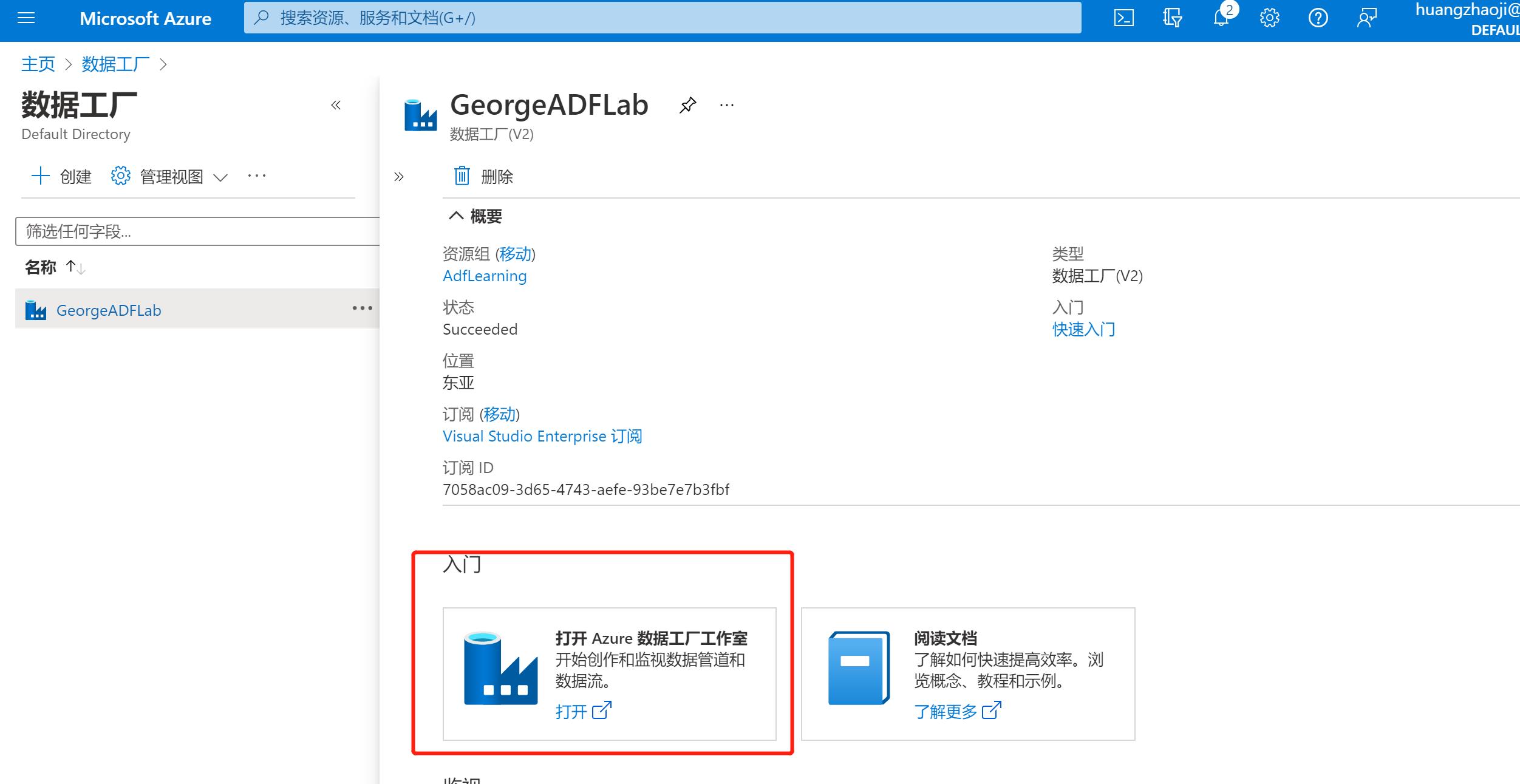
步骤2:点击【新建】并选择【管道】:
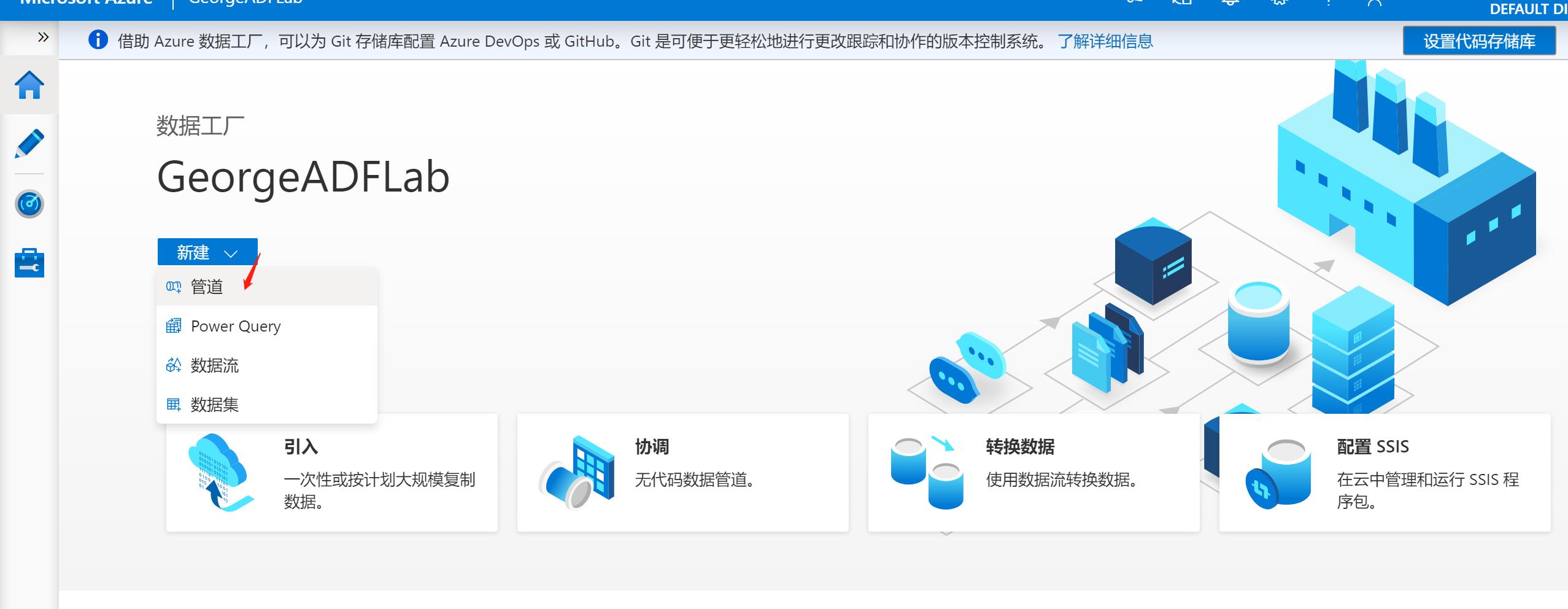
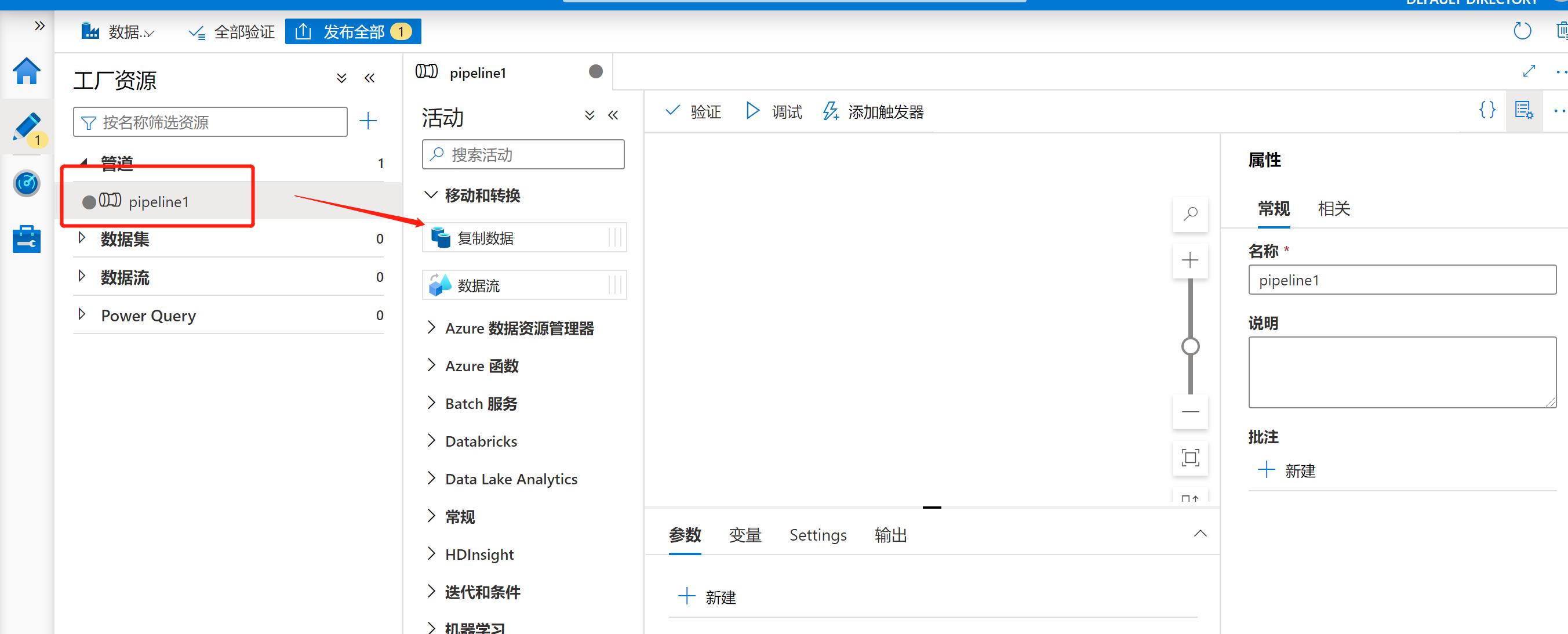
步骤3:点击新建的管道(pipeline1), 把下图中的【复制数据】拖动到右边空白处,注意这里由于时间关系,没有对每一步做很好的命名,在正式环境中,必须要以有意义的标识作为各个组件的命名。
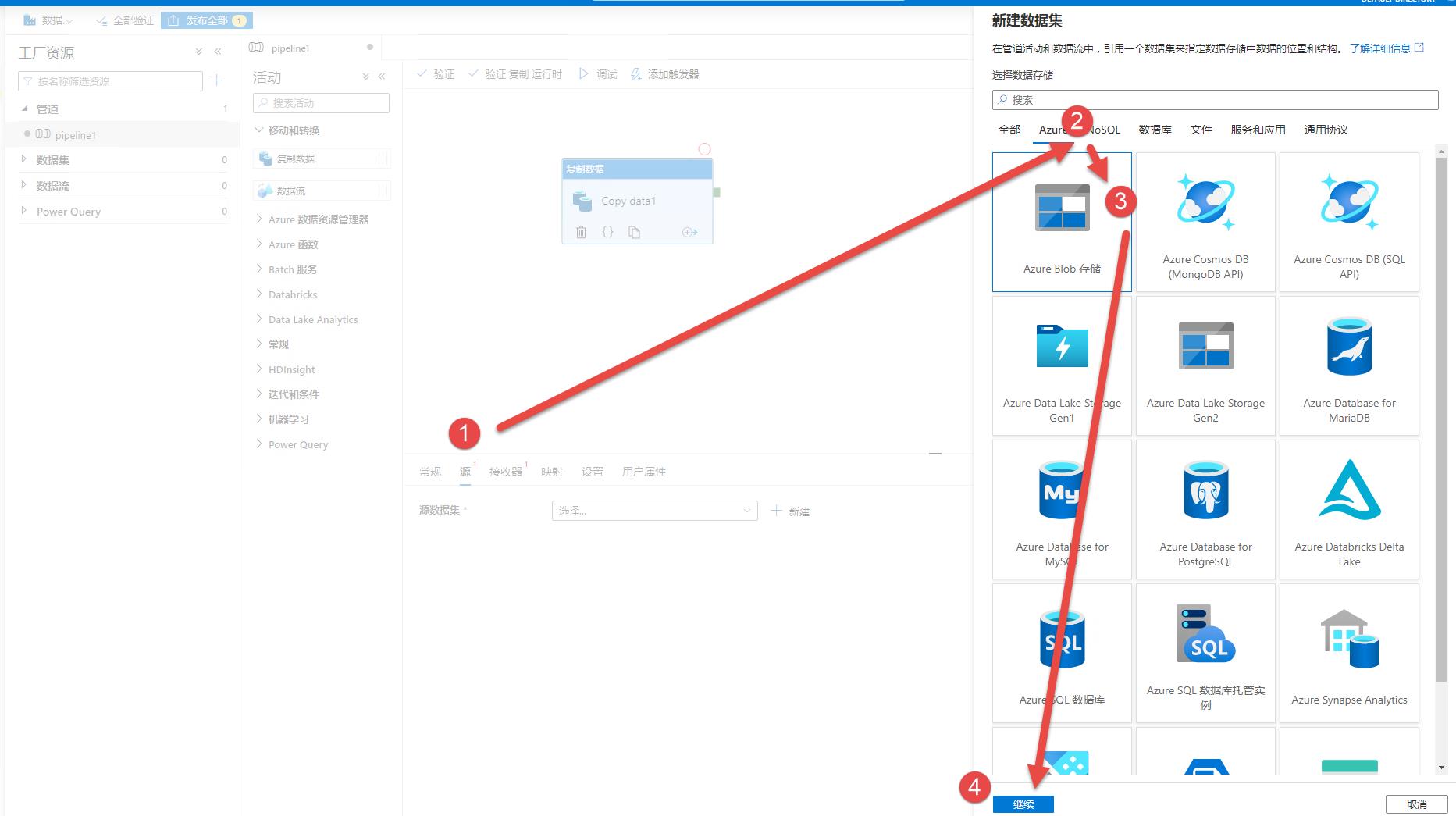
步骤4:配置源,按下图顺序点击,选择Blob Storage做为【源】:
步骤5:选择数据的格式类型,因为这次使用的是txt文件,所以选择DelimitedText,然后点击下方的【继续】:
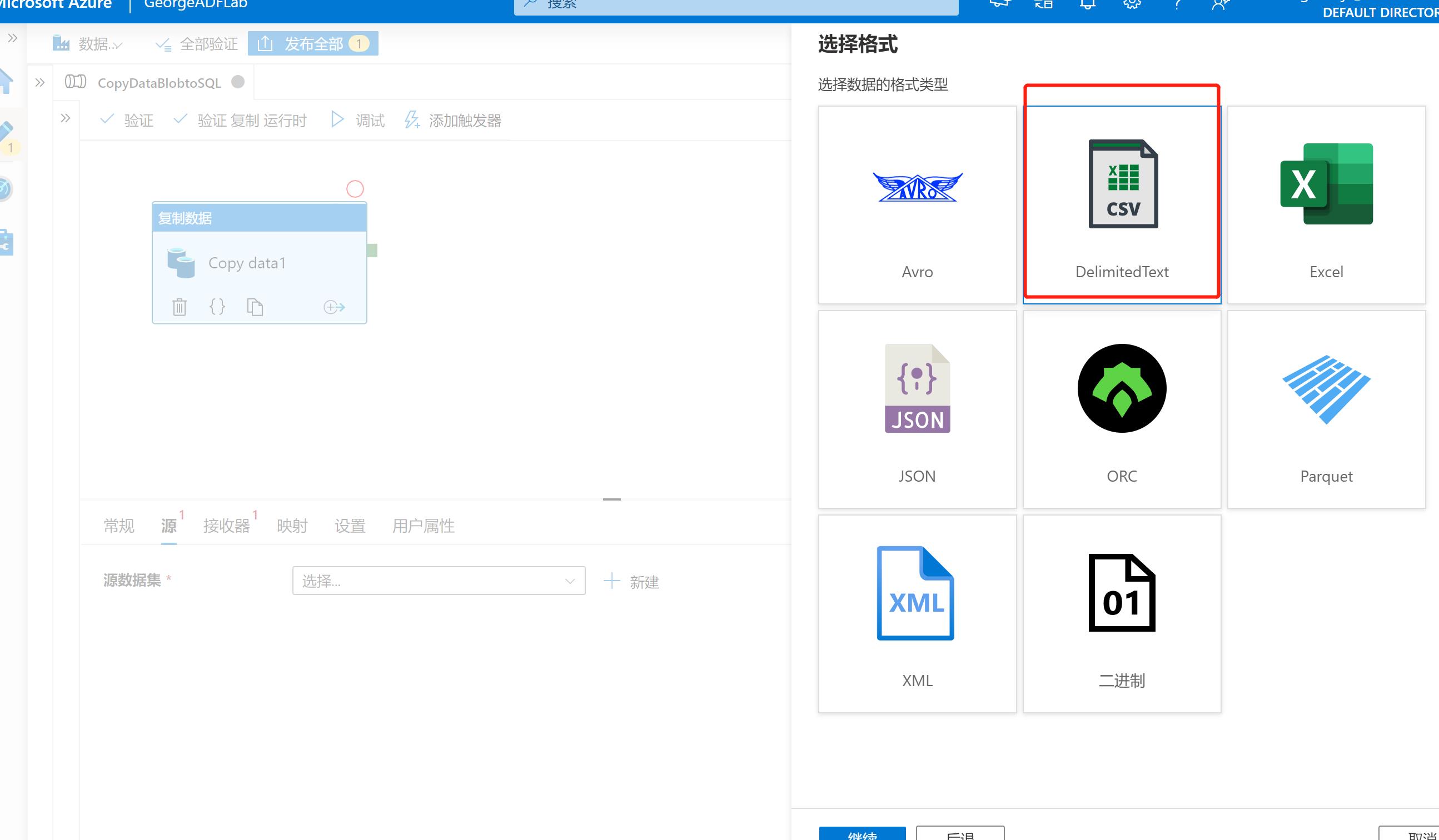
步骤6:选择或新建链接的服务(linked service),由于是新环境,所以这里新建一个:
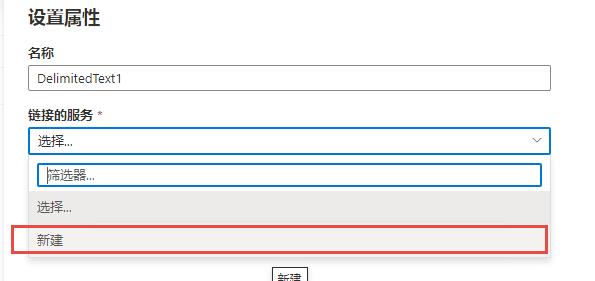
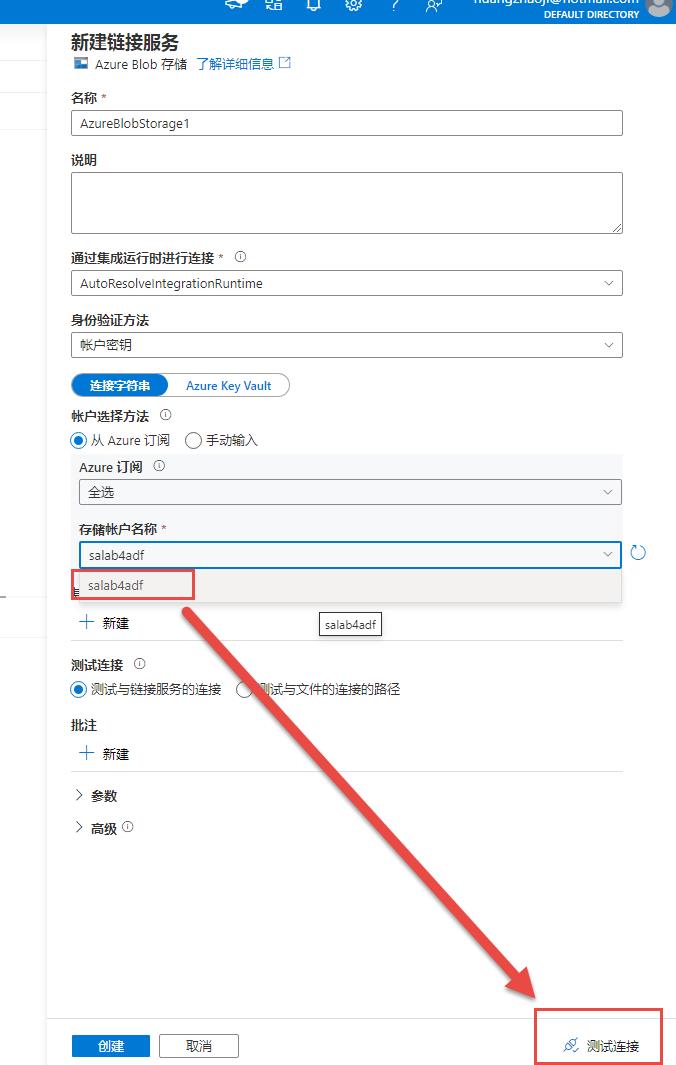
步骤7:新建链接服务并测试连接:
测试通过后,可以点击下图红框部分以图形化的形式查看容器内部的文件:
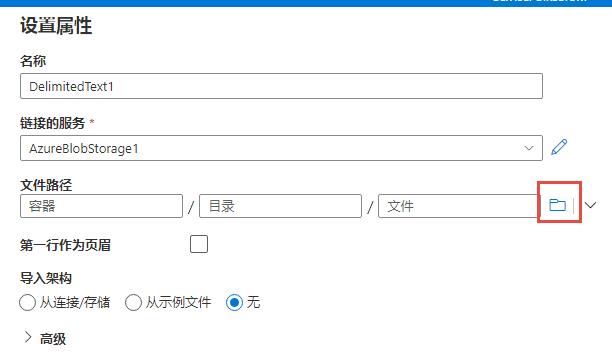
我们可以看到里面有问题,同时也意味着这个连接是成功的,选择这个文件作为数据源:
配置好源之后,点击【预览数据】,查看数据的内容,也可以作为验证过程:
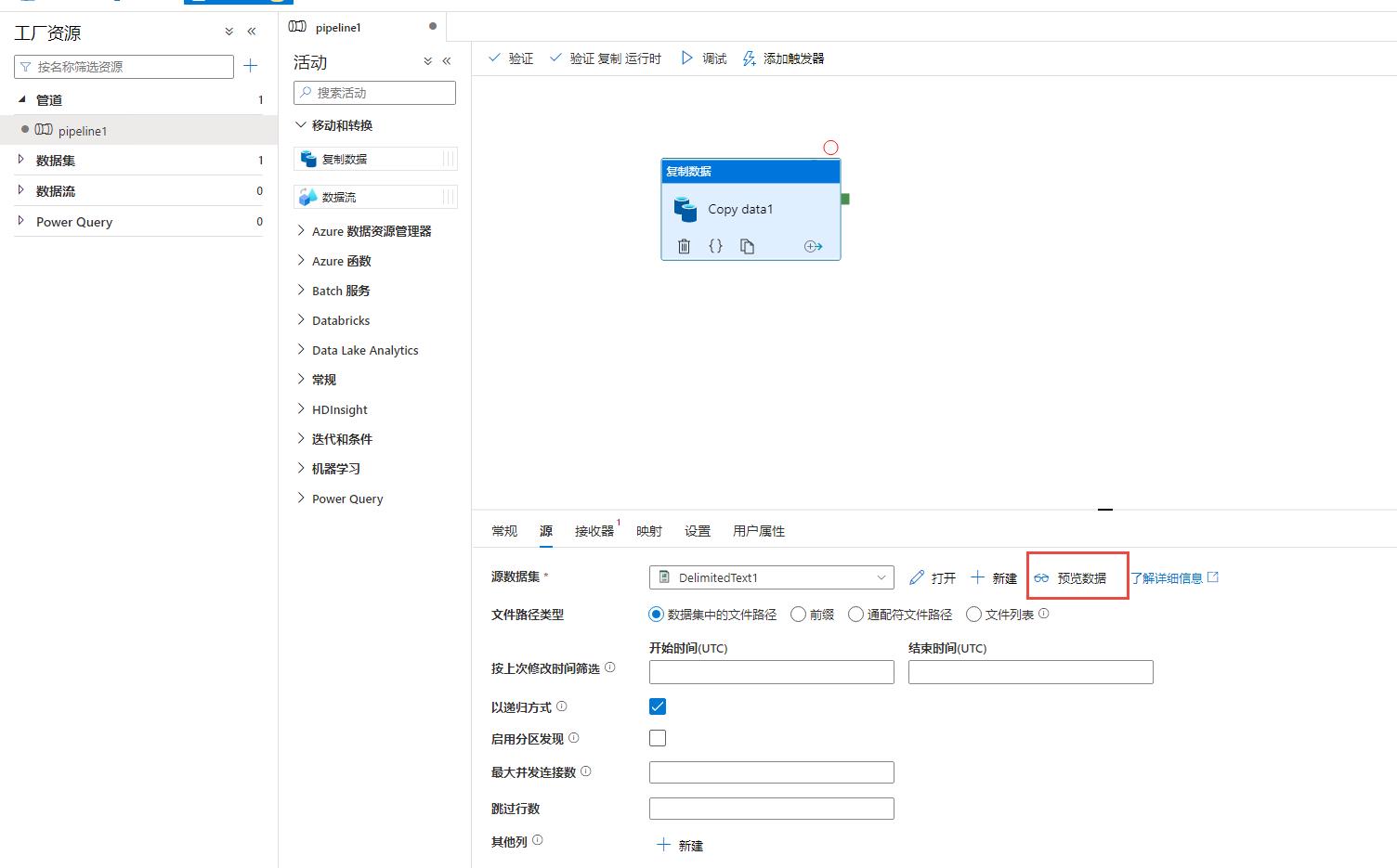
步骤8:配置【接收器】,也就是目标,按下图所示,选择新建然后选择Azure SQL 数据库:
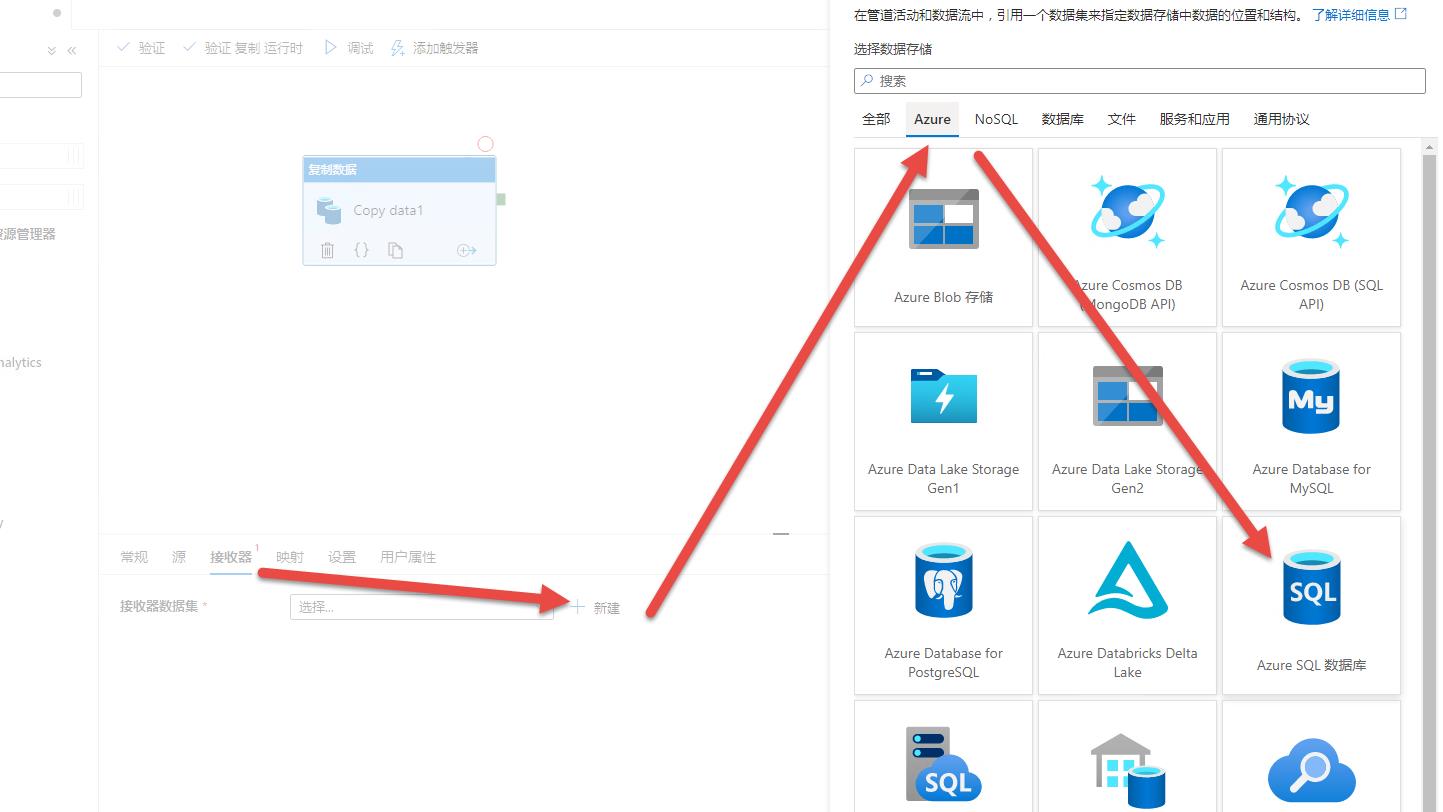
步骤9:跟配置源类似,填写必要的信息然后点击测试连接:
下图是配置后的样子:
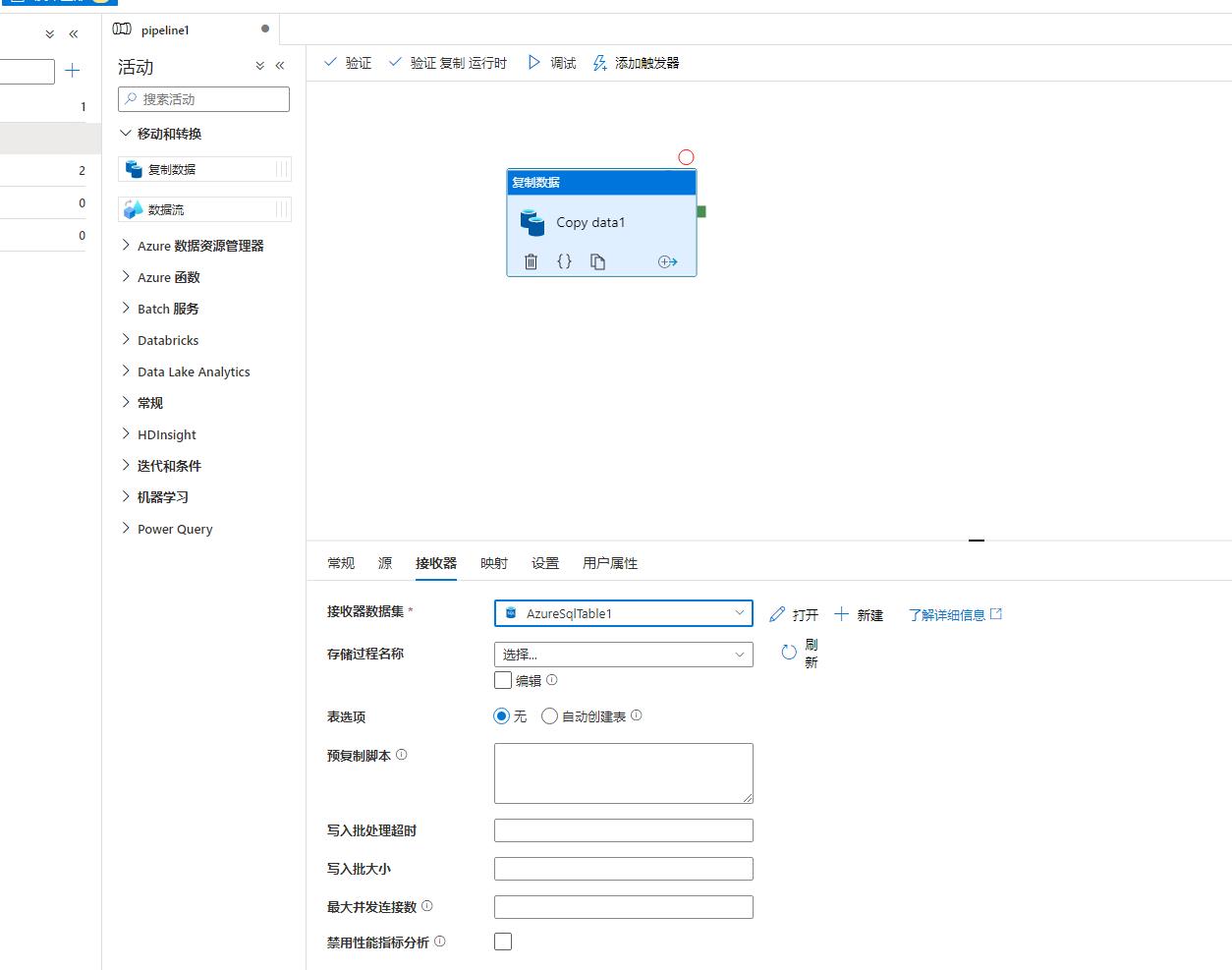
步骤10:配置映射,映射是指如何解析源中文件(或其他格式)结构,本例中,就是让ADF解析Blob上文件结构并配置数据库表的过程:
步骤11:配置【设置】,这里暂时保留默认设置即可:
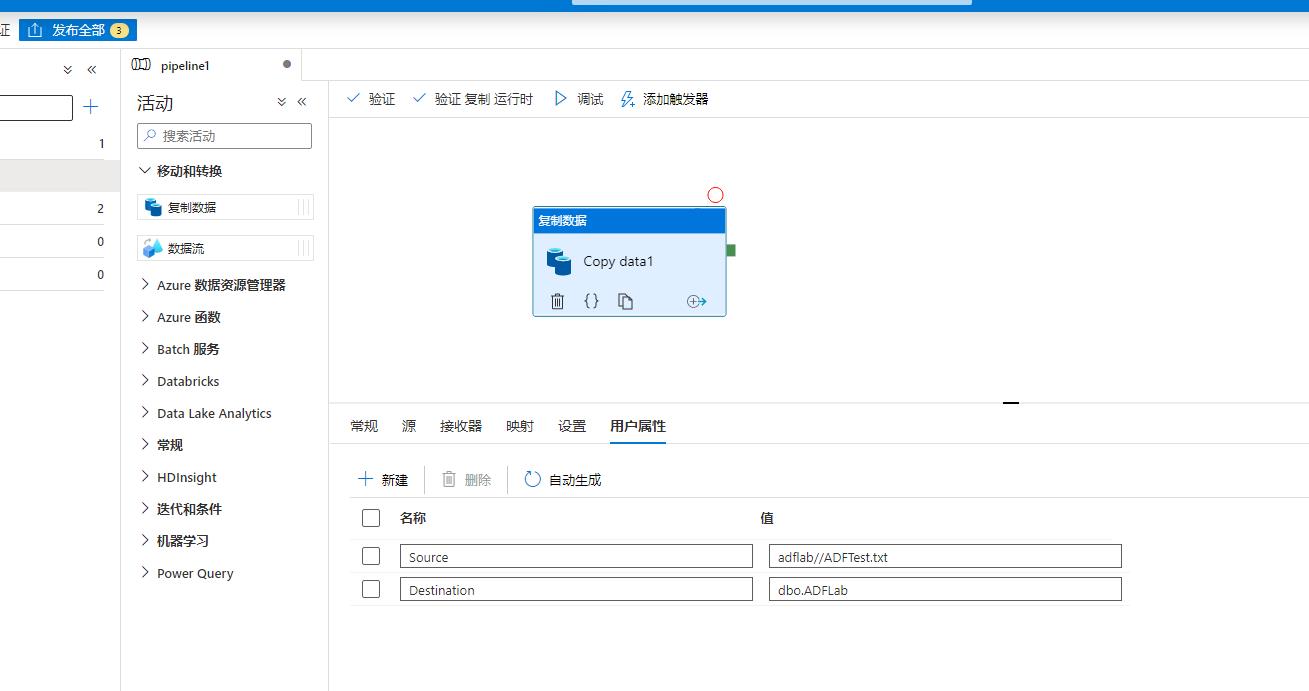
步骤12:配置【用户属性】,用户属性处点击【自动生成】可以加载一些属性信息,同时还可以自己添加必要信息。
步骤13:然后我们验证并调试一下:
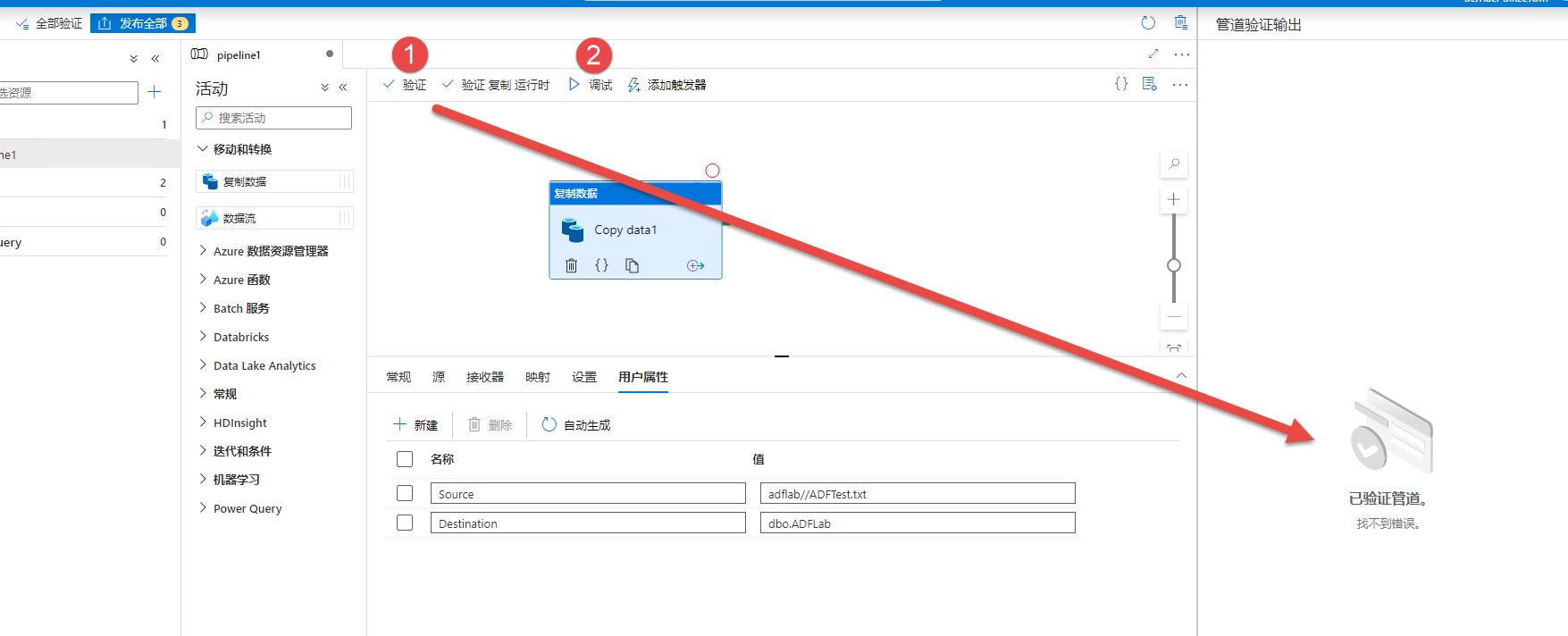
在调试过程中报错了,查看信息可以发现数据类型没对应好:
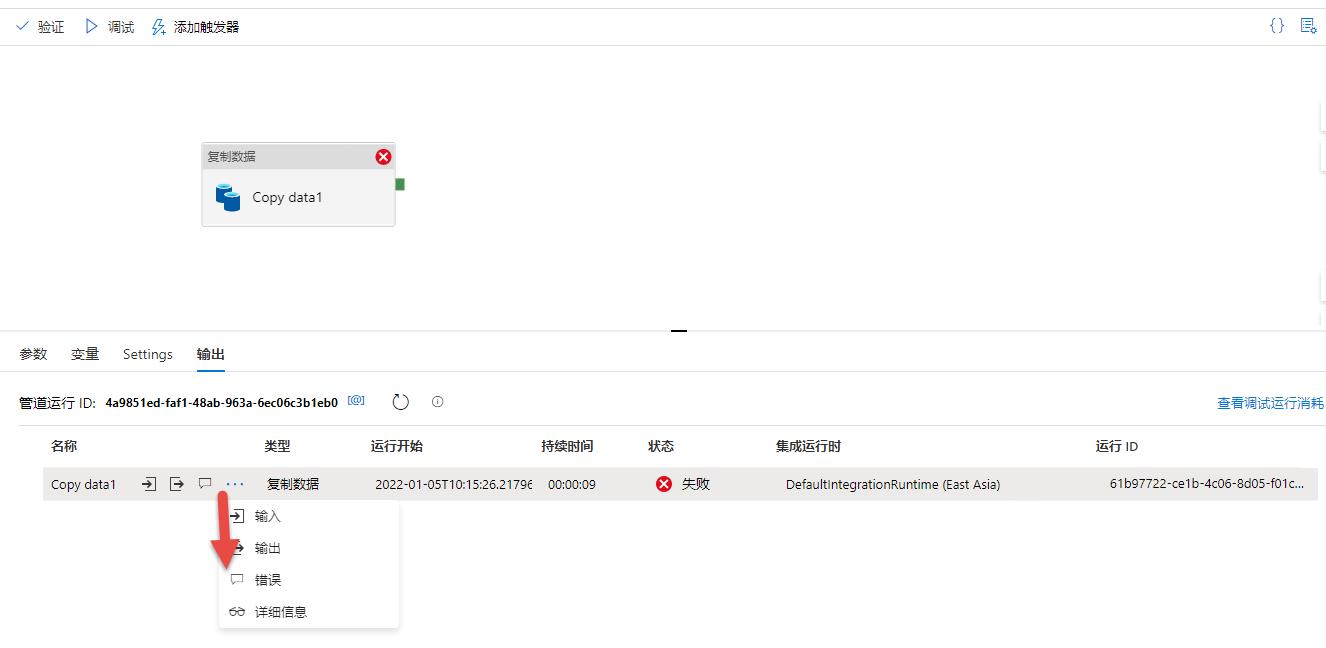
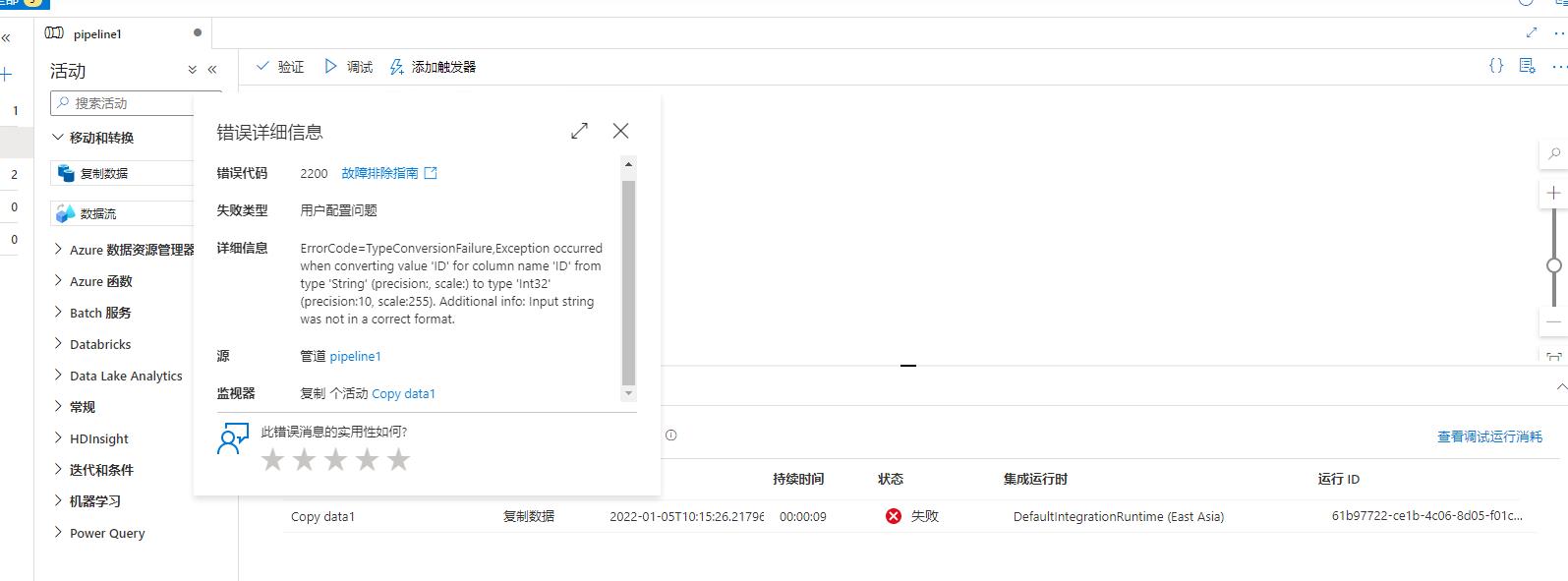
错误信息如下:
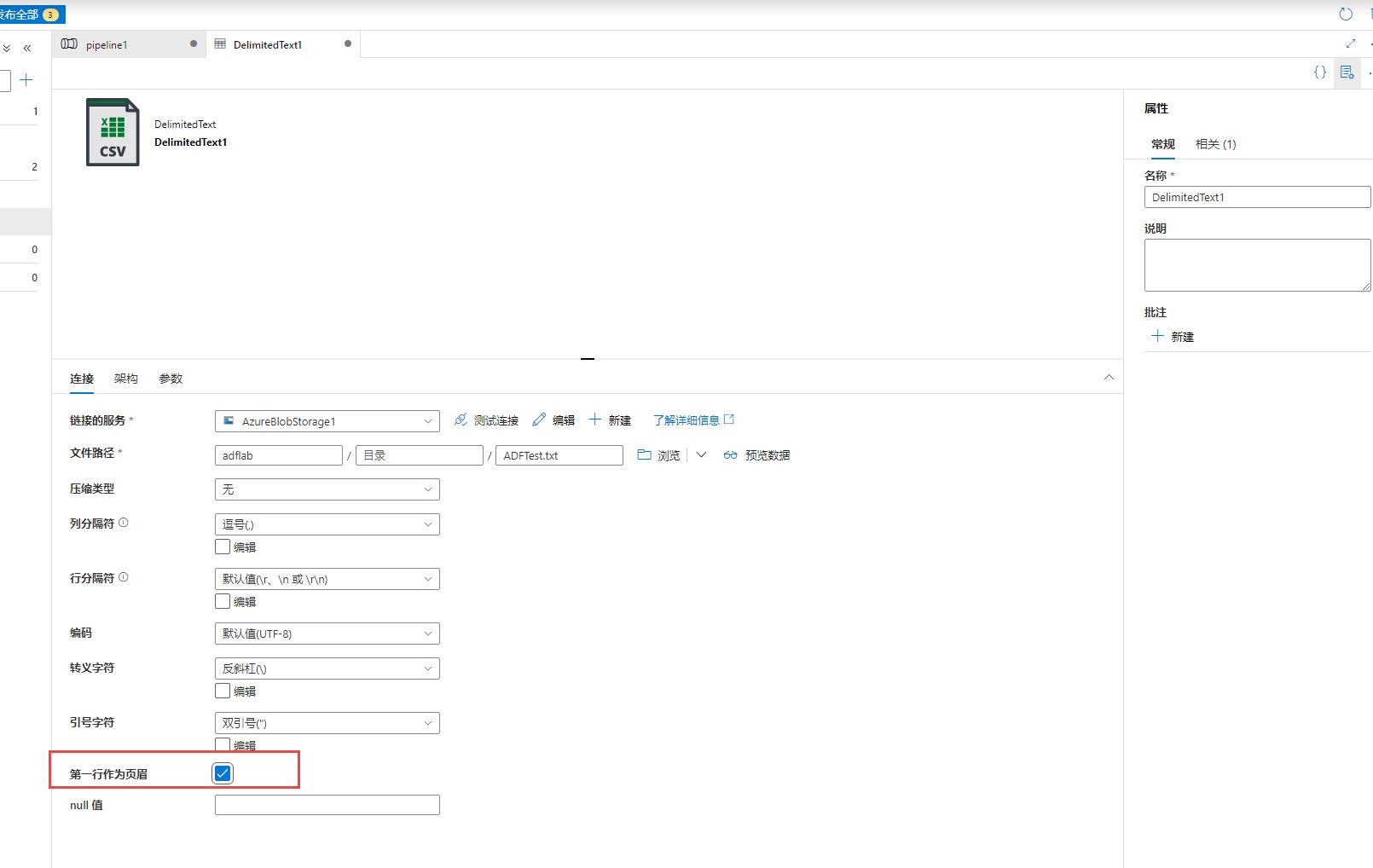
那么回过头看配置:下图原本是没有勾选的,这次勾选掉:
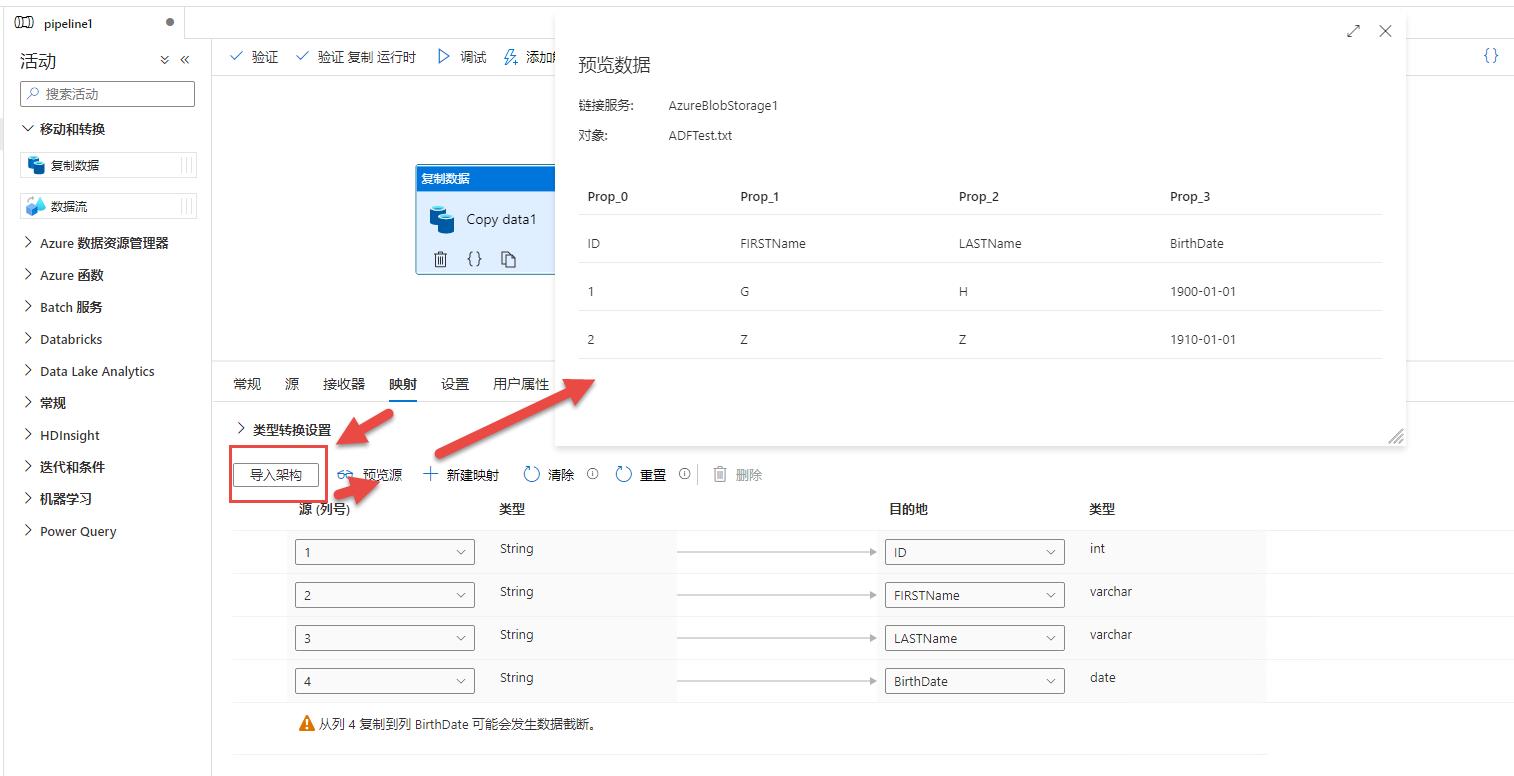
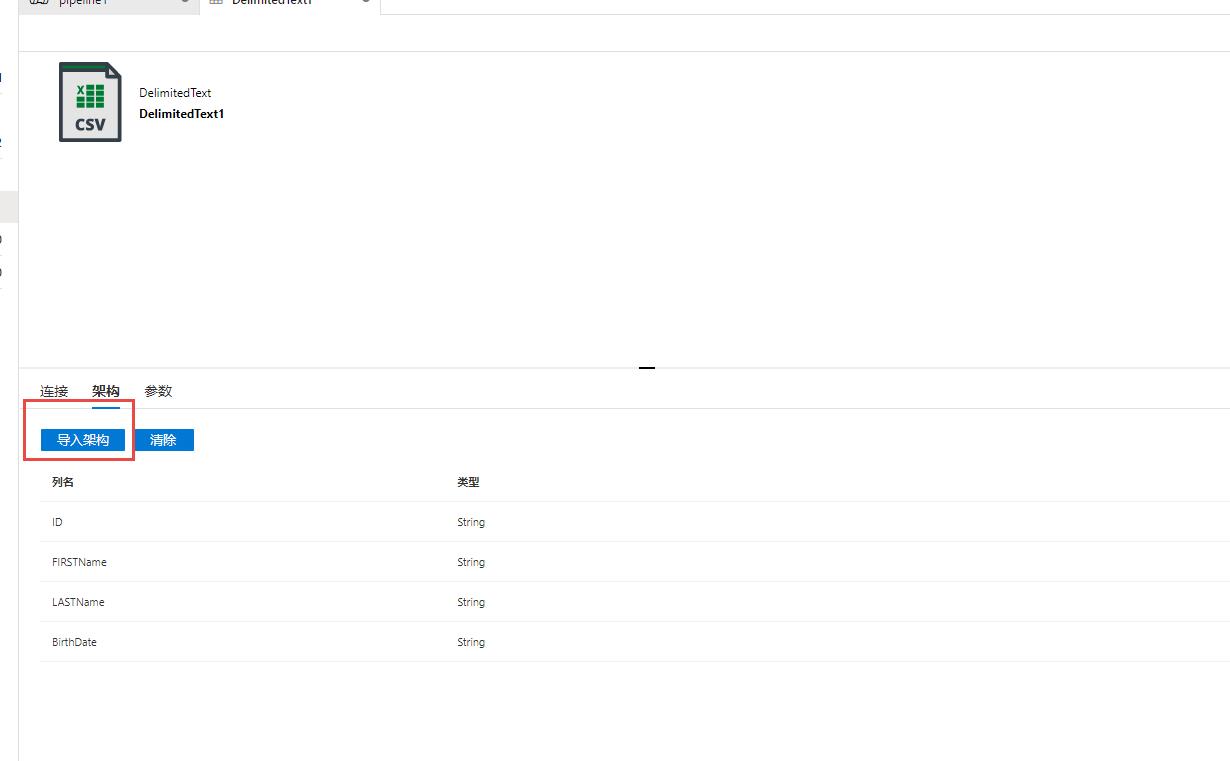
点击【架构】,然后点击【导入架构】,刷新数据源分析结果,可以看到【列名】已经读出来了:
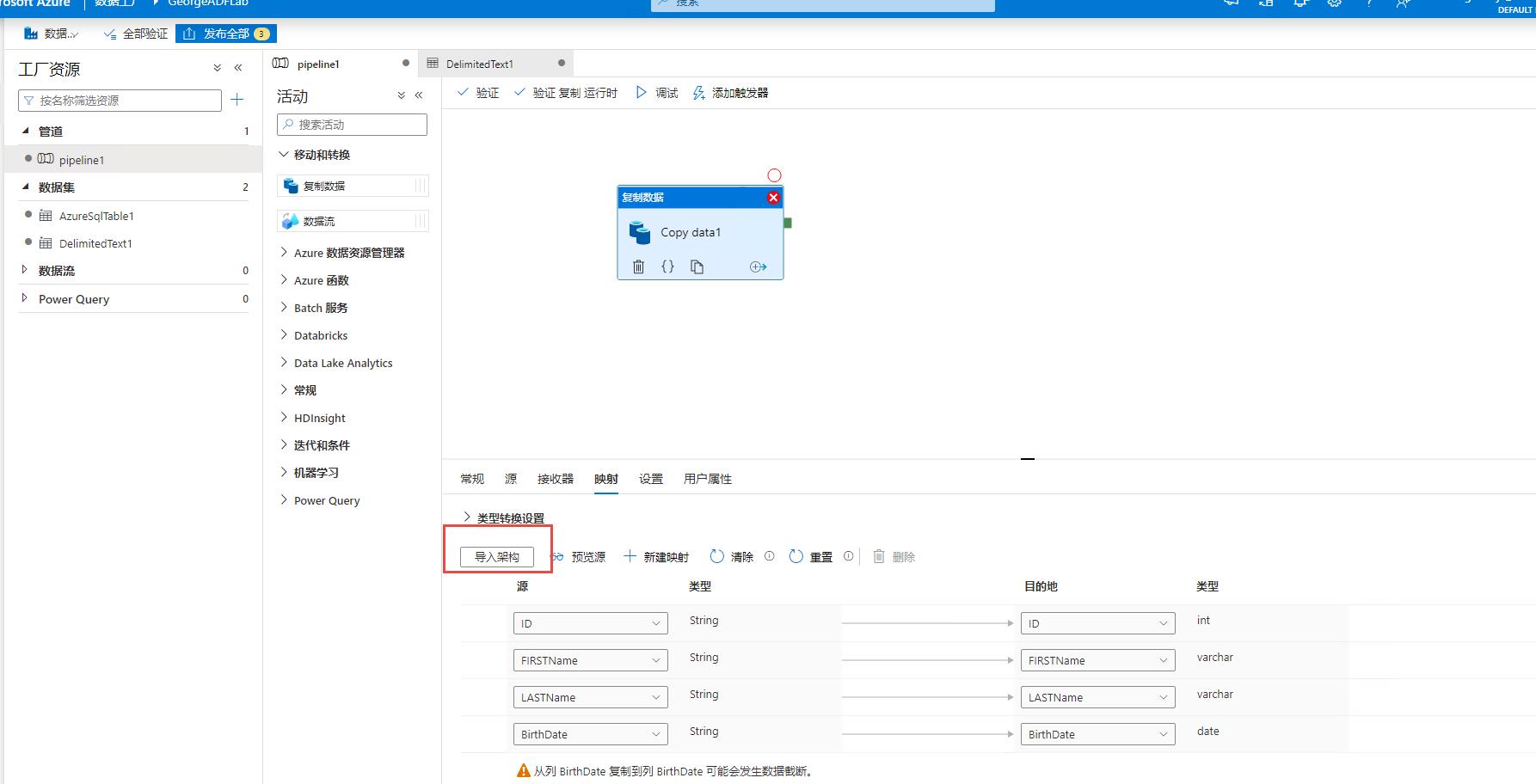
接下来回到【映射】中,再次【导入架构】,刷新结构,可以看到源也更新了:
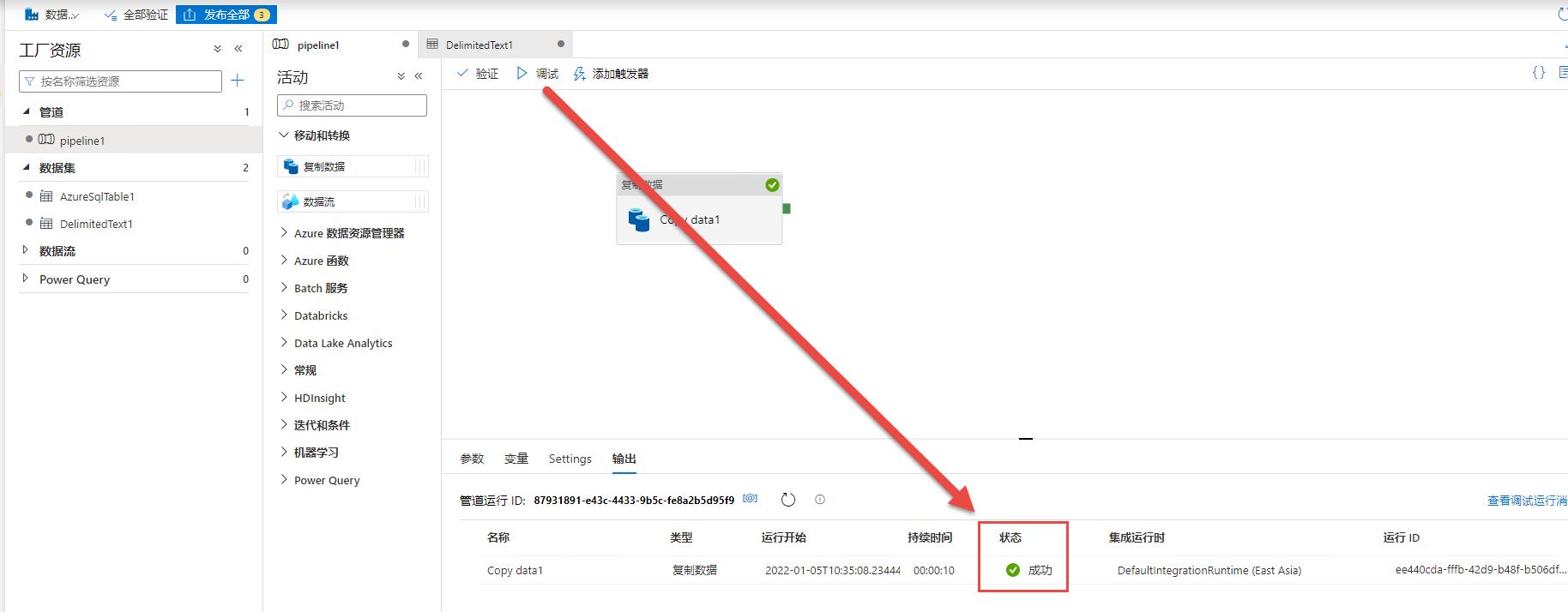
接下来再次调试,结果成功了。
最后一步就是发布程序: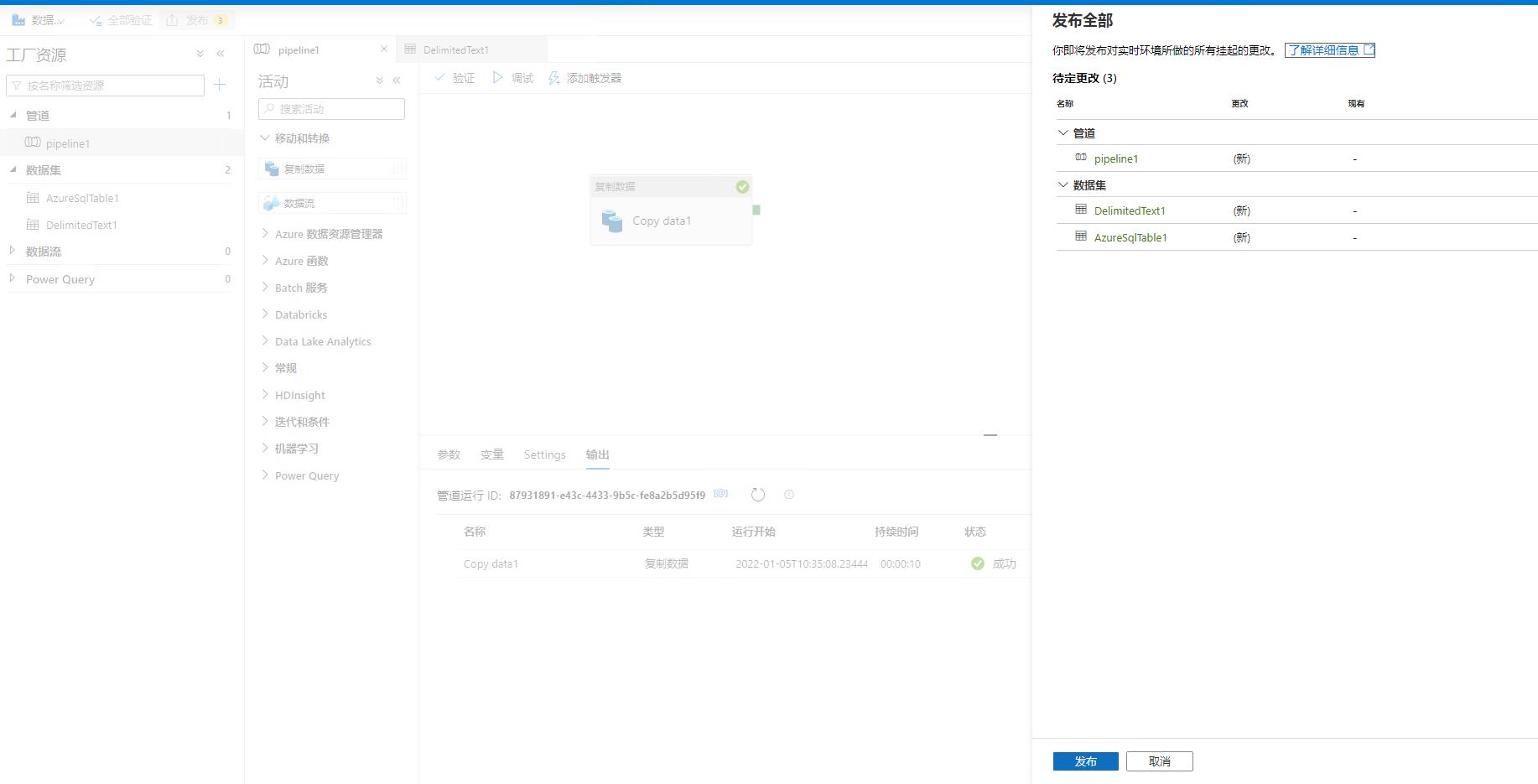
然后回到数据库中查询结果,可以看到已经成功导入数据库:
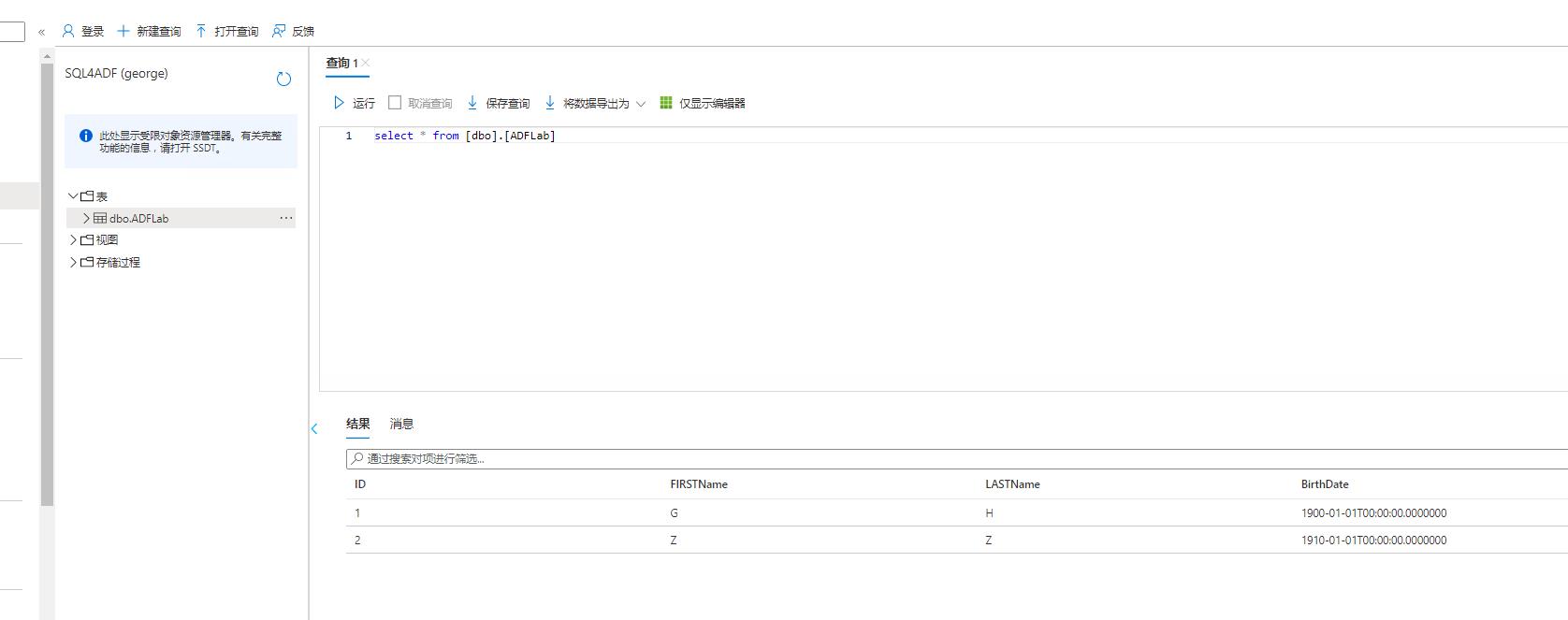
到目前为止,已经把一个Blob Storage上的简单文件加载进SQL DB中,这个过程很简单,很理想化,但在企业使用中各种环境要求会带来很多额外配置, 比如身份验证,网络连通等等。
不过作为入门的第一篇实操,这种程度我觉得应该够了。 从本次实操中,作为ETL入门者,很多细节部分还需要多研究,多实践,但是不应该因为第一次碰到各种问题就气馁。
下一章会尝试从本地环境复制数据到云上。
以上是关于Azure Data PlatformETL工具——Azure Data Factory “复制数据”工具(云中复制)的主要内容,如果未能解决你的问题,请参考以下文章
Azure Data PlatformETL工具(19)——Azure Databricks
Azure Data PlatformETL工具(20)——创建Azure Databricks
Azure Data PlatformETL工具(20)——创建Azure Databricks
Azure Data PlatformETL工具——重新认识Azure Data Factory