每日一题:3个几乎面试必考的SQL数据分析题(含数据和代码)
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每日一题:3个几乎面试必考的SQL数据分析题(含数据和代码)相关的知识,希望对你有一定的参考价值。
每日一题 精选常考面试题,将其汇总成专栏,利用零碎时间为职业保驾护航,建议大家独立思考答题。
大家好,在数据类岗位招聘过程中,经常会考察求职者的SQL能力,这里整理了3个常考的SQL数据分析题,按照由简单到复杂排序,一起来测试下你掌握了么?
注:文末提供面试技术交流群
题目1:找出每个部门工资第二高的员工
现有一张公司员工信息表employee,表中包含如下4个字段。
employee_id(员工ID):VARCHAR。
employee_name(员工姓名):VARCHAR。
employee_salary(员工薪资):INT。
department(员工所属部门ID):VARCHAR。
employee表的数据如下表所示。
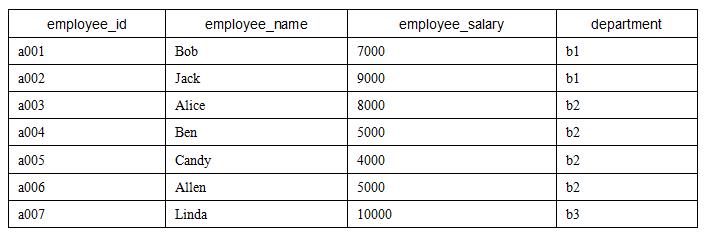
还有一张部门信息表department,表中包含如下两个字段。
department_id(部门ID):VARCHAR。
department_name(部门名称):VARCHAR。
department表的数据如下表所示。

数据导入的代码如下:
DROP TABLE IF EXISTS employee;
CREATE TABLE employee(
employee_id VARCHAR(8),
employee_name VARCHAR(8),
employee_salary INT(8),
department VARCHAR(8)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO
employee (employee_id,employee_name,employee_salary,department)
VALUE ('a001','Bob',7000,'b1')
,('a002','Jack',9000,'b1')
,('a003','Alice',8000,'b2')
,('a004','Ben',5000,'b2')
,('a005','Candy',4000,'b2')
,('a006','Allen',5000,'b2')
,('a007','Linda',10000,'b3');
DROP TABLE IF EXISTS department;
CREATE TABLE department(
department_id VARCHAR(8),
department_name VARCHAR(8)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO
department (department_id,department_name)
VALUE ('b1','Sales')
,('b2','IT')
,('b3','Product');
问题:查询每个部门薪资第二高的员工信息。
输出内容包括:
employee_id(员工ID)
employee_name(员工姓名)
employee_salary(员工薪资)
department_id(员工所属部门名称)
结果样例如下图所示。

可供参考的解题思路: 使用窗口函数根据部门ID分组,在组内按照员工薪资降序排列并记为ranking,然后将该处理后的表和部门信息表进行内连接,从而把部门名称关联进来,最后在连接后的表上使用ranking=2作为薪资第二高的条件进行WHERE筛选,选择需要的列,即可得到结果。
涉及知识点: 窗口函数、子查询、多表连接。
本题的SQL代码如下,供读者参考:
SELECT a.employee_id
,a.employee_name
,a.employee_salary
,b.department_id
FROM
(
SELECT *
,RANK() OVER (PARTITION BY department ORDER BY employee_salary DESC) AS ranking
FROM employee
) AS a
INNER JOIN department AS b
ON a.department = b.department_id
WHERE a.ranking = 2;
题目2:网站登录时间间隔统计
现有一张网站登录情况表login_info,该表记录了所有用户的网站登录信息,包含如下两个字段。
user_id(用户ID):VARCHAR。
login_time(用户登录日期):DATE。
login_info表的数据如下表所示。

数据导入的代码如下:
DROP TABLE IF EXISTS login_info;
CREATE TABLE login_info(
user_id VARCHAR(8),
login_time DATE
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO
login_info (user_id,login_time)
VALUE ('a001','2021-01-01')
,('b001','2021-01-01')
,('a001','2021-01-03')
,('a001','2021-01-06')
,('a001','2021-01-07')
,('b001','2021-01-07')
,('a001','2021-01-08')
,('a001','2021-01-09')
,('b001','2021-01-09')
,('b001','2021-01-10')
,('b001','2021-01-15')
,('a001','2021-01-16')
,('a001','2021-01-18')
,('a001','2021-01-19')
,('b001','2021-01-20')
,('a001','2021-01-23');
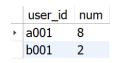
问题:计算每个用户登录日期间隔小于5天的次数。
输出内容包括:
user_id(用户ID)
num(用户登录日期间隔小于5天的次数)
结果样例如下图所示。
可供参考的解题思路: 本题考查LEAD()函数在处理时间间隔问题上的使用方法,观察内层的查询部分,使用LEAD()函数在原有的login_time字段的基础上创造一列新的时间字段(即该用户下一次登录日期),内层查询代码如下:
SELECT user_id
,login_time
,LEAD(login_time,1) OVER (PARTITION BY user_id ORDER BY login_time) AS next_login_time
FROM login_info;
查询结果如下图所示。
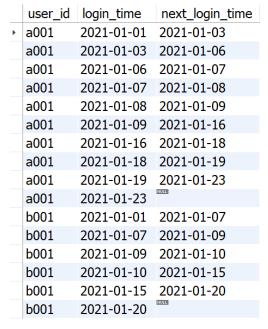
在上图中可以发现,经过LEAD()函数处理后,数据会根据user_id字段分组后按照login_time字段排序。经过内层的处理后,只需在外层筛选出next_login_time与login_time字段的日期差小于5天的数据,即最终统计的目标数据,这里使用了TIMESTAMPDIFF(DAY, login_time, next_login_time)计算日期差,最后分组聚合统计不同user_id的记录个数,即每个用户登录日期间隔小于5天的次数。
涉及知识点: 窗口函数、子查询、分组聚合、时间函数。
本题的SQL代码如下,供读者参考:
SELECT a.user_id
,COUNT(*) AS num
FROM
(
SELECT user_id
,login_time
,LEAD(login_time,1) OVER (PARTITION BY user_id ORDER BY login_time) AS next_login_time
FROM login_info
) AS a
WHERE TIMESTAMPDIFF(DAY, login_time, next_login_time) < 5
GROUP BY user_id;
题目3:用户购买渠道分析
现有一张用户购买信息表purchase_channel,该表记录了用户在某购物平台的购物信息,该购物平台具有网页端(web)和手机端(app)两种访问方式,表中包含如下4个字段。
user_id(用户ID):VARCHAR。
channel(用户购买渠道):VARCHAR。
purchase_date(购买日期):DATE。
purchase_amount(购买金额):INT。
purchase_channel表的数据如下表所示。

数据导入代码如下:
DROP TABLE IF EXISTS purchase_channel;
CREATE TABLE purchase_channel(
user_id VARCHAR(8),
channel VARCHAR(8),
purchase_date DATE,
purchase_amount INT(8)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO
purchase_channel (user_id,channel,purchase_date,purchase_amount)
VALUE ('a001','app','2021-03-14',200)
,('a001','web','2021-03-14',100)
,('a002','app','2021-03-14',400)
,('a001','web','2021-03-15',3000)
,('a002','app','2021-03-15',900)
,('a003','app','2021-03-15',1000);
问题:查询每天仅使用手机端的用户、仅使用网页端的用户和同时使用网页端和手机端(both)的不同用户人数和总购物金额,并且即使某天某渠道没有用户的购买信息,也需要展示。
输出内容包括:
purchase_date(日期)
channel(购买渠道)
sum_amount(总购买金额)
total_users(不同用户人数)
结果样例如下图所示。
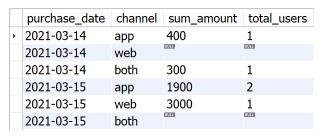
可供参考的解题思路: 根据用户ID和日期进行分组,通过统计用户在各购买渠道购物的记录个数来判断某用户在某日期购物时采用的访问方式(web、app和both)。其中,web和app可以通过一个SELECT语句查询,both则可以通过另一个SELECT语句查询。将两部分使用UNION连接在一起,并将以上部分作为子查询内部,在子查询外部统计不同购买日期、购买渠道的总购买金额和总购买用户。本部分SQL代码如下:
SELECT purchase_date
,channel
,SUM(sum_amount) sum_amount
,SUM(total_users) total_users
FROM
(
SELECT purchase_date
,MIN(channel) channel
,SUM(purchase_amount) sum_amount
,COUNT(DISTINCT user_id) total_users
FROM purchase_channel
GROUP BY purchase_date
,user_id
HAVING COUNT(DISTINCT channel) = 1 UNION
SELECT purchase_date
,'both' channel
,SUM(purchase_amount) sum_amount
,COUNT(DISTINCT user_id) total_users
FROM purchase_channel
GROUP BY purchase_date
,user_id
HAVING COUNT(DISTINCT channel) > 1
) c
GROUP BY purchase_date
,channel;
本部分输出结果如下图所示。
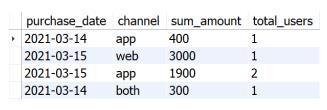
上述部分似乎已经完成了本题要求,但仔细观察就会发现,题目要求即使某天某渠道没有用户的购买信息,也需要展示。而想要展示更全的信息,则考虑使用最全的信息(所有日期和3个渠道的笛卡尔积)与刚查询出的结果数据表进行LEFT JOIN连接,即可得到两张表根据日期和渠道进行连接的结果。
涉及知识点: UNION、分组聚合、数据去重。
本题的SQL代码如下,供读者参考:
SELECT t1.purchase_date
,t1.channel
,t2.sum_amount
,t2.total_users
FROM
(
SELECT DISTINCT a.purchase_date
,b.channel
FROM purchase_channel a,
(
SELECT "app" AS channel
UNION
SELECT "web" AS channel
UNION
SELECT "both" AS channel
) b
) t1
LEFT JOIN
(
SELECT
purchase_date,
channel,
SUM(sum_amount) sum_amount,
SUM(total_users) total_users
FROM (
SELECT purchase_date
,MIN(channel) channel
,SUM(purchase_amount) sum_amount
,COUNT(DISTINCT user_id) total_users
FROM purchase_channel
GROUP BY purchase_date,user_id
HAVING COUNT(DISTINCT channel) = 1
UNION
SELECT purchase_date
,'both' channel
,SUM(purchase_amount) sum_amount
,COUNT(DISTINCT user_id) total_users
FROM purchase_channel
GROUP BY purchase_date,user_id
HAVING COUNT(DISTINCT channel) > 1
)c GROUP BY purchase_date, channel
) t2
ON t1.purchase_date = t2.purchase_date AND t1.channel = t2.channel;
这些题目你做出了么?

为更好的交流学习,应读者的要求,我建立了一个交流群,有需要的同学可以扫描下方公众号或者微信搜索:Python学习与数据挖掘,后台回复关键字:面试,即可获取快速加入通道。

以上是关于每日一题:3个几乎面试必考的SQL数据分析题(含数据和代码)的主要内容,如果未能解决你的问题,请参考以下文章
LeetCode每日一题2020.6.26 面试题 02.01. 移除重复节点
《LeetCode之每日一题》:16.面试题 17.04. 消失的数字