MySQL 数据库,主键为何不宜太长长长长长长长长?
Posted xibuhaohao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 数据库,主键为何不宜太长长长长长长长长?相关的知识,希望对你有一定的参考价值。
回答星球水友提问:沈老师,我听网上说,mysql数据表,在数据量比较大的情况下,主键不宜过长,是不是这样呢?这又是为什么呢?
这个问题嘛,不能一概而论:
(1)如果是InnoDB存储引擎,主键不宜过长;
(2)如果是MyISAM存储引擎,影响不大; 先举个简单的栗子说明一下前序知识。 假设有数据表:
t(id PK, name KEY, sex, flag); 其中:(1)id是主键;(2)name建了普通索引; 假设表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B 如果存储引擎是MyISAM,其索引与记录的结构是这样的:
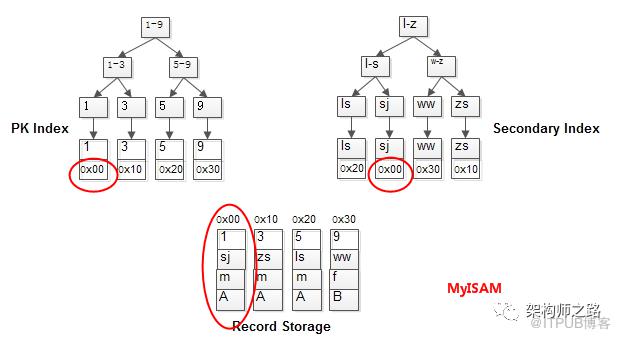
(1)有单独的区域存储记录(record);
(2)主键索引与普通索引结构相同,都存储记录的指针(暂且理解为指针);
画外音:
(1)主键索引与记录不存储在一起,因此它是非聚集索引(Unclustered Index);
(2)MyISAM可以没有PK; MyISAM使用索引进行检索时,会先从索引树定位到记录指针,再通过记录指针定位到具体的记录。
画外音:不管主键索引,还普通索引,过程相同。InnoDB则不同,其索引与记录的结构是这样的:
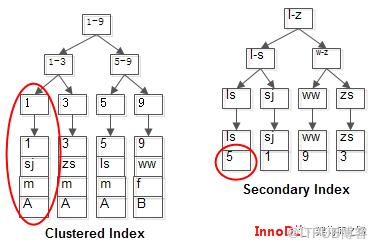
(1)主键索引与记录存储在一起;
(2)普通索引存储主键(这下不是指针了);
画外音:
(1)主键索引与记录存储在一起,所以才叫聚集索引(Clustered Index);
(2)InnoDB一定会有聚集索引; InnoDB通过主键索引查询时,能够直接定位到行记录。

但如果通过普通索引查询时,会先查询出主键,再从主键索引上二次遍历索引树。
回归正题,为什么InnoDB的主键不宜过长呢?
假设有一个用户中心场景,包含身份证号,身份证MD5,姓名,出生年月等业务属性,这些属性上均有查询需求。
最容易想到的设计方式是:
- 身份证作为主键
- 其他属性上建立索引
user(id_code PK,
id_md5(index),
name(index),
birthday(index));

此时的索引树与行记录结构如上:
- id_code聚集索引,关联行记录
- 其他索引,存储id_code属性值
身份证号id_code是一个比较长的字符串,每个索引都存储这个值,在数据量大,内存珍贵的情况下,MySQL有限的缓冲区,存储的索引与数据会减少,磁盘IO的概率会增加。画外音:同时,索引占用的磁盘空间也会增加。 此时,应该新增一个无业务含义的id自增列:
- 以id自增列为聚集索引,关联行记录
- 其他索引,存储id值
user(id PK auto inc,
id_code(index),
id_md5(index),
name(index),
birthday(index));
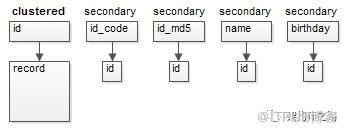
如此一来,有限的缓冲区,能够缓冲更多的索引与行数据,磁盘IO的频率会降低,整体性能会增加。 总结(1)MyISAM的索引与数据分开存储,索引叶子存储指针,主键索引与普通索引无太大区别;(2)InnoDB的聚集索引和数据行统一存储,聚集索引存储数据行本身,普通索引存储主键;(3)InnoDB不建议使用太长字段作为PK(此时可以加入一个自增键PK),MyISAM则无所谓;
希望解答了这位水友的疑问。
以上是关于MySQL 数据库,主键为何不宜太长长长长长长长长?的主要内容,如果未能解决你的问题,请参考以下文章
标题要长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长长