Mysql优化思路
Posted 有虫子啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql优化思路相关的知识,希望对你有一定的参考价值。
一、总体优化思路
首先构建脚本观察查询数,连接数等数据,确定环境原因以及内部SQL执行原因,然后根据具体原因做具体处理。
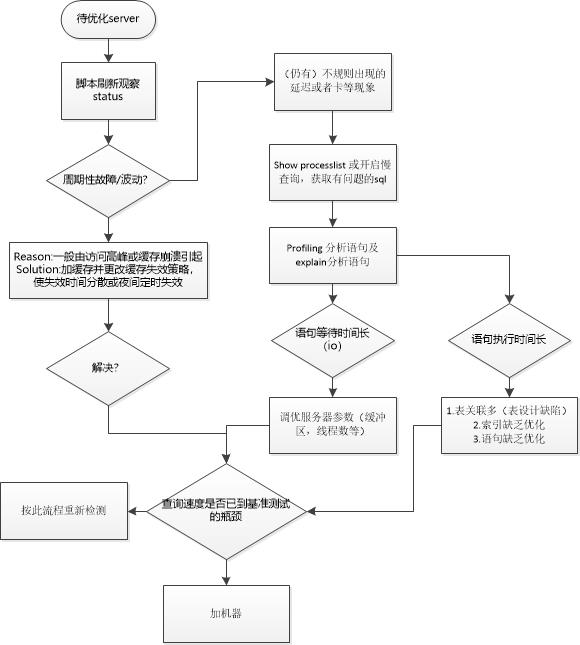
二、构建脚本观察状态
mysqladmin -uroot -p ext \\G
该命令可获取当前查询数量等信息,定时轮询并将结果重定向到文本中,然后处理成图表。
三、处理对策
1.若是规律性出现查询慢,考虑缓存雪崩问题。
对于该问题只需将缓存的失效时间处理成不要相近时间同时失效,失效时间尽量离散化,或者集中到午夜失效。
2.若非规律性查询缓慢,考虑设计缺乏优化
处理方法:
a:开启profiling记录查询操作,并获取语句执行详细信息
show variables like \'%profiling%\'; set profiling=on; select count(*) from user; show profiles; show profile for query 1; >>> +--------------------------------+----------+ | Status | Duration | +--------------------------------+----------+ | starting | 0.000060 | | Executing hook on transaction | 0.000004 | | starting | 0.000049 | | checking permissions | 0.000007 | | Opening tables | 0.000192 | | init | 0.000006 | | System lock | 0.000009 | | optimizing | 0.000005 | | statistics | 0.000014 | | preparing | 0.000017 | | executing | 0.001111 | | end | 0.000006 | | query end | 0.000003 | | waiting for handler commit | 0.000015 | | closing tables | 0.000011 | | freeing items | 0.000085 | | cleaning up | 0.000008 | +--------------------------------+----------+
b:使用explain 查看语句执行情况,索引使用,扫描范围等等
mysql> explain select count(*) from goods \\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: goods partitions: NULL type: index possible_keys: NULL key: gid key_len: 5 ref: NULL rows: 3 filtered: 100.00 Extra: Using index
c:相关优化手法
表的优化与列类型选择
列选择原则:
1:字段类型优先级 整型 > date,time > char,varchar > blob
原因:整型,time运算快,节省空间
char/varchar要考虑字符集的转换与排序时的校对集,速度慢
blob无法使用内存临时表
2:够用就行,不要慷慨(如 smallint,varchar(N))
原因:大的字段浪费内存,影响速度
以varchar(10), varchar(300)存储的内容相同,但在表联查时,varchar(300)要花更多内存
3:尽量避免使用NULL
原因:NULL不利于索引,要用特殊的字节来标注.
在磁盘上占据的空间其实更大
索引优化策略
1.索引类型
1.1 B-tree索引(排好序的快速查找结构)
注:Myisam,innodb中,默认用的是B-tree索引
1.2 hash索引
在memory表里,默认是hash索引,hash的理论查询时间复查度为O(1)
疑问:既然hash索引如此高效,为何不都用他?
a.hash函数计算后的结果是随机的,如果是在磁盘上放置数据,以主键为id为例,那么随着id的增长,id对应的行,在磁盘上随机放置。
b.无法对范围查询进行优化
c.无法利用前缀索引,比如在b-tree中,field列的值为“helloworld”,索引查询xx=hello/xx=helloworld都可以利用索引(左前缀索引),但hash索引无法做到,因为hash(hello)与hash(helloworld)并无关联关系。
d.排序也无法优化
e.必须回行,通过索引拿到数据位置,必须回到表中取数据.
2.b-tree索引的常见误区
2.1 在where条件常用的列上都加上索引
例:where cat_id=3 and price>100; //查询第3个栏目,100元以上的商品
误:cat_id和price上都加上索引。其实只能用上一个索引,他们都是独立索引.
2.2 在多列上建立索引后,查询哪个列,索引都将发挥作用
2.2 在多列上建立索引后,查询哪个列,索引都将发挥作用
正解:多列索引上,索引发挥作用,需要满足左前缀要求(层层索引)
以index(a,b,c)为例:
语句 索引是否发挥作用
where a=3 是
where a=3 and b=5 是
where a=3 and b=5 and c=4 是
where b=3 or where c=4 否
where a=3 and c=4 a列能发挥索引作用,c列不能
where a=3 and b>10 and c=7 a,b能发挥索引作用,c列不能
高性能索引策略
1.对于innodb而言,因为节点下有数据文件,因此节点的分裂将会变得比较慢,对于innodb的主键,尽量用整型,而且是递增的整型。
2.索引的长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多)。
3.针对列中的值,从左往右截取部分来建索引。
a.截的越短,重复度越高,区分越小,索引效果越不好
b.截的越长,虽然区分度提高,但索引文件变大影响速度
所以尽量在长度上找到一个平衡点使性能最大化,惯用手法:截取不同长度来测试索引区分度
区分度测试: select count(distinct left(word, 1)) / count(*) from table;
测试完成后可以按测试得出的最优长度建立索引 alter table table_name add index word(word(4));
理想的索引
1.查询频繁
2.区分度高
3.长度小
4.尽量覆盖常用查询字段
以上是关于Mysql优化思路的主要内容,如果未能解决你的问题,请参考以下文章
优化 C# 代码片段、ObservableCollection 和 AddRange