mysql高可用之MHA
MHA简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在10~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
使用MySQL 5.6以上的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,不支持多实例
另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
官方介绍:https://code.google.com/p/mysql-master-ha/
MHA详细工作流程
- Manager程序负责监控所有已知Node节点(主和从所有节点)
- 当主库发生意外宕机
- mysql实例故障(SSH能够连接到主机)
- 监控到主库宕机,选择一个新主,选择标准:数据较新的从库会被选择为新主
- 从库通过MHA自带脚本程序,立即保存缺失部分的binlog
- 其它从库会重新与新主构建主从关系,继续提供服务
- 如果存在VIP机制,将VIP从原主库漂移到新主,让应用程序无感知
- 主节点服务器宕机(SSH已经连接不上了)
- 监控到主库宕机,尝试SSH连接,尝试失败
- 选择一个数据较新的从库成为新主库,判断细节:show slave status\\G
- 计算从库之间的relay-log的差异,补尝到其它从库
- 其它从库会重新与新主构建主从关系,继续提供服务
- 如果VIP机制,将VIP从原主库漂移到新主,让应用程序无感知
- 如果有binlog server机制会继续将binlog server中缺失部分的事务,补偿到新的主库
- mysql实例故障(SSH能够连接到主机)
- 当主库发生意外宕机
MHA工作流程
- 从宕机崩溃的master保存二进制日志时间(binlog events);
- 识别本含有最新更新的slave;
- 应用差异的中继日志(relay log)到其它的slave;
- 应用从master保存的二进制日志时间(binlog events)
- 提升一个slave为新的master;
- 使其它的slave连接新的master进行复制;
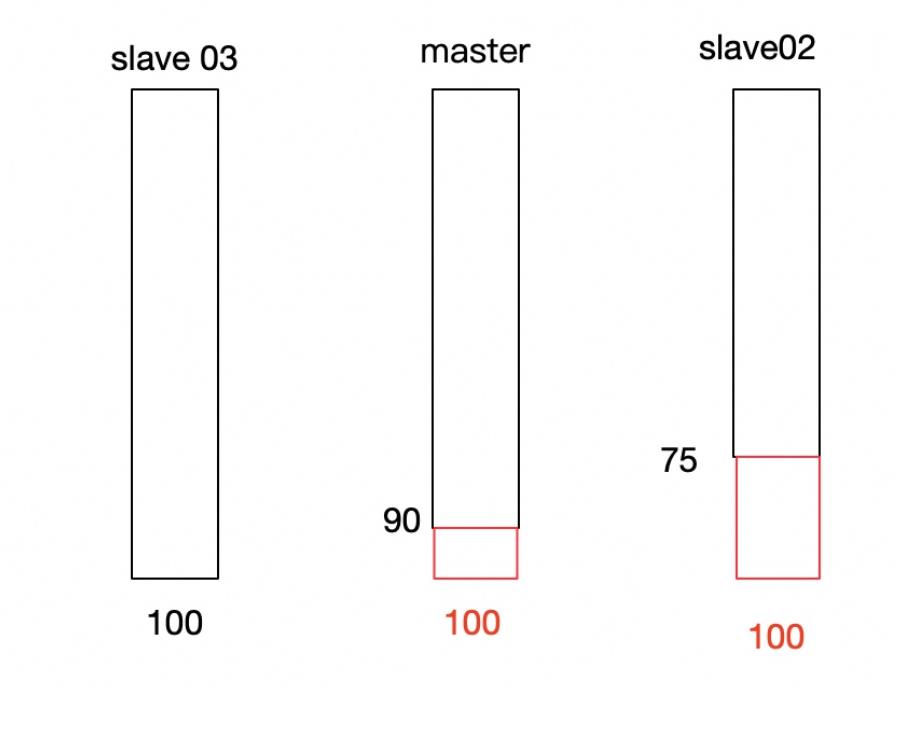
Mysql主从复制-正常状态,如下图:

Mysql主从复制-主宕机后,如下图:

Mysql主从复制-原主恢复后,如下图:
HMA架构
下图展示了如何通过MHA Manager管理多组主从复制。可以将MHA工作原理总结为如下:

MHA工具介绍
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下:
Manager工具包主要包括以下几个工具:
masterha_check_ssh #检査MHA的SSH配置状态
masterha_check_repl #检査主从复制情况
masterha_manger #启动MHA
masterha_check_status #检测MHA的运行状态
masterha_mast er_monitor #检测master是否宕机
masterha_mast er_switch #控制故障转移(自动或手动)
masterha_conf_host #手动添加或删除server信息
masterha_secondary_check #建立TCP连接从远程服务器
masterha_stop #停止MHA
Node工具包主要包括以下几个工具:
save_binary_1ogs #保存宕机的master的binlog
apply_diff_relay_logs #识别relay log的差异并应用于其它从节点
filter_mysqlbinlog #防止回滚事件一MHA已不再使用这个工具
purge_relay_logs #清除中继日志一不会阻塞SQL线程
部署MHA
MySQL环境准备
| 主机名 | 外网IP地址 | 内网地址 | 部署服务 |
|---|---|---|---|
| mha | 10.0.0.50 | 172.16.1.50 | mha manage |
| db01 | 10.0.0.51 | 172.16.1.51 | mysql主+mha node |
| db02 | 10.0.0.52 | 172.16.1.52 | mysql从+mha node |
| db03 | 10.0.0.53 | 172.16.1.53 | mysql从+mha node+binlog-server |
所有机器统一环境,关闭防火墙和Selinux
三台MySQL机器,安装mysql 5.7,安装目录/application/mysql

#系统版本
[root@db01 ~]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
#内核版本
[root@db01 ~]# uname -r
3.10.0-693.el7.x86_64
配置GTID主从复制
mysql主从复制先决条件
- 主库和从库都要开启binlog
- 主库和从库server-id必须不同
- 要有主从复制用户
1.主库操作
#主库修改my.cnf配置文件,添加以下参数
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
server_id=1
log-bin=/application/mysql/data/mysql-bin
binlog_format=row
skip_name_resolve
sync_binlog = 1
gtid-mode=on #开启gtid
enforce-gtid-consistency=on #强制保持gtid一致性
log-slave-updates=1 #slave开启binlog日志
2.从库操作(两个从库操作)
#1.修改db2的my.cnf配置文件:
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
log-bin=/application/mysql/data/mysql-bin
binlog_format=row
skip_name_resolve
sync_binlog = 1
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
#2.修改db3的my.cnf配置文件:
[root@db03 ~]# vim /etc/my.cnf
[mysqld]
server_id=3
log-bin=/application/mysql/data/mysql-bin
binlog_format=row
skip_name_resolve
sync_binlog = 1
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
3.主库创建主从复制授权用户
mysql> grant replication slave on *.* to rep@\'172.16.1.%\' identified by \'123456\';
4.所有从库配置change master to参数
#1.配置参数如下
mysql> change master to
master_host= \'172.16.1.51\',
master_user= \'rep\',
master_password= \'123456\',
master_auto_position= 1;
#启动slave
mysql> start slave;
#查看slave同步状态
mysql> show slave status\\G
配置关闭relaylog自动删除
主节点也需要关闭relaylog,将来主节点宕机后,恢复到生成环境中就是从库的身份
#1.所有库修改my.cnf配置文件,添加以下参数
[mysqld]
relay_log_purge = 0
#2.重启mysql
/etc/init.d/mysqld restart
#3.查看是否关闭relaylog
mysql> show variables like \'%relay%\';
提示:如果不想重启数据库可在mysql命令行全局设置
mysql> set global relay_log_purge = 0;
安装MHA Node
本次MHA的部署基于GTID复制成功构建,普通主从复制也可以构建MHA架构。
下载mha软件,mha官网:https://code.google.com/archive/p/mysql-master-ha/
github下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
需要在所有的主从节点上安装MHA Node
1.下载软件包
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56-0.el6.noarch.rpm
2.安装mha node
#1.安装依赖包
yum install perl-DBD-MySQL -y
#2.上传mha安装包
mkdir /server/tools -p
cd /server/tools/
rz
#3.在所有主从节点安装node
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
3.主库上添加mha管理账号(主库会自动同步到从库)
#1.主库上创建账号,从库会自动复制
mysql> grant all privileges on *.* to mha@\'172.16.1.%\' identified by \'mha123\';
#2.从库验证账号是否同步成功
mysql> select user,host from mysql.user;
4.创建软连接(所有节点)
#如果不创建命令软连接,检测mha复制情况的时候会报错
ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /application/mysql/bin/mysql /usr/bin/mysql
安装MHA Manager
这里以单独的机器上部署mha管理节点
1.安装mha管理软件和相关依赖包
#1.安装epel源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
#2.安装mha manager依赖包
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
#3.安装manager管理软件(前提需安装node软件包)
cd /server/tools
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
#4.验证安装结果:
[root@mha /]# rpm -qa|grep mha
mha4mysql-manager-0.56-0.el6.noarch #安装mha管理包成功
mha4mysql-node-0.56-0.el6.noarch
2.创建Manager必须的目录
mkdir -p /etc/mha #创建必须目录
mkdir -p /var/log/mha/app1 #创建日志,目录可以管理多套主从复制
3.创建mha配置文件
[root@mysql-db03 /]#cat /etc/mha/app1.cnf
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/application/mysql/data
user=mha
password=mha123
ping_interval=2
repl_password=123456
repl_user=rep
ssh_user=root
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
【MHA 配置文件详解】
[server default]
#设置manager的工作目录
manager_workdir=/var/log/mha/app1
#设置manager的日志
manager_log=/var/log/masterha/app1/manager.log
#设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
master_binlog_dir=/application/mysql/data
#设置自动failover时候的切换脚本
master_ip_failover_script= /usr/local/bin/master_ip_failover
#设置手动切换时候的切换脚本
master_ip_online_change_script= /usr/local/bin/master_ip_online_change
#设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
password=mha123
#设置监控用户mha
user=mha
#设置监控主库,发送ping包的时间间隔,尝试四次没有回应的时候自动进行failover
ping_interval=1
#设置远端mysql在发生切换时binlog的保存位置
remote_workdir=/tmp
#设置主从复制用户的密码
repl_password=123456
#设置主从复制环境中用户名
repl_user=rep
#设置发生切换后发送的报警的脚本
report_script=/usr/local/send_report
#一旦MHA到server02的监控之间出现问题,MHA Manager将会尝试从server03登录到server02
secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=10.0.0.51 --master_port=3306
#设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)
shutdown_script=""
#设置ssh的登录用户名
ssh_user=root
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
candidate_master=1
#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,
因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换
在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1
的主机非常有用,因为这个候选主在切换的过程中一定是新的master
check_repl_delay=0
4.配置ssh信任(所有节点)
所有节点需要互相免密码SSH登录到所有节点
#1.添加host解析
# tail -4 /etc/hosts
10.0.0.50 mha
10.0.0.51 mysql-db01
10.0.0.52 mysql-db02
10.0.0.53 mysql-db03
#2.生成密钥
ssh-keygen -t dsa -P \'\' -f ~/.ssh/id_dsa >/dev/null 2>&1
#3.分发公钥,包括自己
ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.50
ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.51
ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.52
ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.53
#也可直接使用for循环来分发公钥
for i in 0 1 2 3 ; do sshpass -p123456 ssh-copy-id -i /root/.ssh/id_dsa.pub "-o StrictHostKeyChecking=no " root@172.16.1.5$i ;done
#4.测试密钥是否分发成功,一键ssh登录for循环
for i in 0 1 2 3 ;do ssh 172.16.1.5$i date ;done
5.在MHA管理器上使用mha自带的工具来测试ssh和主从复制
#1.测试ssh
[root@mha ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
Wed Jan 16 19:31:10 2019 - [info] All SSH connection tests passed successfully. #显示的最后一行看到这行字样,则测试成功
#2.测试主从复制
[root@mha ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
MySQL Replication Health is OK. #显示的最后一行看到这行字样,则测试成功
只要以上两个测试通没问题,那么就可以启动MHA
6.启动MHA
经过上面的部署过后,MHA架构已经搭建完成
#1.启动mha
[root@mha ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
#启动成功后,检查主库状态
[root@mha app1]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:3687) is running(0:PING_OK), master:172.16.1.51
测试故障切换
每当MHA完成一次故障的切换,就会自动停止MHA Manager进程
1.手动停止主库(目前的主库是db01)
[root@db01 ~]# /etc/init.d/mysqld stop
Shutting down MySQL............ SUCCESS!
2.观察主库停库的时候MHA的日志信息变化
[root@mha /]# tail -f /var/log/mha/app1/manager
3.查看db02和db03的slave状态
#1.db02已经成为了主库
mysql> show slave status\\G
Empty set (0.00 sec)
#2.db03指向了新的主库db02
mysql> show slave status\\G #截取部分信息
Master_Host: 172.16.1.52
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
修复主从和MHA
当原主库db01宕机后,由db02接管成为主,这时候当原主恢复正常后,需要通过change master to跟db02主进行主从复制同步
1.将MHA的日志文件的change master to 过滤出来,
修改下password密码,然后使用该参数到原主库里恢复主从,
[root@mha /]# grep -i "change master to " /var/log/mha/app1/manager
Wed Jan 16 19:45:41 2019 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=\'172.16.1.52\', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=\'rep\', MASTER_PASSWORD=\'xxx\';
2.启动原主库,添加change master to 信息
#1.启动mysql
[root@db01 ~]# /etc/init.d/mysqld start
Starting MySQL. SUCCESS!
#2.添加change master to
mysql> CHANGE MASTER TO MASTER_HOST=\'172.16.1.52\', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=\'rep\', MASTER_PASSWORD=\'123456\';
#3.启动主从复制
mysql> start slave;
#4.查看主从复制状态
mysql> show slave status\\G #截取部分信息
Master_Host: 172.16.1.52
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
3.恢复MHA的配置文件
当MHA进行主库故障切换后,会在配置文件将主库的信息给剔除,所以需要将原主库也就是现在的从库的配置信息添加回MHA的配置文件中,才能进行下一次的MHA高可用实现
#省略部分内容
[root@mha /]# vim /etc/mha/app1.cnf
...
[server1] #原主库信息
hostname=172.16.1.51
port=3306
...
4.启动MHA
#1.检查复制状态
[root@mha /]# masterha_check_repl --conf=/etc/mha/app1.cnf
MySQL Replication Health is OK.
#2.启动mha程序
[root@mha /]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
#3.查看当前主节点的信息
[root@mha /]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:4353) is running(0:PING_OK), master:172.16.1.52
提示:目前的数据库状态 db01和db03为从库,db02为主库
配置VIP漂移
通过MHA自带的脚本实现IP FailOver(vip、漂移、应用透明)
IP漂移的两种方式:
- 通过keepalived的方式,管理虚拟IP的漂移(不推荐使用)
- 通过MHA自带脚本方式,管理虚拟IP的漂移(强烈推荐)
1.MHA脚本方式
#1.修改mha配置文件,需要使用到mha自带的脚本,所以要在mha配置文件里添加脚本路径,
[root@mysql-db03 ~]# vim /etc/mha/app1.cnf
[server default]
master_ip_failover_script=/usr/local/bin/master_ip_failover
#2.添加完配置后,先关闭mha,
[root@mysql-db03 ~]# masterha_stop --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
2.主配置中添加VIP脚本
【脚本内容】
[root@mha /]# vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => \'all\';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = \'172.16.1.55/24\';
my $key = \'1\';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
\'command=s\' => \\$command,
\'ssh_user=s\' => \\$ssh_user,
\'orig_master_host=s\' => \\$orig_master_host,
\'orig_master_ip=s\' => \\$orig_master_ip,
\'orig_master_port=i\' => \\$orig_master_port,
\'new_master_host=s\' => \\$new_master_host,
\'new_master_ip=s\' => \\$new_master_ip,
\'new_master_port=i\' => \\$new_master_port,
);
exit &main();
sub main {
print "\\n\\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\\n\\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \\n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \\n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\\@$new_master_host \\" $ssh_start_vip \\"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\\@$orig_master_host \\" $ssh_stop_vip \\"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\\n";
}
#脚本部分修改内容如下:
my $vip = \'172.16.1.55/24\'; #VIP地址(该地址要选择在现网中未被使用的)
my $key = \'1\';
my $ssh_start_vip = "/sbin/ifconfig eth1:$key $vip"; #启动VIP时的网卡名
my $ssh_stop_vip = "/sbin/ifconfig eth1:$key down"; #关闭VIP时的网卡名
该脚本为软件自带,脚本获取方法:再mha源码包中的samples目录下有该脚本的模板,对该模板进行修改即可使用。路径如:mha4mysql-manager-0.56/samples/scripts
2.脚本添加执行权限否则mha无法启动
[root@mha /]# chmod +x /usr/local/bin/master_ip_failover
3.再次启动MHA
[root@mha /]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
4.在主库(db02)上手动绑定VIP
手工在主库上绑定VIP,注意一定要和配置文件中的eth XX 一致,这里是eth0:0(0是key的变量值)
#1.在主库上绑定VIP
[root@db02 ~]# ifconfig eth1:1 172.16.1.55/24
#2.验证VIP是否配置成功
[root@db02 ~]# ip add |grep "172.16.1.55"
inet 172.16.1.55/24 brd 172.16.1.255 scope global secondary eth1:1
5.测试VIP漂移
#1.将主库db02的mysql停止
[root@db02 ~]# /etc/init.d/mysqld stop
Shutting down MySQL...... SUCCESS!
#2.VIP漂移到db01,并且成为主
[root@db01 ~]# ip add |grep "172.16.1.55"
inet 172.16.1.55/24 brd 172.16.1.255 scope global secondary eth1:1
#3.在从库db03上查看slave状态,master指向新的主库db01
mysql> show slave status\\G
Master_Host: 172.16.1.51
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
6.主从环境恢复
- 将原主库db2,通过change master to指向新的master
- 并且将MHA配置文件中剔除的db2的配置添加回去,
- 在启动MHA
配置binlog-server
主库宕机,也许会造成主库binlog复制不及时而导致数据丢失的情况出现,因此配置binlog-server进行实时同步备份,是必要的一种安全手段。
这里就用db03来演示保存来自主库binlog的服务器,必须要有mysql5.6以上的版本,
1.MHA配置binlog-server
#在mha上的app1.cnf配置文件最后添加如下参数
[root@mha /]# cat /etc/mha/app1.cnf
[binlog1]
no_master=1
hostname=172.16.1.53
master_binlog_dir=/data/mysql/binlog/
参数解释:
[binlog1] #添加binlog模块
no_master= (0|1) #1表示永远不提升为master,该节点不参与主从的选举
hostname=172.16.1.53 #指定binlog-server为172.16.1.53
master_binlog_dir=/data/mysql/binlog/ #binglog-server保存binlog保存目录(不能和主库保存位置重复)
2.db03备份blog
#1.创建binlog接收目录,注意权限,
[root@db03 ~]# mkdir -p /data/mysql/binlog/
[root@db03 ~]# chown -R mysql.mysql /data/mysql
#2.进入备份目录启动程序
[root@db03 /]# cd /data/mysql/binlog/
[root@db03 binlog]# mysqlbinlog -R --host=172.16.1.51 --user=mha --password=mha123 --raw --stop-never mysql-bin.000001 &
参数解释:
-R --host=172.16.1.51 #指定主库的地址,向主库拉取binlog
--user=mha #指定之前在主库所创建的MHA的管理用户
--password=mha123 #指定之前在主库所创建MHA管理用户对应的密码
--stop-never #要查看主库的binglog文件最开始的位置
3.重新启动MHA生效配置(必须等binlog拉取完才能启动mha)
#1.停止mha
[root@mha /]# masterha_stop --conf=/etc/mha/app1.cnf
#2.启动mha
[root@mha /]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
4.测试binlog备份
#1.db03上查看binlog目录中的binlog统计数
[root@db03 /]# cd /data/mysql/binlog/
[root@db03 binlog]# ls |wc -l
4
#2.登录主库db01, 刷新binlog日志
mysql> flush logs;
#3.backup上再次查看binlog统计数
[root@db03 binlog]# ls |wc -l
5
每次MHA只要做了故障的切换那么binlog-server就需要删除本地的binlog文件,并重新指定新的master获取binlog
5.当MHA检测到主库物理性质的宕机了,那么MHA会选举出新的主库,并且去向binlog-server拉取binlog日志,跟新主库进行差异化对比,将缺少的数据进行恢复,然后也将VIP漂移到新主库,那么新主库诞生,其它从库会指向新的主库!!
故障排错
指定mysql binlog同步的时候报错,是因为master有些binglog日志是在没有开启GTID之前就已经存在的(环境不干净),就会导致该问题的出现
解决方案将主库的binlog日志清空,并且将从库的master.info和relay-log.info清空,最后重新构建主从关系即可
[root@db03 binlog]# mysqlbinlog -R --host=172.16.1.51 --user=mha --password=mha123 --raw --stop-never mysql-bin.000001 &
[1] 6650
[root@db03 binlog]# mysqlbinlog: [Warning] Using a password on the command line interface can be insecure.
ERROR: Got error reading packet from server: Cannot replicate anonymous transaction when @@GLOBAL.GTID_MODE = ON, at file /application/mysql/data/mysql-bin.000002, position 154.; the first event \'mysql-bin.000001\' at 4, the last event read from \'/application/mysql/data/mysql-bin.000002\' at 219, the last byte read from \'/application/mysql/data/mysql-bin.000002\' at 219.
[1]+ Exit 1 mysqlbinlog -R --host=172.16.1.51 --user=mha --password=mha123 --raw --stop-never mysql-bin.000001