走近源码:Redis如何清除过期key
Posted Jackeyzhe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走近源码:Redis如何清除过期key相关的知识,希望对你有一定的参考价值。
“叮……”,美好的周六就这么被一阵钉钉消息吵醒了。
业务组的同学告诉我说很多用户的帐号今天被强制下线。我们的帐号系统正常的逻辑是用户登录一次后,token的有效期可以维持一天的时间。现在的问题是用户大概每10分钟左右就需要重新登录一次。这种情况一般有两种原因:1、token生成时出问题。2、验证token时出现问题。
通过检查日志,我发现是验证token时,Redis中已经没有对应的token了。并且确定了生成新的token时,set到Redis中的有效期是正确的,那么就基本可以确定是Redis的问题了。
于是又去检查了Redis的监控,发现在那段时间Redis由于内存占用过高强制清理了几次key。但从日志上来看,这段时间并没有出现流量暴涨的情况,而且Redis中key的数量也没有显著增加。那是什么原因导致Redis内存占用过高呢?确定了Redis内存升高不是我们造成的之后,我们又联系了业务组的同学协助他们,他们表示最近确实有上线,并且新上线的功能有使用到Redis。但我仍然感觉很奇怪,为什么Redis中的key没有增多,并且没看到有其他业务的key。经过一番询问,才了解到,业务组同学使用的是这个Redis的db1,而我用的(和刚查的)是db0。这里确实是我在排查问题时出现了疏忽。
那么Redis的不同db之间会互相影响吗?通常情况下,我们使用不同的db进行数据隔离,这没问题。但Redis进行清理时,并不是只清理数据量占用最大的那个db,而是会对所有的db进行清理。在这之前我并不是很了解这方面知识,这里也只是根据现象进行的猜测。
好奇心驱使我来验证一下这个想法。于是我决定直接来看Redis的源码。清理key相关的代码在evict.c文件中。
Redis中会保存一个“过期key池”,这个池子中存放了一些可能会被清理的key。其中保存的数据结构如下:
struct evictionPoolEntry {
unsigned long long idle; /* Object idle time (inverse frequency for LFU) */
sds key; /* Key name. */
sds cached; /* Cached SDS object for key name. */
int dbid; /* Key DB number. */
};
其中idle是对象空闲时间,在Reids中,key的过期算法有两种:一种是近似LRU,一种是LFU。默认使用的是近似LRU。
近似LRU
在解释近似LRU之前,先来简单了解一下LRU。当Redis的内存占用超过我们设置的maxmemory时,会把长时间没有使用的key清理掉。按照LRU算法,我们需要对所有key(也可以设置成只淘汰有过期时间的key)按照空闲时间进行排序,然后淘汰掉空闲时间最大的那部分数据,使得Redis的内存占用降到一个合理的值。
LRU算法的缺点是,我们需要维护一个全部(或只有过期时间)key的列表,还要按照最近使用时间排序。这会消耗大量内存,并且每次使用key时更新排序也会占用额外的CPU资源。对于Redis这样对性能要求很高的系统来说是不被允许的。
因此,Redis采用了一种近似LRU的算法。当Redis接收到新的写入命令,而内存又不够时,就会触发近似LRU算法来强制清理一些key。具体清理的步骤是,Redis会对key进行采样,通常是取5个,然后会把过期的key放到我们上面说的“过期池”中,过期池中的key是按照空闲时间来排序的,Redis会优先清理掉空闲时间最长的key,直到内存小于maxmemory。
近似LRU算法的清理效果图如图(图片来自Redis官方文档)

这么说可能不够清楚,我们直接上代码。
源码分析
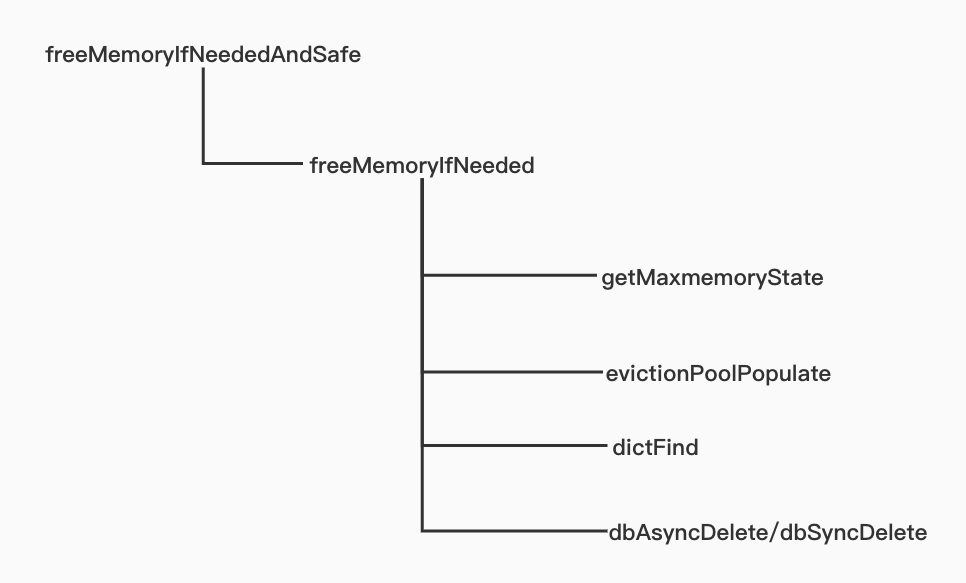
上图展示了代码中近似LRU算法的主要逻辑调用路径。
其中主要逻辑是在freeMemoryIfNeeded函数中
首先调用getMaxmemoryState函数判断当前内存的状态
int getMaxmemoryState(size_t *total, size_t *logical, size_t *tofree, float *level) {
size_t mem_reported, mem_used, mem_tofree;
mem_reported = zmalloc_used_memory();
if (total) *total = mem_reported;
int return_ok_asap = !server.maxmemory || mem_reported <= server.maxmemory;
if (return_ok_asap && !level) return C_OK;
mem_used = mem_reported;
size_t overhead = freeMemoryGetNotCountedMemory();
mem_used = (mem_used > overhead) ? mem_used-overhead : 0;
if (level) {
if (!server.maxmemory) {
*level = 0;
} else {
*level = (float)mem_used / (float)server.maxmemory;
}
}
if (return_ok_asap) return C_OK;
if (mem_used <= server.maxmemory) return C_OK;
mem_tofree = mem_used - server.maxmemory;
if (logical) *logical = mem_used;
if (tofree) *tofree = mem_tofree;
return C_ERR;
}
如果使用内存低于maxmemory的话,就返回C_OK,否则返回C_ERR。另外,这个函数还通过传递指针型的参数来返回一些额外的信息。
- total:已使用的字节总数,无论是
C_OK还是C_ERR都有效。 - logical:已使用的内存减去slave或AOF缓冲区后的大小,只有返回
C_ERR时有效。 - tofree:需要释放的内存大小,只有返回
C_ERR时有效。 - level:已使用内存的比例,通常是0到1之间,当超出内存限制时,就大于1。无论是
C_OK还是C_ERR都有效。
判断完内存状态以后,如果内存没有超过使用限制就会直接返回,否则就继续向下执行。此时我们已经知道需要释放多少内存空间了,下面就开始进行释放内存的操作了。每次释放内存都会记录释放内存的大小,直到释放的内存不小于tofree。
首先根据maxmemory_policy进行判断,对于不同的清除策略有不同的实现方法,我们来看LRU的具体实现。
for (i = 0; i < server.dbnum; i++) {
db = server.db+i;
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?
db->dict : db->expires;
if ((keys = dictSize(dict)) != 0) {
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
}
}
首先是填充“过期池”,这里遍历了每一个db(验证了我最开始的想法),调用evictionPoolPopulate函数进行填充。
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
int j, k, count;
dictEntry *samples[server.maxmemory_samples];
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
for (j = 0; j < count; j++) {
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
de = samples[j];
key = dictGetKey(de);
/* some code */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
idle = estimateObjectIdleTime(o);
}
/* some code */
k = 0;
while (k < EVPOOL_SIZE &&
pool[k].key &&
pool[k].idle < idle) k++;
if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) {
continue;
} else if (k < EVPOOL_SIZE && pool[k].key == NULL) {
} else {
if (pool[EVPOOL_SIZE-1].key == NULL) {
sds cached = pool[EVPOOL_SIZE-1].cached;
memmove(pool+k+1,pool+k,
sizeof(pool[0])*(EVPOOL_SIZE-k-1));
pool[k].cached = cached;
} else {
k--;
sds cached = pool[0].cached; /* Save SDS before overwriting. */
if (pool[0].key != pool[0].cached) sdsfree(pool[0].key);
memmove(pool,pool+1,sizeof(pool[0])*k);
pool[k].cached = cached;
}
}
/* some code */
}
}
由于篇幅原因,我截取了部分代码,通过这段代码我们可以看到,Redis首先是采样了一部分key,这里采样数量maxmemory_samples通常是5,我们也可以自己设置,采样数量越大,结果就越接近LRU算法的结果,带来的影响是性能随之变差。
采样之后我们需要获得每个key的空闲时间,然后将其填充到“过期池”中的指定位置。这里“过期池”是按照空闲时间从小到大排序的,也就是说,idle大大key排在最右边。
填充完“过期池”之后,会从后向前获取到最适合清理的key。
/* Go backward from best to worst element to evict. */
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
de = dictFind(server.db[pool[k].dbid].dict,
pool[k].key);
} else {
de = dictFind(server.db[pool[k].dbid].expires,
pool[k].key);
}
/* some code */
if (de) {
bestkey = dictGetKey(de);
break;
}
}
找到需要删除的key后,就需要根据设置清理策略进行同步/异步清理。
if (server.lazyfree_lazy_eviction)
dbAsyncDelete(db,keyobj);
else
dbSyncDelete(db,keyobj)
最后记下本次清理的空间大小,用来在循环条件判断是否要继续清理。
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
清理策略
最后我们来看一下Redis支持的几种清理策略
- noeviction:不会继续处理写请求(DEL可以继续处理)。
- allkeys-lru:对所有key的近似LRU
- volatile-lru:使用近似LRU算法淘汰设置了过期时间的key
- allkeys-random:从所有key中随机淘汰一些key
- volatile-random:对所有设置了过期时间的key随机淘汰
- volatile-ttl:淘汰有效期最短的一部分key
Redis4.0开始支持了LFU策略,和LRU类似,它分为两种:
- volatile-lfu:使用LFU算法淘汰设置了过期时间的key
- allkeys-lfu:从全部key中进行淘汰,使用LFU
写在最后
现在我知道了Redis在内存达到上限时做了哪些事了。以后出问题时也就不会只检查自己的db了。
关于这次事故的后续处理,我首先是让业务同学回滚了代码,然后让他们使用一个单独的Redis,这样业务再出现类似问题就不会影响到我们的帐号服务了,整体的影响范围也会变得更加可控。
以上是关于走近源码:Redis如何清除过期key的主要内容,如果未能解决你的问题,请参考以下文章