SQL Server数据仓库的基础架构规划
Posted Stay hungery
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server数据仓库的基础架构规划相关的知识,希望对你有一定的参考价值。
问题
SQL Server数据仓库具有自己的特征和行为属性,有别去其他。从这个意义上说,数据仓库基础架构规划需要与标准SQL Server OLTP数据库系统的规划不同。在本文中,我们将介绍在计划数据仓库时应该考虑的一些事项。
解决
SQL Server 数据仓库系统参数
数据仓库本身有自己的参数,因此每个数据仓库系统都有自己独特的特性。在决定数据仓库系统的基础结构时,必须评估许多参数。在这些参数中,主要参数是数据量、报告复杂性、用户、系统可用性和ETL。
数据量
正如你可能知道的,数据量是大数据的七个属性之一。与事务系统不同,数据仓库系统倾向于存储历史数据以及具有多个域和系统的数据。这意味着数据仓库中的数据量将会很大,并且会快速增长。
报表复杂性
在数据仓库的情况下,报表有四种类型:描述性、诊断性、预测性和说明性。数据仓库是分析的框架,这意味着报告用户应该有执行特别查询的选项。此外,还有一些报表将使用具有不同类型连接的大量表和大量聚合。
通常,数据仓库解决方案必须支持以下查询类型的组合:
- 简单: 使用一个事实表和几个维度表进行相对直接的Select 查询。
- 中等: 重复执行包含聚合或多个连接的查询
- 复杂: 具有复杂聚合、连接和计算的特殊查询(ad-hoc)。此外,这类查询还包含数据挖掘和预测分析
用户数量
通常,数据仓库的用户数量少于事务系统。然而,由于大型查询是在相当长的一段时间内出于分析目的而执行的,因此并发性是一个问题。
可用性
Sometimes, depending on the geography distribution of data warehouse users, there is a need to have operating system time slots. Also, planned down time and unplanned outages can affect Availability.
有时,根据数据仓库用户的地理分布,需要有操作系统的时差。此外,计划停机时间和意外停机也会影响可用性。
ETL
ETL (Extract-Transformation-Load):是数据仓库的一个基本组件。对于一些数据仓库,每日ETL就足够了。实际上,大多数数据仓库ETL都属于这一类。有些数据仓库在白天有几个ETL作业,而其他ETL作业将在非高峰时间执行。在一些情况下,一些数据仓库需要实时数据。
从这些参数可以看出,数据仓库系统可以是这些参数的多个复杂性的组合。因此,很难判断数据仓库属于哪一类。
下表包含这些不同规模的系统参数
| Parameter \\ Scale | Small | Medium | Large |
|---|---|---|---|
| 数据量 | Less than 1 TB | 1 to 10 TB | More than 10 TB |
| 报表复杂度 | Simple – 60 % Medium – 30 % Complex – 10 % | Simple – 50 % Medium – 40 % Complex – 10 % | Simple – 20 % Medium – 50 % Complex – 30 % |
| 用户数量 | 100 Users 10 Concurrent users | 1000 Users 100 – 200 concurrent users | 1000 concurrent users |
| 可用性 | Typical business hours | 1-2 hrs of down time | 24x7 |
| ETL | One ETL per day | Intra Day ETL | Real Time Data |
由于很难选择数据仓库的规模,通过查看上面的参数,您可以了解数据仓库的规模。
负载类型
在分析数据仓库的容量之后,下一步是分析数据仓库的工作负载。数据仓库的典型工作负载是ETL、数据模型和报告。
ETL
通常,ETL从事务系统、异构源中提取数据,并对其进行转换,以适应数据仓库这个分析平台。在提取阶段,源系统将有IO和内存负载。由于不应该也不能中断源系统,因此需要对提取进行适当的计划,以使其不会影响源系统。转换通常发生在数据仓库端。因为转换需要更多的计算能力,这意味着CPU的消耗将随着内存的使用而增加。数据的加载还需要数据仓库系统上更多的IO。由于数据来自多个源,在ETL过程中,网络带宽通常是网络管理员关心的问题。
Data 模型
在大多数技术中,会在数据仓库之上创建一个额外的层,以提高报告和分析的性能。例如,对于SQL Server SSAS多维数据集,SSAS 扁平数据集,同时对于Oracle, Hyperion数据集是可用的。在这个层中,数据将从数据仓库读取并处理到数据模型层。在ETL之后,需要处理这些数据模型以保持数据同步。在这个模型层中,将存储聚合的数据,因此数据模型的处理是高CPU和IO操作。此外,聚合是内存密集型操作。
数据仓库结构分层
一图胜千言
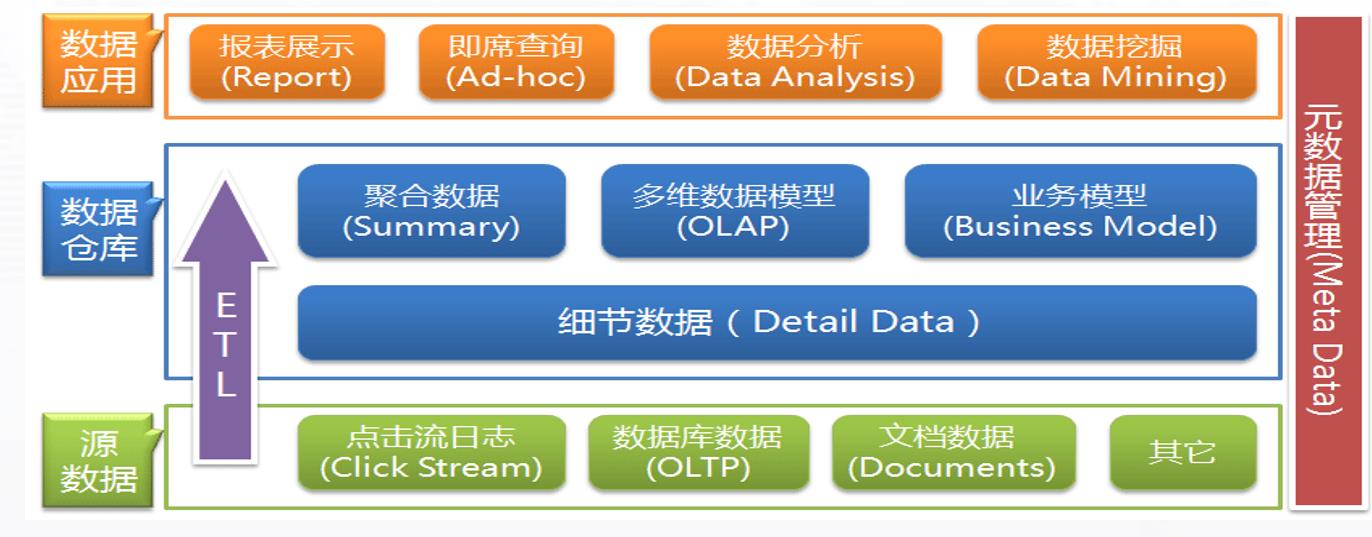
报表和分析
告和分析是最终用户的端点。在报告的情况下,报告更有可能收集大量数据。如果报表正在使用数据模型,那么报表服务器端就会出现问题。在分析的情况下,如果使用数据挖掘算法,会消耗高CPU,因为数据挖掘算法消耗CPU。
此外,还有一些选项,如报表平台中的数据驱动订阅和标准订阅,特别是在SQL Server reporting Services (SSRS)的情况下。由于报告是写到磁盘上的,如Word、Excel或PDF文件,IO的使用率可能相当高。
运维工作负载
除了数据仓库平台上的典型操作之外,还需要完成其他维护任务。
重建索引
索引用于更好的数据检索性能。由于对数据仓库的写操作较少,管理员可以选择创建许多索引。此外,对于数据仓库,可以创建columnstore索引。当存在这些索引时,需要重新构建索引,以避免索引碎片并提高总体性能。如前所述,数据仓库中可能有大量的索引,数据量很大,因此在重建索引时,流程可能会消耗大量的CPU和IO。
数仓的索引与事务性的索引创建有很大不同,更多关注减少非聚集索引的方式。
备份
数据备份不是“必需的”,因为数据通常是从其他源系统生成的。备份也是“必需的”,如果需要,它可以帮助恢复,而不是从头开始重建所有东西。由于数据仓库通常具有大量的数据,因此备份会在系统上使用大量的CPU和IO。一般来讲备份要注意归档和档期当前数据的分区还原等。
以上是关于SQL Server数据仓库的基础架构规划的主要内容,如果未能解决你的问题,请参考以下文章
跟胖子老师一起学习数据仓库建模,奠定架构基础,搞定数据建模!
数据/大数据管理的核心基础:“数据仓库”规划的1234 ——数据仓库的规划构建策略