使用动态跟踪技术SystemTap监控MySQLOracle性能
Posted dataart
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用动态跟踪技术SystemTap监控MySQLOracle性能相关的知识,希望对你有一定的参考价值。
【IT168 技术】本文根据吕海波2018年5月11日在【第九届中国数据库技术大会】上的演讲内容整理而成。
讲师介绍:

吕海波,美创科技研究员,ITPUB管理版版主。出版技术书籍《Oracle内核技术揭密》,曾参加过两届数据库大会。IT老兵,22年IT领域从业经历,十数年数据库经验,惯看IT江湖风起云涌。曾在多家巨头型互联网公司(阿里、ebay、京东)从事数据库管理、数据架构、运维自动化工作。目前主要研究数据安全、敏捷运维等方向。
内容摘要:
时间都去哪儿了?这是性能调优时大家最爱问的问题。比如“我的mysql插入一百万行用了十分钟正常吗?时间都消耗在哪儿了?”。使用SystemTap,可以简单的回答这类问题。SystemTap是Linux下的动态跟踪工具(与Solaris下的DTrace类似),可以方便的监控、跟踪运行中的程序或Linux内核操作,输出用户所关心的性能资料或调试信息,帮助我们理解系统性能消耗在哪些地方,从而有的放矢的调优。SystemTap输出的信息,也可以定向到自动化运维工具中,实现更加细致的性能分析。另外,SystemTap会将你写的SystemTap脚本动态编译为内核模块,然后加载到内核中运行。因此,它额外的性能损耗很小。SystemTap的使用非常简单,本次分享将为大家介绍使用SystemTap脚本,计算MySQL的性能信息,解决“时间都去哪儿了?”之类的问题。另外,对于闭源的Oracle,SystemTap也可以更细粒度的统计它的性能信息,帮助我们理解CPU耗用。
正文演讲:
今天,我想和大家分享的内容是使用动态跟踪技术SystemTap监控MySQL、Oracle性能。动态跟踪技术其实就是动态调试,这是我第三次在中国数据库技术大会上分享调试技术了,前两次我都是以Oracle为主去讲的,但这一次我会以MySQL为主去讲。

这次的中国数据库技术大会有很多关键词,例如源码、开源、自研等等,尤其是正值中兴事件,国内基础技术研究迎来了一个小高潮。
众所周知,基础技术的研究不简单,所以,经常有朋友和我说,他想研究一下MySQL源码,但代码量太大了,放弃了,又或者是他已经编译好了,就差看了,但遗憾的是再也没有然后了。为什么总会出现这种情况呢?我认为是没有建立一个正向的反馈机制。
为什么这样说呢?当你花了很多精力去研究源码,但是很长时间过去了,你发现自己并没有什么收获,这时就会很容易就放弃了。但如果每过一两周,我都会有些小收获,这样不断积累,集小胜为大胜,最终在技术上有所突破。这就是建立了一种正向的反馈机制。
如何建立这种反馈机制呢? 这就要提到我们下面要讲的SystemTap,动态调试或动态跟踪。

什么是动态跟踪?就是在不影响程序的情况下去动态观察正在运行中的程序。动态跟踪技术影响力比较大的是Dtrace,虽然我不确定Dtrace是不是动态跟踪的鼻祖,但可以确定的是SystemTap等众多动态跟踪技术都是之后才出现的。
SystemTap是Redhat推出的,如果服务器是Redhat,那么是不需要安装的,但如果是其它系统则需要安装,不过安装也是很简单的。SystemTap也需要有一定的使用基础,比如基础开发的变量、条件、循环、分支以及写个小程序等等的能力。另外,要熟悉动态跟踪的目标,例如跟踪MySQL,那么MySQL的基础知识、用法是需要掌握的。

动态跟踪有一个很重要的概念叫探针,探针相当于数据库里的触发器,它是操作系统里的触发器。我们可以利用SystemTap将脚本动态插入到内存里,等到一定条件即探针,被触发执行。
动态跟踪技术通常是利用插到内存中的脚本,这类脚本通常不会太复杂,用来显示内存值、内存状态、统计时间等等,因为太复杂会拖慢目标进程或者引起其它的不稳定。

这是一个比较简单的统计MySQL逻辑读时间消耗的例子。假设已知MySQL逻辑读操作是从buf_page_get_gen开始到buf_page_release_latch函数为止。我们写了一个统计逻辑读耗时的SystemTap脚本,很简单,一共15行,如果除去空行和括号,那么脚本真正有效的行数就更少了。
其中,第一行定义了一个脚本的解释器;第三行定义了一个全局变量,因为探针和函数类似,每个函数里的变量不能够互相传递数据,所以如果想跨探针传递数据,必须定义全局变量;第5到7行是SystemTap begin 开始探针,当脚本运行时,这个探针就会被触发。我在这里放了一个输出“begin”的提示;第九行是一个针对MySQL进程的探针,buf_page_get_gen函数入口点的探针,相当于buf_page_get_gen函数的触发器,系统执行这个函数时,探针会被先触发;第十行是记录时间,利用SystemTap的gettimeofday记录以微秒计时的时间;第十三行是buf_page_release_latch函数,当这个函数被触发调用时,用当前时间减去刚才逻辑读开始的时间就是一次完整的逻辑读耗时。

上图两个屏幕窗口,一个是MySQL客户端,一个是shell窗口。先在shell窗口去运行lgr1.stp脚本,其中3164是进程号,-x是cmd命令,运行之后会显示begin。在MySQL客户端里执行一条select语句,并执行一次逻辑读。
执行完毕后,我们看到结果是63微秒。当然,这个时间不是固定的,不同的测试机器时间都会不一样。MySQL完成一次逻辑读大概是60微秒,两者相差不是很大,但如果有多个数据库对比,我们就能了解更多的数据库性能细节。

下面我们来对比一下Oracle时间消耗。Oracle逻辑读有好多种方式,我们用一种比较普通的方式,以rowid的方式逻辑读。这种逻辑读与MySQL有很大的不同,它先获得CBC Latch,在CBC Latch的保护下获得Buffer Pin Lock,然后再读块中的行数据。从获得CBC Latch开始到释放Buffer Pin Lock为止,这是一次完整的逻辑读。
其中,kcbgtcr函数对应MySQL里的buf_page_get_gen函数,也就是获得函数。kcbrls对应MySQL的buf_page_release_latch函数。

有了这两个函数,那么统计Oracle时间消耗的脚本就很好写了。脚本内容和上面的差不多,只是函数名替换一下。

下面我们看一下Oracle统计时间的结果,运行lgr_o.stp脚本,跟踪2630进程,该进程对应的SQL是select * from t1 where rowed=‘AAADs6AAEAAAACRAAB。当begin出现就证明脚本开始运行了,逻辑读执行完之后,我们看到时间是31微秒。
这个结果显然要比MySQL快很多。为什么呢?因为MySQL逻辑读包含了索引对比,要先判断该行是不是用户要读取的行,而Oracle不会进行这样的对比,所以工作量更少,时间消耗自然也会更少。
Oracle其实也有和MySQL类似的逻辑读,但因为这里的测试环境是InnoDB表无法完成。但你也可以在Oracle中建立索引组织表来完成同样的逻辑读。需要注意的是,即使同样的逻辑读,Oracle还是会比MySQL快一点。

如何才能得知对应某个操作的函数名呢?例如,如何得知 buf_page_get_gen函数和buf_page_release_latch函数。这就需要我们去原版中慢慢发掘,花些时间研究源码,或者写个小脚本来统计耗时、性能等等,这也契合了我们前面讲到的正向反馈。
Oracle有1367个等待事件、1000多个性能资料,共计使用了3000多个指标来反映数据库的状态跟性能。相比之下,MySQL这样的开源数据库在这方面就弱了很多,但同时也给SystemTap这样的动态跟踪技术留下了很大的空间。

进入正题,首先介绍一下技术初衷。前段时间,有个客户需要做加载操作,每天执行一次,大概加载百万行数据,耗时十分钟左右。我看了之后发现这个十分钟的耗时还是很正常的,因为他们没使用并行,单线程吞吐量始终是有限的。但是客户觉得慢,想要有更详细的时间列表,这样也就有了我今天的分享内容。
今天,我们主要以介绍方法为主,我主要统计了解析、处理binlog、处理UNDO、处理Redo、总执行时间这五个阶段的时间消耗。下面我们以binlog为例,讲解一下如何使用SystemTap+源码统计电脑执行期间处理binlog的消耗时间,注意这里是统计DML执行时间。
如何开始呢?

第一步我们要找到处理binlog所对应的函数,然后按照之前的方法写个简单脚本统计时间消耗。这里的关键问题就是如何寻找binlog对应函数。有一个重要技能,逆流而上,顺藤摸瓜。逆流而上指的就是跟着内存流往前去。
以binlog为例,binlog数据最终是要写进磁盘的。写磁盘的时候一定是从某一个buffer写到磁盘里,我们就称这个buffer为buffer z,那么这个buffer数据是从哪儿来的?假设buffer z的数据是从buffer y拷贝过去的,那我们就称buffer y是buffer z的上线。那么buffer y的上线是谁?上上线又是谁?……如此顺藤摸瓜,我们就可以找到binlog的处理函数了。

具体方法是什么呢?第一步我们要先找到写binlog到文件的函数,在MySQL里看它调用了什么函数触发了写IO。上图的这个SystemTap脚本与之前不一样的地方是,刚才脚本中函数名称是固定的,而这里使用了*write*,也就是说要跟踪所有名称中包含write字样的函数。
另外,还有一个条件语句,其中Ulong_arg(1)是当探针被触发时函数的第一个参数。这样的函数通常第一个参数都是文件号,第二个参数是buffer,第三个参数是长度。131是binlog文件的文件号,我们可以从proc中得到。
如果满足了函数名称中带有write,第一个参数是binlog文件号,那么它就极有可能是写到文件的函数。我需要具体做什么操作?首先,输出三个参数,然后我们利用SystemTap的内置函数pp,显示探针对应的信息,包括探针的函数名等等。之后,输出一个堆栈,堆栈指的是当前函数的上层,然后以此类推再继续往上找。

看一下执行结果,先运行脚本,其中3164是mysqld的进程号。等到begin输出之后,再去执行一条insert语句,然后我们看到没有任何东西输出。这是因为Insert语句不触发IO,等到commit才会被触发。
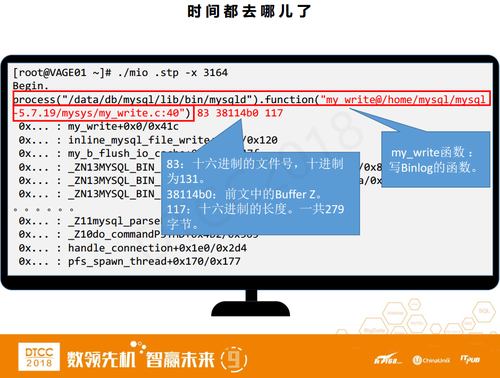
再执行一条commit,我们就能看到输出内容了。方框中是pp函数对应的内容是探针的信息,my_write函数就是MySQL里写binlog到文件所调用的函数,它在my_write.c的第40行。后面的三个参数分别文件号83, 38114B0是前面所说的buffer z,从这个地方binlog数据被写到磁盘里面了,但这还不是精确的buffer z, 17是长度,换算成十进制就是279字节。

下面看一下my_weite.c的内容,在my_write.c的第40行有my_write函数,第63行是它调用库函数write完成实际的IO操作,这里的第一个参数仍然是文件号,第二个是buffer,并且这个参数可能与buffer z的准确地址有关。

我们先准备一条有辨识度的SQL,什么叫有辨识度的SQL?就是SQL中有大量的重复数据,容易辨认。比如,第二列有8个小写a,16进制的ASCII码就是6161616161616161,你在内存里会看到八个连续的61。

之后我们以第二列列值为准来寻找精确的buffer z地址。具体操作时,我们还要再引入另外一个调试工具叫GDB。
其中,3164是正在运行mysqld的进程号,执行之后会输出很多信息,当GDB运行之后,目标程序里的任何操作都需要经过GDB的批准。这时如果在MySQL里执行一条SQL语句,那么这个SQL语句会被HANG住。原因很简单,我们没有在CBD里发命令让它继续跑。
首先,我会在my_write.c的63行设置一个断点,断点跟探针差不多,当某个函数或操作执行时触发断点。设置完后,我会执行C命令,C命令在GDB里相当于continue,之后执行Insert语句继续,刚才被Hang住的语句并没有触发探针,因为Insert语句不会去触发binlog的IO。
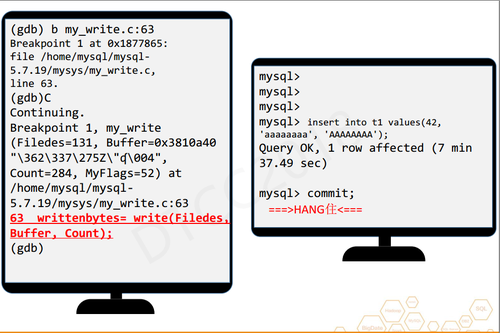
之后执行commit,再次被Hang住了,这时是断点被触发了。
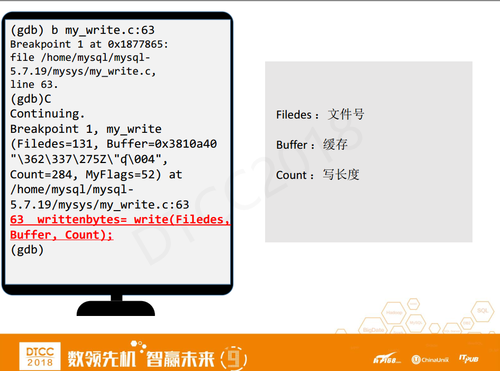
断点处的信息就是刚才第63行write库函数的信息,仍然是第一个参数是文件号,第二个参数是缓存,第三个参数是279长度。

在GDB里面使用p命令验证一下,输出Filedes与binlog文件号对比。

p命令显示buffer z的地址是3810A40,与刚才脚本输出内容是一样的。但3810A4并不是精确的buffer z的地址,精确的buffer z地址应该是Insert语句里的8个a。

如何寻找呢?首先,使用X命令显示381040的内存值。

3810B20内存地址有一个61080000的数据,GDB做了一个自动转换使其转变为00000861,在后面的一个字节是0x08616161,这不就是Insert语句的第二列,那么它的准确地址是什么呢?0x3810B20往后挪两个字节0x3810B22。

之后,用watch设置一个观察点,相当于GDB里的断点,当进程读写到指定内存时被触发。如前文所述,0x3810b22是我们找到的buffer z,设置了监察点之后,只要谁给buffer z传递数据,那么监察点就会被触发。

之后运行C命令,让MySQL跑下去,并在MySQL客户端里再执行一条Insert语句。执行完之后,我们发现探针并没有被触发。

然后再去执行commit,又一次被 Hang住了,探针也被触发了,我们在这里看到了两个值Old Value和New Value。
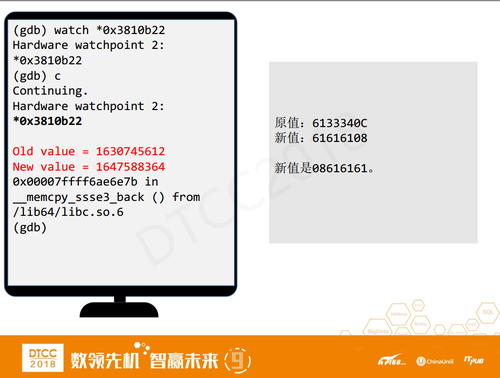
因为探针是来监测buffer z被修改的,所以Old Value就是修改前的原值,而New Value是新值。新值其实就是08616161,那么探针对应的函数是谁?memcpy_ssse3_back(),这个函数其实就是拷贝函数。这时我们已经找到了buffer y,但因为它是在commit时被触发的,所以不是我要找的最终的大boss,还需要继续往下找。
如何找?还是和刚才一样,在buffer y的地址设置观察点。

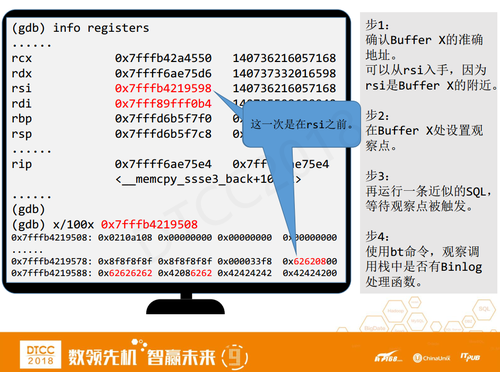
这里我们要使用一个GDB命令叫info registers,显示寄存器。为什么要显示寄存器呢?因为在64位系统中,rdi、rsi、rdx等等都是函数的参数,memcpy函数的第一个参数是目标,第二个参数是源,换句话说就是从第二个参数往第一个参数拷贝,代入到本例中, rdi就是buffer z,rsi就是buffer y。

仔细看,我们发现rdi显然已经不是之前的rdi了,之前是3810B2,现在是 3810B4,为什么会这样呢?这是因为watch观察点是在被观察内存位置被修改之后才触发,它不是停在了memcpy函数的入口点。
rdi、rsi是memcpy函数入口点的第一个参数和第二个参数,但等到从入口点开始,已经执行了好多条代码,内存已被修改。这时,rdi和rsi已被修改,严格来说已经不是memcpy的第一个和第二个参数了。
虽然rdi不是buffer z,但在buffer z附近。同理,rsi也在buffer y附近。Buffer z的准确地址是3810B22,当前rdi是3810B45,两者相差23字节(16进制),那么rsi减去0x23是否就是buffer y的准确地址。
下面我们来验证一下。用X命令来显示内存,其中后四位f0b9就是刚才rsi减去0x23的值,其内存值 0x61616108,也就是刚才Insert语句中的第二列,那么f0b9就是buffer y的准确地址了。

找到buffer y的准确地址之后,删除原来的观察点,在f0b9处再设置一个新的观察点。

之后,继续执行C命令,在MySQL客户端执行一条类似的Insert语句,插入8个b,但这次在执行Insert的时候就被Hang住了,那么很有可能我们这次就找到了DML执行期间binlog的处理函数。
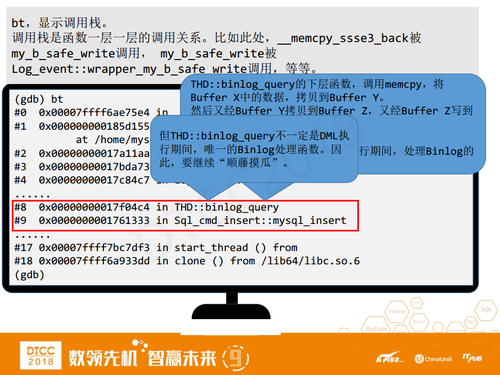
如何验证新的断点被触发之后有没有跟binlog的相关函数?很简单,我们用一条GDB里的BT命令来显示调用栈。
上面的输出结果,#0是当前memcpy函数这一层,#1调用了#0,#2调用了#1的函数,以此类推。其中#8和#9是MySQL Insert函数,调用了THD里的binlog_query函数,我们一看这个函数名就应该知道这就是我们要找的DML执行期间binlog的处理函数了。
整个流程看起来还是蛮简单的,顺藤摸瓜,一路向上找,找到之后,使用BT检测一下是否是我们的目标。
当然,虽然我们找到了目标,但它可能不是唯一的目标,在DML执行期间除了binlog_query,它可能还调用了其他函数去处理binlog。所以我们还需要依此方法继续寻找。
总结一下,第一步确认buffer x,这个需要从rsi、rdi参数入手,然后在buffer x处设定观察点,运行一条近似的SQL,等待观察点被触发,使用BT命令来观察调用栈中是否有binlog字样的处理函数。
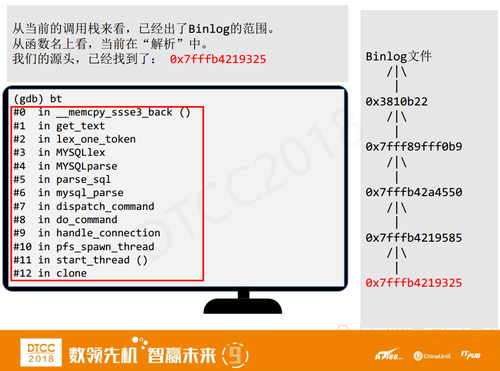
找到什么时候为止呢?从右边看到,我们已经进行了很多层的寻找,如果用BT调用堆栈,我们在里面看到了parse,解析是SQL执行最开始的步骤,证明我们已经找到源头了,不需要接着往下找了。

除了binlog_query,binlog_log_row也是DML期间处理binlog的函数。如果你想要更一步的了解代码,可以在代码中设置断点,单步跟踪,看其是如何完成的。
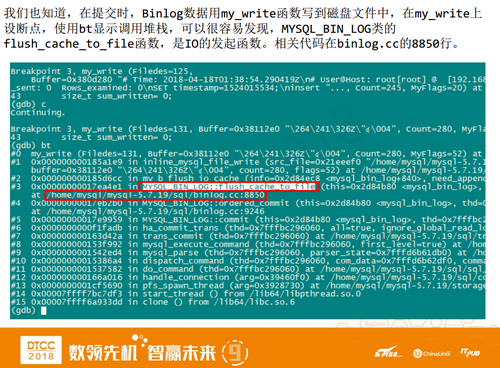
我们也知道提交时binlog数据是用my_write函数写到磁盘中,所以在my_write处设个端点,用BT显示堆栈,就可以知道在binlog写文件时哪个函数触发IO。
应该是flush_cache_to_file函数最早触发IO,并调用my_write完成了IO。为什么flush_cache_to_file是最早触发的函数呢?因为在BT调用栈中可以看到它是在#3,但是在#4、5、6或者之后基本都没有带有IO的函数了。

如果想要更详细的了解,可以在代码中设置断点,跟踪函数是如何执行的。又或者可以做个脚本,统计一下时间、性能消耗等等。这正是前文所说的正向反馈,这样做既有实际用途,同时又能让自己得到成长。

统计binlog时间消耗的脚本很简单,与逻辑读时间消耗的脚本基本一样。先执行脚本,begin出现之后,执行一条Insert的语句,时间输出是80微秒,与之前逻辑读的时间相比长了许多。不过,这也是正常现象,因为DML操作是远比查询更复杂的一种操作,它要处理redo、undo等等。

利用我们刚才找到binlog处理函数的方法,我们还可以找到解析、回滚等其他函数。在研究代码的时候,我建议大家循序渐进,如果代码量很大,可以先尝试从比较小的操作入手,并辅助以动态跟踪技术。

下面讲一下这个脚本的重点部分。第一个就是定义了很多的全局变量,用来跨多个探针记录时间;第二统计解析耗时,这里多了一个东西tid()==$1,其中$1是传递过来的参数——线程号,tid是SystemTap获取当前线程号的函数,考虑到跟踪的mysqld可能是多线程系统,而我们只需跟踪目标线程,所以要把其它线程都过滤掉;第三time探针,括号中的1代表一秒钟触发一次。 每次触发之后输出时间指标,这里是模拟vmstat 1,一秒显示一行。
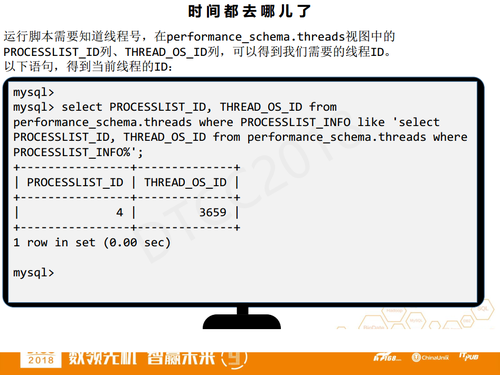
在开始运行之前,我们需要知道线程号,使用tid过滤了目标线程,然后通过performance_schema.threads得到线程号,当前客户端对应的线程号是3659。
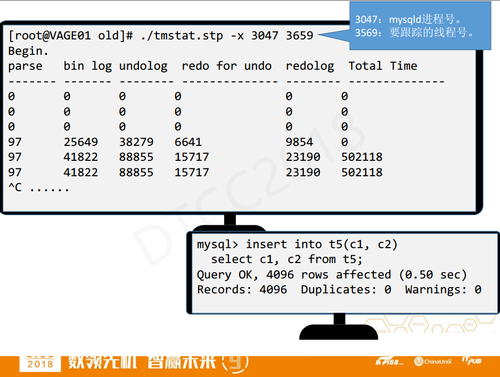
3047是mysqld的线程号,3659是要跟踪的线程号,运行脚本之后,每秒输出一行,执行插入4000多行的Insert语句,就可以能看到时间输出了。
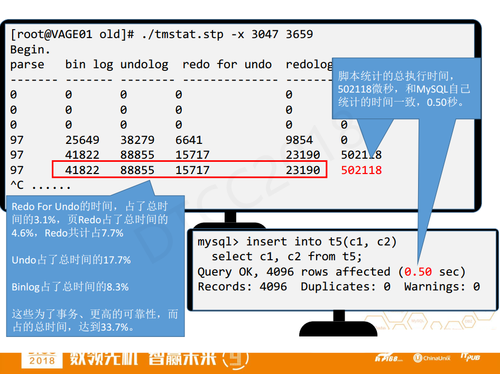
脚本统计得到的耗时是50万微秒,这和MySQL自己统计的时间0.5秒是吻合的,不过我的统计比MySQL客户端详细多了,其中包含了 redo for undo占了总时间的3.1%,页redo占了总时间的4.6%,总redo的时间占了7.7%,而undo占了17.7%,binlog占了8.3%。把这些时间相加,就是InnoDB为了事务、更高的可靠性而额外需要付出的时间,总共占到总时间的33.7%。
今天的分享其实主要就是和大家介绍一下方法,让大家了解原来还可以使用这样的东西帮助我们去监控、统计数据库的性能。
以上是关于使用动态跟踪技术SystemTap监控MySQLOracle性能的主要内容,如果未能解决你的问题,请参考以下文章
systemtap [主设备号,次设备好,inode]监控文件
技术干货听阿里云CDN安防技术专家金九讲SystemTap使用技巧