Linux中使用Systemtap调试SLUB
Posted rtoax
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux中使用Systemtap调试SLUB相关的知识,希望对你有一定的参考价值。
之前的文章曾利用systemtap的"watchpoint"功能来监测变量数值的变化,但systemtap在内核debug中的应用远不止此,本文将借由对SLUB的调试,展现systemtap的其他一些功能。
相比起近两年才出现的bpftrace,自2005年就作为RHEL 4.2中technology preview推出的systemtap算是历史悠久。伴随这么多年的发展,systemtap积累了丰富且成熟的功能,但同时它也是一个相对「重型」的工具。说它重型,是因为它要求安装的软件包,比crash工具还要多:
# rpm -qa | egrep -e kernel-'(devel|debug)' -e systemtap
kernel-debuginfo-common-x86_64-3.10.0-1062.el7.x86_64
kernel-debuginfo-3.10.0-1062.el7.x86_64
kernel-devel-3.10.0-1062.el7.x86_64
systemtap-client-4.0-11.el7.x86_64
systemtap-devel-4.0-11.el7.x86_64
systemtap-runtime-4.0-11.el7.x86_64除了crash工具依赖的debuginfo,systemtap还需要额外的一些组件,而它的使用之所以需要这些包,其实可以从它的workflow看出来:
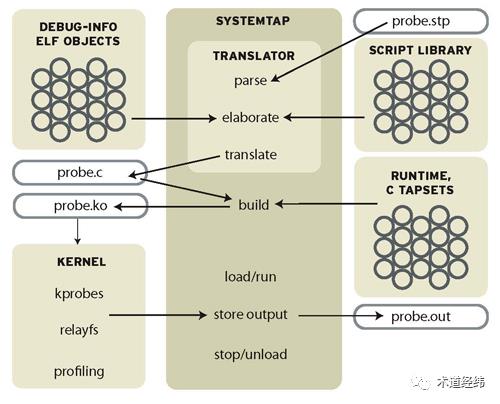
把这堆东西安装完后,可通过以下命令验证功能是否真正可用:
stap -v -e 'probe vfs.read { printf("read performed\\n"); exit() }'所安装的"kernel-devel"不仅需与当前内核版本保持一致,其编译时间也需匹配(对,就是这么矫情),否则会出现错误 "ERROR: module version mismatch",可对照"/proc/version"修改"/usr/src/kernels/$(uname -r)/include/generated/compile.h"文件来解决。
systemtap有着一套自己的语法体系,不过与C语言的风格差别不大,配合其众多的examples(安装后位于"/usr/share/systemtap/"目录),入门并不困难。事实上,systemtap脚本(以下称"stap")在结合debuginfo的信息解析了symbol后,也是转化为C语言,进而编译成一个kernel module来运行的。
又是解析,又是编译,整个过程在第一次的时候耗时还是比较长的,所以笔者一般都会加上代表verbose的"-v"参数来观察这中间的过程。好在它会将编译的结果以cache的形式保存起来,下次再执行同样的stap脚本,就比较迅速了。
其实它能做的事,你自己写一个kernel module,理论上也能做,但写脚本,还是方便多了。如果用传统的printk打印的话,可能还需要重新编译内核,就更麻烦了。
不仅是syscall(在stap中关键字为"syscall",对比strace),也不仅是函数的入口和出口(在stap中关键字为"function",对比ftrace),这家伙能追踪的点,基本是任一address(在stap中关键字为"statement"),甚至以源代码行数的形式喂给它都认得(毕竟有debuginfo不是),比如:
probe kernel.statement("tcp_sendmsg@net/ipv4/tcp.c:1320")有时我们想追一个驱动模块的启动阶段(模块的probe格式为"module(xxx)"),那么在这个模块加载前,就通过systemtap埋伏好点位,也是完全可以达到目的的(现在有没有觉得前面安装那么多东西还是值得的)。
这种强悍的能力,源于它基于的底层机制,即kprobe(不过stap脚本使用的关键字是"probe",反倒是后面文章要介绍的bpftrace用的关键字"kprobe",不要搞混了)。
kprobe的实现机理在不同的arch上有一定的差异,就x86而言,它采用的是将被追踪指令先保存起来,然后将其第一个字节替换成breakpoint指令(比如"int3")。当CPU执行到这条指令,触发trap,相关寄存器被保存,控制权被kprobe劫持,然后,就可以为所欲为了。
干完自己想干的事,kprobe会单步执行之前保存的原始指令,接下来它可以直接归还控制权,或者再执行个"post-handler"(在原始指令执行前的动作则对应为"pre-handler")。
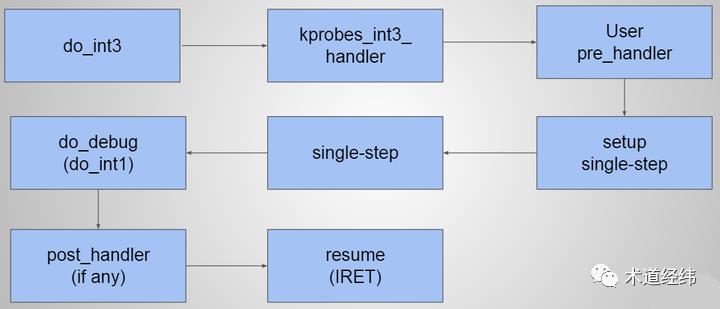
用户态进程可以通过gdb被真正地暂停,使用RTOS或者bare-metal的嵌入式系统也可以通过硬件断点或者软件断点的方式停下来,但Linux内核不行,因此,借助systemtap来在线获取变量信息、打印backtrace、修改返回值等,就成为了尤为重要的调试手段。
说起「修改返回值」,systemtap还有一个妙用。在coredump领域几乎是事实标准的crash工具,也可以用于在线分析,包括动态地修改指定内存的值,但是在crash工具中直接使用"wr"命令往往是不行的,因为"/dev/mem"的使用被限制了。而我们的systemtap,则可以通过修改"devmem_is_allowed"函数的返回值,来帮助crash工具绕过这一限制。
stap -g -e 'probe kernel.function("devmem_is_allowed").return { $return = 1 }'说了那么多,还是回到用systemtap收集SLUB的信息上来(要不然本文真的有跑题的嫌疑……)。
要分析SLUB的内存分配,最好是track调用链比较内层的"slab_alloc_node"函数,以获得更全面的覆盖。可惜这个函数被inline了,无法识别入参,因此本文退而求其次,改为追踪"kmem_cache_alloc"函数。脚本大致如下:
#!/usr/bin/stap
global slab_alloc_stack
probe kernel.function("kmem_cache_alloc"){
slab_alloc_stack[backtrace()]++
}
probe timer.s(5){
foreach (bt in slab_alloc_stack) {
println("")
print_syms(bt)
printf("alloc %d times\\n", slab_alloc_stack[bt])
}
}"slab_alloc_stack"是一个associative array(关联数组,即不仅可以通过整数来索引,还可以使用字符串或其他类型的值来索引的数组)。在这个示例中, "backtrace()"就是索引(key),某一种backtrace出现的次数就是"value"。
考虑到「关联数组」通常体积较大,不适合动态分配,且往往被多个函数共享,因此其在systemtap中只能被定义为「全局变量」的形式(关键字为"global")。
由于stap脚本通常用来追踪一个函数,因此说到变量,需要注意区分是stap脚本自己定义的变量,还是所追踪的函数的变量(target varible)。不知道你注意到没有,stap脚本自己用的变量并没有申明类型,这是因为其类型是在赋值时被自动判定的。
"kernel.function"前面已经介绍过了,它属于同步触发的probe点。而"timer"属于异步触发的probe点,表示每隔多长时间执行一次(这里是5秒),"foreach"用于对关联数组的遍历。
使用"stap -v slub-top.stp"执行该脚本:
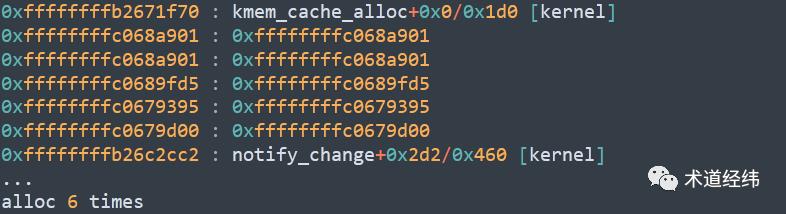
打印的stack里面有的地方只能显示address,不能显示symbol,同时在stap脚本的执行过程中,会出现很多这样的打印:
WARNING: Missing unwind data for a module, rerun with 'stap -d xxx'
缺失的这些symbol属于内核模块,默认没有被加载,如果确切地知道是缺少哪个内核模块的debug信息,可以通过"-d"指定,如果缺失的比较多(比如本文这种情况),那就直接用"--all-modules"吧。
现在symbol的问题算是解决了,但输出的内容里,既没有申请分配SLUB的进程名称,也没有SLUB对象的类型和大小,并没有太多的分析价值。而要想获得这些额外的信息,可以从被probe的函数的参数入手。
# stap -L 'kernel.function("kmem_cache_alloc")' kernel.function("kmem_cache_alloc@mm/slub.c:2719") $s:struct kmem_cache* $gfpflags:gfp_t
dereference入参指针"s",便能拿到对应SLUB的名称和大小。"s"就是前面提到的target varible,使用时需加上"$"符号。在stap的语法里,不管是结构体还是结构体指针,统一使用"->"来获取成员变量("."在stap里是用来连接字符串的)。至于进程名么,可直接用stap提供的"execname()"内置函数。
probe kernel.function("kmem_cache_alloc")
{
printf("alloc "%s" with size "%d", for process %s\\n", $s->name, $s->size, execname())
}执行一下,出现了错误:
semantic error: type mismatch: expected string but found long: $s->name
因为"s->name"是"const char *"类型,会被识别为指针,所以这里应该用"kernel_string($s->name)"转换一下。
现在,该有的信息倒是都齐备了,但是未经统计和归纳,难以直观地判断在一段时间内,到底哪些进程才是消耗SLUB的狂魔,又到底哪些SLUB在被这些狂魔贪婪地占有。下面,将上述的2个示例组合一下,来一点stap的进阶用法:
probe kernel.function("kmem_cache_alloc")
{
slab_alloc_stack[execname(),kernel_string($s->name),backtrace()] <<< $s->size
}
probe timer.s($1){
foreach ([proc,slub,bt] in slab_alloc_stack- limit $2) {
printf("Proc:%s Slub:%s Count:%d Sum:%d\\n", proc, slub,
@count(slab_alloc_stack[proc,slub,bt], @sum(slab_alloc_stack[proc,slub,bt]))
print_syms(bt)
}
exit()
}这个组合后的脚本的主要目的,是根据关联数组的value来进行排序。在foreach循环里,数组名后面跟的"-"代表递减排序,"limit"表示取最为靠前的几个。
同时,为了实现更灵活地控制(以及展现stap的更多用法),笔者分别使用了"$1"和"$2"来设定时长和limit数目,而它们对应的都是脚本执行时传入的整型类参数(如果是字符串类参数则应该用"@1", "@2"):。
stap -v --all-modules slub-top-sort.stp 10 5
这里,作为关联数组的"slab_alloc_stack"有进程名、SLUB名称和backtrace三个key,其效果类似于一个三维数组。系统中有多个进程,每个进程在进入内核态后可能申请的SLUB也有多种,即便是同一个进程申请的同一种SLUB,其调用栈的路径也可能不同。
对于这样一个key的组合,假设对应SLUB的大小为256,且在10秒的执行时间内被命中了4次,使用"<<<"符号,可以将这4次的数据都保存下来,便于之后的统计处理。"@sum"用于聚合数据的累加值(即1024),一个可能有点容易混淆的概念是"@count",它汇总的是次数之和(即4)。
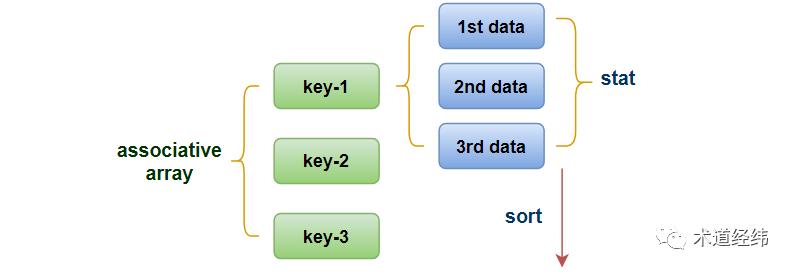
在脚本中进一步结合"if"条件过滤,可以单独看一个进程申请最多的前几种SLUB,如果依然以SLUB的大小作为统计数值,那么每次probe命中时的数值大小都可能不同,这时计算最小值、平均值和最大值的"@min", "@avg"和"@max"就派上了用场。
原作者:兰新宇
以上是关于Linux中使用Systemtap调试SLUB的主要内容,如果未能解决你的问题,请参考以下文章