spark-2.4.0-hadoop2.7-安装部署
Posted 踏歌行的专栏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark-2.4.0-hadoop2.7-安装部署相关的知识,希望对你有一定的参考价值。
1. 主机规划
|
主机名称 |
IP地址 |
操作系统 |
部署软件 |
运行进程 |
备注 |
|
mini01 |
172.16.1.11【内网】 10.0.0.11 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、kafka_2.11-2.0.0、spark-2.4.0-hadoop2.7【主】 |
QuorumPeerMain、 |
|
|
mini02 |
172.16.1.12【内网】 10.0.0.12 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、kafka_2.11-2.0.0 |
QuorumPeerMain、 |
|
|
mini03 |
172.16.1.13【内网】 10.0.0.13 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、kafka_2.11-2.0.0、spark-2.4.0-hadoop2.7 |
QuorumPeerMain、 |
|
|
mini04 |
172.16.1.14【内网】 10.0.0.14 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、spark-2.4.0-hadoop2.7 |
QuorumPeerMain、 |
|
|
mini05 |
172.16.1.15【内网】 10.0.0.15 【外网】 |
CentOS 7.5 |
Jdk-8、zookeeper-3.4.5、Hadoop2.7.6、hbase-2.0.2、spark-2.4.0-hadoop2.7 |
QuorumPeerMain、 |
|
说明
该Spark集群安装,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠。具体部署下节讲解。
2. 免密码登录
实现mini01到mini02、mini03、mini04、mini05通过秘钥免密码登录。
参见文章:Hadoop2.7.6_01_部署
3. Jdk【java8】
参见文章:Hadoop2.7.6_01_部署
4. Spark部署步骤
4.1. Spark安装
1 [yun@mini01 software]$ pwd 2 /app/software 3 [yun@mini01 software]$ ll 4 total 238572 5 -rw-r--r-- 1 yun yun 227893062 Nov 19 21:24 spark-2.4.0-bin-hadoop2.7.tgz 6 [yun@mini01 software]$ tar xf spark-2.4.0-bin-hadoop2.7.tgz 7 [yun@mini01 software]$ mv spark-2.4.0-bin-hadoop2.7 /app/ 8 [yun@mini01 software]$ cd /app/ 9 [yun@mini01 ~]$ ln -s spark-2.4.0-bin-hadoop2.7/ spark 10 [yun@mini01 ~]$ ll -d spark-* 11 drwxr-xr-x 13 yun yun 211 Oct 29 14:36 spark-2.4.0-bin-hadoop2.7 12 lrwxrwxrwx 1 yun yun 26 Nov 24 14:23 spark -> spark-2.4.0-bin-hadoop2.7/
4.2. 环境变量修改
根据规划,该环境变量的修改包括mini01、mini03、mini04、mini05。
1 # 需要root权限去添加环境变量 2 [root@mini01 ~]# tail /etc/profile 3 ……………… 4 # spark环境变量 5 export SPARK_HOME="/app/spark" 6 export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH 7 8 [root@mini01 ~]# logout 9 [yun@mini01 conf]$ source /etc/profile # 重新加载该环境变量
4.3. 配置修改
1 [yun@mini01 conf]$ pwd 2 /app/spark/conf 3 [yun@mini01 conf]$ cp -a spark-env.sh.template spark-env.sh 4 [yun@mini01 conf]$ tail spark-env.sh # 修改环境变量配置 5 # Options for native BLAS, like Intel MKL, OpenBLAS, and so on. 6 # You might get better performance to enable these options if using native BLAS (see SPARK-21305). 7 # - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL 8 # - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS 9 10 # 添加配置如下 11 # 配置JAVA_HOME 12 export JAVA_HOME=/app/jdk 13 # 设置Master的主机名 14 export SPARK_MASTER_IP=mini01 15 # 每一个Worker最多可以使用的内存,我的虚拟机就2g 16 # 真实服务器如果有128G,你可以设置为100G 17 # 所以这里设置为1024m或1g 18 export SPARK_WORKER_MEMORY=1024m 19 # 每一个Worker最多可以使用的cpu core的个数,我虚拟机就一个... 20 # 真实服务器如果有32个,你可以设置为32个 21 export SPARK_WORKER_CORES=1 22 # 提交Application的端口,默认就是这个,万一要改呢,改这里 23 export SPARK_MASTER_PORT=7077 24 25 [yun@mini01 conf]$ pwd 26 /app/spark/conf 27 [yun@mini01 conf]$ cp -a slaves.template slaves 28 [yun@mini01 conf]$ tail slaves # 修改slaves 配置 29 # distributed under the License is distributed on an "AS IS" BASIS, 30 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 31 # See the License for the specific language governing permissions and 32 # limitations under the License. 33 # 34 35 # A Spark Worker will be started on each of the machines listed below. 36 mini03 37 mini04 38 mini05
4.4. 分发到其他机器
分发到mini03、mini04和mini05
1 [yun@mini01 ~]$ scp -pr spark-2.4.0-bin-hadoop2.7/ yun@mini03:/app # 拷贝到mini03 2 [yun@mini01 ~]$ scp -pr spark-2.4.0-bin-hadoop2.7/ yun@mini04:/app # 拷贝到mini04 3 [yun@mini01 ~]$ scp -pr spark-2.4.0-bin-hadoop2.7/ yun@mini05:/app # 拷贝到mini05
在mini03、mini04和mini05上操作
1 [yun@mini04 ~]$ pwd 2 /app 3 [yun@mini04 ~]$ ll -d spark-2.4.0-bin-hadoop2.7 4 drwxr-xr-x 13 yun yun 211 Oct 29 14:36 spark-2.4.0-bin-hadoop2.7 5 [yun@mini04 ~]$ ln -s spark-2.4.0-bin-hadoop2.7/ spark 6 [yun@mini04 ~]$ ll -d spark-* 7 drwxr-xr-x 13 yun yun 211 Oct 29 14:36 spark-2.4.0-bin-hadoop2.7 8 lrwxrwxrwx 1 yun yun 26 Nov 24 23:39 spark -> spark-2.4.0-bin-hadoop2.7/
4.5. 启动spark
在mini01上操作
1 [yun@mini01 sbin]$ pwd 2 /app/spark/sbin 3 [yun@mini01 sbin]$ ./start-all.sh # 关闭使用 stop-all.sh 脚本 4 starting org.apache.spark.deploy.master.Master, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.master.Master-1-mini01.out 5 mini03: starting org.apache.spark.deploy.worker.Worker, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.worker.Worker-1-mini03.out 6 mini05: starting org.apache.spark.deploy.worker.Worker, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.worker.Worker-1-mini05.out 7 mini04: starting org.apache.spark.deploy.worker.Worker, logging to /app/spark/logs/spark-yun-org.apache.spark.deploy.worker.Worker-1-mini04.out 8 [yun@mini01 ~]$ 9 [yun@mini01 ~]$ jps # 查看进程状态 10 3103 Master 11 3183 Jps
mini03进程查看
1 [yun@mini03 ~]$ jps 2 2387 Worker 3 2437 Jps
mini04进程查看
1 [yun@mini04 ~]$ jps 2 2183 Jps 3 2125 Worker
mini05进程查看
1 [yun@mini05 ~]$ jps 2 2212 Worker 3 2261 Jps
4.6. 浏览器访问
1 http://mini01:8080/
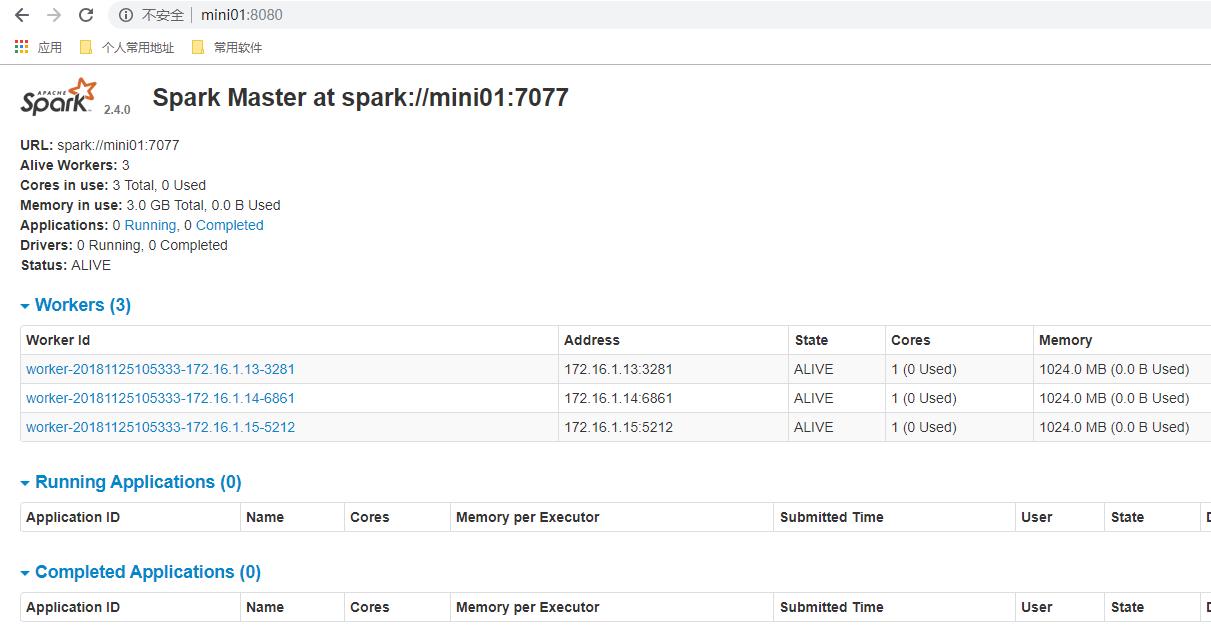
以上是关于spark-2.4.0-hadoop2.7-安装部署的主要内容,如果未能解决你的问题,请参考以下文章
安装没有成功。无法安装应用程序。 java.io.IOException:仅在内部请求,但空间不足