(项目六)Mha-Atlas-MySQL高可用方案实践
Posted 海哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(项目六)Mha-Atlas-MySQL高可用方案实践相关的知识,希望对你有一定的参考价值。
mha-mysql环境准备:
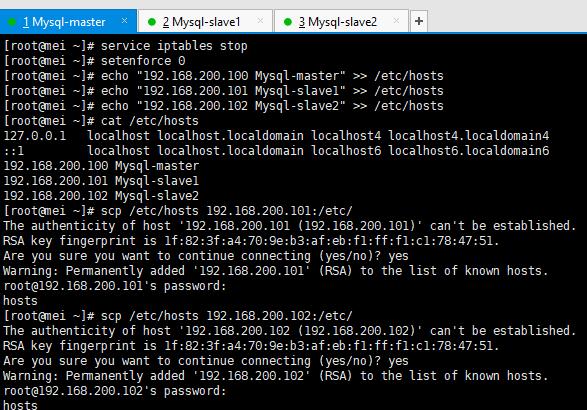
三台虚拟机,都安装了mysql,都关闭防火墙和selinux,同时在每台虚拟机上都做映射
软件包
1) mha管理节点安装包:
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-manager-0.56.tar.gz
2) mha node节点安装包:
mha4mysql-node-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56.tar.gz
3) mysql中间件:
Atlas-2.2.1.el6.x86_64.rpm
4) mysql源码安装包
mysql-5.6.17-linux-glibc2.5-x86_64.tar

注意,mysql的安装包一定要用5.6版本及以上
软件简介
- MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换过程中,MHA能最大程度上保证数据库的一致性,以达到真正意义上的高可用。
- MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应程序是完全透明的。
工作流程
- 从宕机崩溃的master保存二进制日志事件(binlog events);
- 识别含有最新更新的slave;
- 应用差异的中继日志(relay log)到其他的slave;
- 应用从master保存的二进制日志事件(binlog events);
- 提升一个slave为新的master;
- 使其他的slave连接新的master进行复制;
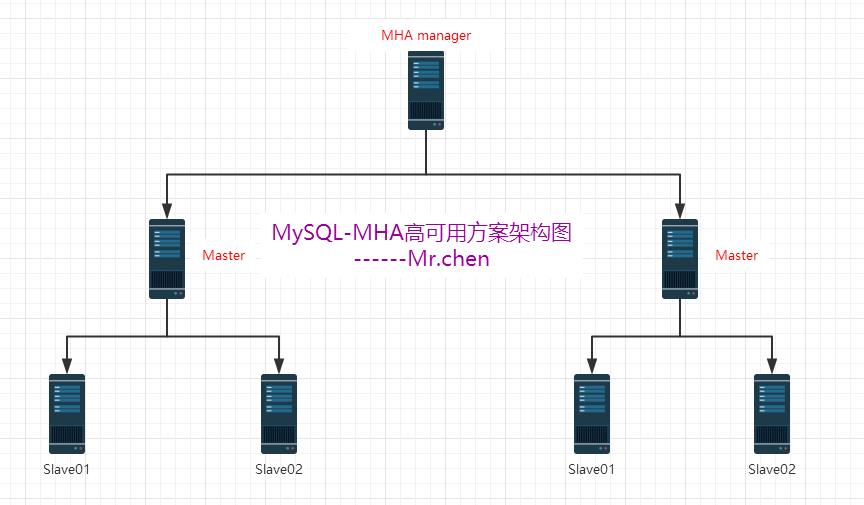
MHA架构图
MHA工具介绍
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下:
#Manager工具包主要包括以下几个工具:masterha_check_ssh #检查MHA的SSH配置状况masterha_check_repl #检查MySQL复制状况masterha_check_status #检测当前MHA运行状态masterha_master_monitor #检测master是否宕机masterha_manger #启动MHAmasterha_master_switch #控制故障转移(自动或者手动)masterha_conf_host #添加或删除配置的server信息masterha_secondary_check #试图建立TCP连接从远程服务器masterha_stop #停止MHA#Node工具包主要包括以下几个工具:save_binary_logs #保存和复制master的二进制日志apply_diff_relay_logs #识别差异的中继日志事件filter_mysqlbinlog #去除不必要的ROLLBACK事件purge_relay_logs #清除中继日志mysql安装过程略(在安装之前先安装
ncurses-devel 和 libaio,本地yum即可安装 )在安装完mysql后设置密码:mysqladmin -uroot password ‘123456’
配置基于GTID的主从复制
先决条件
- 主库和从库都要开启binlog
- 主库和从库server-id不同
- 要有主从复制用户
打开了GTID,就控制不了同步过程,一旦出现问题,得先关闭GTID才能修改
主库操作(Mysql-Master)
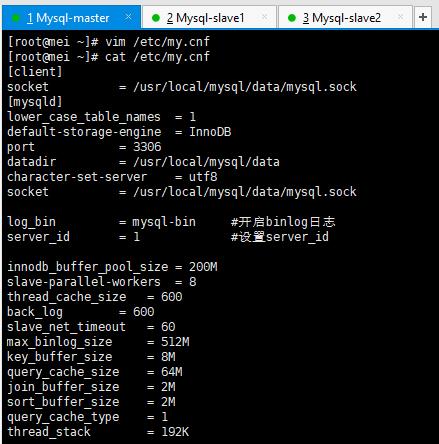
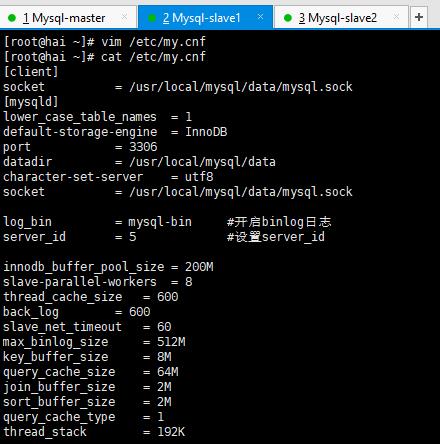
修改配置文件 (主要是开启二进制日志和server id)
修改完配置文件要重启mysqld服务
创建主从复制用户
从库操作(Mysql-slave1和Mysql-slave2)
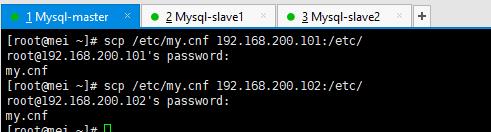
从库配置文件和主库一样,只需要修改server id 即可,我把Mysql-slave1的改为5,Mysql-slave2的改为10,改完记得重启mysqld服务
特别提示:
在以往如果是基于binlog日志的主从复制,则必须要记住主库的master状态信息。
但是在MySQL5.6版本里多了一个Gtid的功能,可以自动记录主从复制位置点的信息,并在日志中输出出来。


开启GTID
修改配置文件,在mysqld模块加三条语句
[mysqld]
gtid_mode = ON
log_slave_updates
enforce_gtid_consistency
三台虚拟机都得加,加完后重启服务。
改完后查看GTID状态
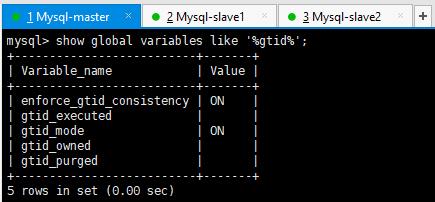
再次提示:
从库都必须要开启GTID,否则在做主从复制的时候就会报错.
主库配置主从复制(Mysql-slave1,Mysql-slave2)
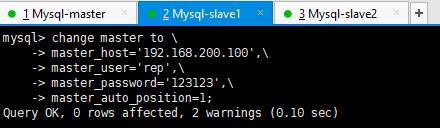
开启从库的主从复制功能(Mysql-slave1,Mysql-slave2)
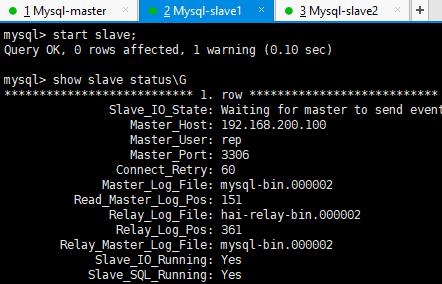
两个从库都执行以上步骤
从库设置(Mysql-slave1,Mysql-slave2)
需要把从库的relay-log日志自动删除功能给关闭,修改配置文件

改完需要重启服务
部署MHA
环境准备(所有节点Mysql-master,Mysql-slave1,Mysql-slave2)


主库上创建该账号从库会自动复制
部署管理节点(mha-manager)
在mysql-slave2上部署管理节点
使用阿里云源+epel源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
wget -O /etc/yum.repos.d/epel-6.repo http://mirrors.aliyun.com/repo/epel-6.repo
然后yum -y install perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
编辑配置文件
创建配置文件目录 mkdir -p /etc/mha
创建日志目录 mkdir -p /var/log/mha/mha1
创建配置文件(默认没有)

以上配置文件内容里每行的最后不要留有空格
特别说明:
参数:candidate_master=1
解释:设置为候选master,如果设置该参数以后,发生主从切换以后会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
参数:check_repl_delay=0
解释:默认情况下如果一个slave落后master 100M的relay logs 的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
配置ssh信任(所有节点Mysql-master,Mysql-slave1,Mysql-slave2)
每个虚拟机都创建密钥对 ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
每个虚拟机的公钥都分发给所有虚拟机(包括自己)

启动测试
ssh检查检测
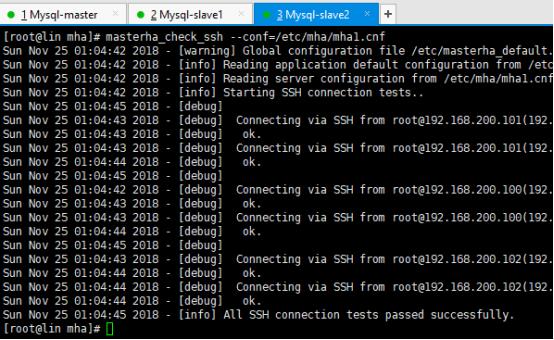
出现上图最后一行,表示成功
主从复制检测
(1)错误的主从复制检测
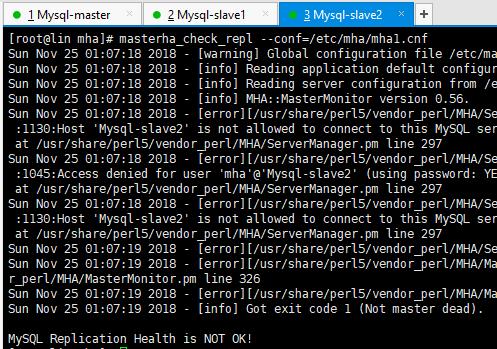
最后一行显示出错,大家应该都是这样的,这是说明Mysql-slave1和Mysql-slave2上没有主从复制账号
因此在Mysql-slave1和Mysql-slave2上添加主从复制的用户即可。
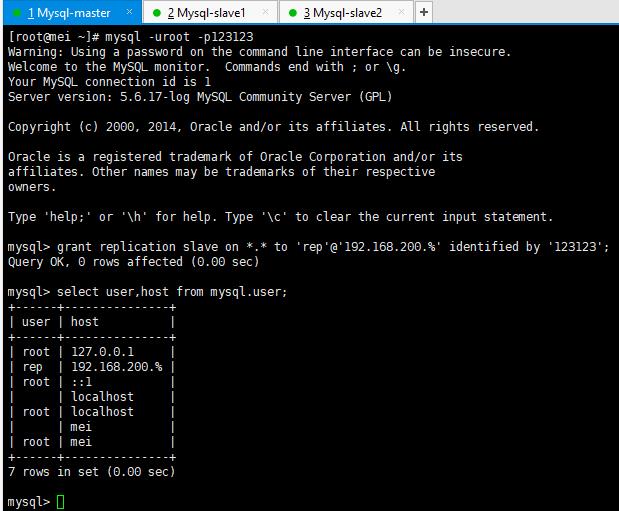
grant replication slave on *.* to rep@\'192.168.200.%\' identified by \'123123\';
注意,创建完主从复制账号要刷新一下,否则还是会报错
flush privileges;
再次检查
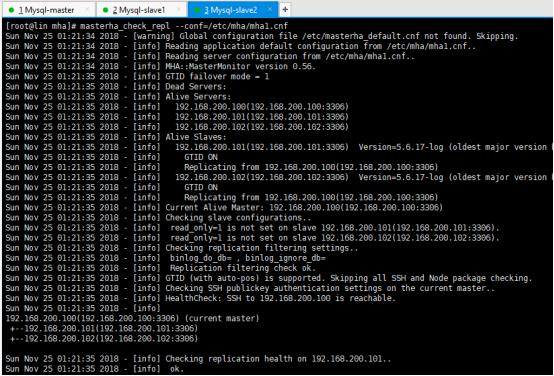
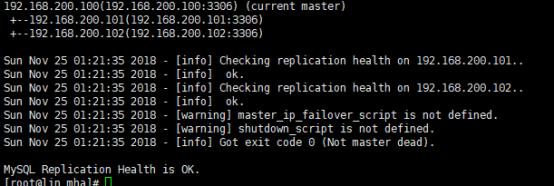
启动MHA
运行nohup masterha_manager --conf=/etc/mha/mha1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/mha1/manager.log 2>&1 &

以上是关于(项目六)Mha-Atlas-MySQL高可用方案实践的主要内容,如果未能解决你的问题,请参考以下文章