一、MHA介绍
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
MHA(Master High Availability)目前在mysql高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是日本的一位MySQL专家采用Perl语言编写的一个脚本管理工具,该工具仅适用于MySQLReplication(二层)环境,目的在于维持Master主库的高可用性。是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA是自动的master故障转移和Slave提升的软件包.它是基于标准的MySQL复制(异步/半同步).该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。1)MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Manager会定时探测集群中的node节点,当发现master 出现故障的时候,它可以自动将具有最新数据的slave提升为新的master,然后将所有其它的slave导向新的master上.整个故障转移过程对应用程序是透明的。2)MHA Node运行在每台MySQL服务器上,它通过监控具备解析和清理logs功能的脚本来加快故障转移的。在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。 |
二、MHA工作架构说明
展示了如何通过MHA Manager管理多组主从复制。可以将MHA工作原理总结为如下:
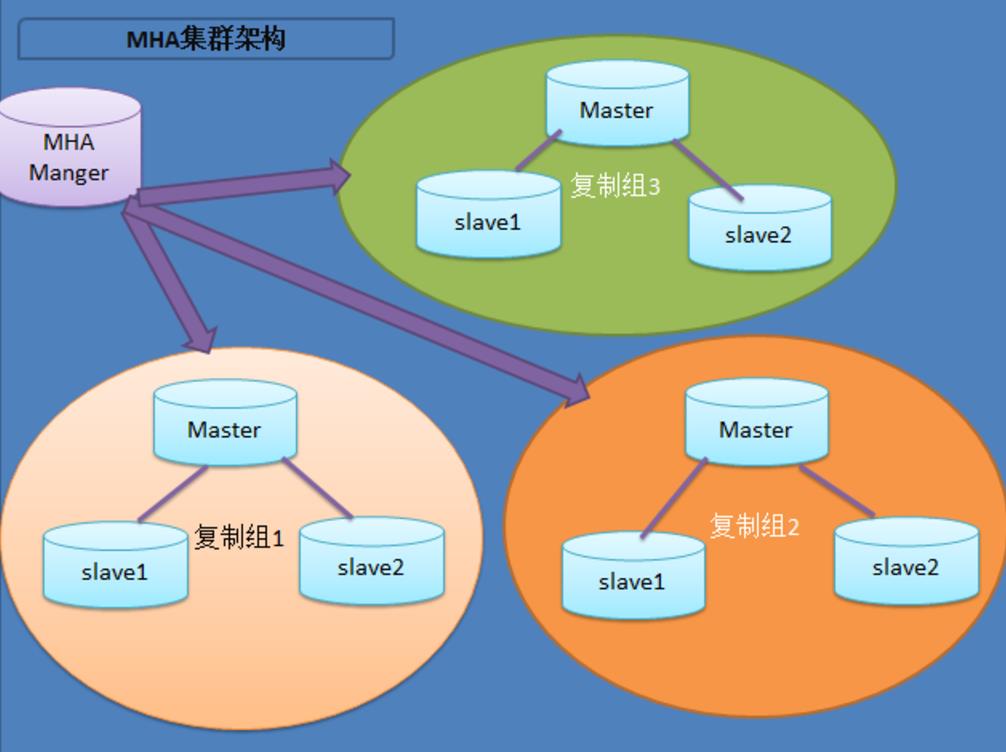
|
1
2
3
4
5
6
7
8
|
相较于其它HA软件,MHA的目的在于维持MySQL Replication中Master库的高可用性,其最大特点是可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并将其它Slave指向它。工作流程主要如下:1)从宕机崩溃的master保存二进制日志事件(binlog events);2)识别含有最新更新的slave;3)应用差异的中继日志(relay log)到其他的slave;4)应用从master保存的二进制日志事件(binlog events);5)提升一个slave为新的master;6)使其他的slave连接新的master进行复制; |
MHA工作原理

|
1
2
3
4
5
|
当master出现故障时,通过对比slave之间I/O线程读取master binlog的位置,选取最接近的slave做为latest slave。其它slave通过与latest slave对比生成差异中继日志。在latest slave上应用从master保存的binlog,同时将latest slave提升为master。最后在其它slave上应用相应的差异中继日志并开始从新的master开始复制。在MHA实现Master故障切换过程中,MHA Node会试图访问故障的master(通过SSH),如果可以访问(不是硬件故障,比如InnoDB数据文件损坏等),会保存二进制文件,以最大程度保证数据不丢失。MHA和半同步复制一起使用会大大降低数据丢失的危险。 |
MHA软件的架构:由两部分组成,Manager工具包和Node工具包,具体的说明如下。
Manager工具包主要包括以下几个工具:
|
1
2
3
4
5
6
7
|
masterha_check_ssh 检查MHA的SSH配置状况masterha_check_repl 检查MySQL复制状况masterha_manger 启动MHAmasterha_check_status 检测当前MHA运行状态masterha_master_monitor 检测master是否宕机masterha_master_switch 控制故障转移(自动或者手动)masterha_conf_host 添加或删除配置的server信息 |
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
save_binary_logs(保存二进制日志) 保存和复制master的二进制日志apply_diff_relay_logs(应用差异中继日志) 识别差异的中继日志事件并将其差异的事件应用于其他的slavefilter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)purge_relay_logs(清理中继日志) 清除中继日志(不会阻塞SQL线程).....................................................................................................MHA如何保持数据的一致性呢?主要通过MHA node的以下几个工具实现,但是这些工具由mha manager触发:save_binary_logs 如果master的二进制日志可以存取的话,保存复制master的二进制日志,最大程度保证数据不丢失 apply_diff_relay_logs 相对于最新的slave,生成差异的中继日志并将所有差异事件应用到其他所有的slave注意:对比的是relay log,relay log越新就越接近于master,才能保证数据是最新的。purge_relay_logs删除中继日志而不阻塞sql线程 |
MHA的优势
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
1)故障切换快在主从复制集群中,只要从库在复制上没有延迟,MHA通常可以在数秒内实现故障切换。9-10秒内检查到master故障,可以选择在7-10秒关闭master以避免出现裂脑,几秒钟内,将差异中继日志(relay log)应用到新的master上,因此总的宕机时间通常为10-30秒。恢复新的master后,MHA并行的恢复其余的slave。即使在有数万台slave,也不会影响master的恢复时间。DeNA在超过150个MySQL(主要5.0/5.1版本)主从环境下使用了MHA。当mater故障后,MHA在4秒内就完成了故障切换。在传统的主动/被动集群解决方案中,4秒内完成故障切换是不可能的。2)master故障不会导致数据不一致当目前的master出现故障时,MHA自动识别slave之间中继日志(relay log)的不同,并应用到所有的slave中。这样所有的salve能够保持同步,只要所有的slave处于存活状态。和Semi-Synchronous Replication一起使用,(几乎)可以保证没有数据丢失。3)无需修改当前的MySQL设置MHA的设计的重要原则之一就是尽可能地简单易用。MHA工作在传统的MySQL版本5.0和之后版本的主从复制环境中。和其它高可用解决方法比,MHA并不需要改变MySQL的部署环境。MHA适用于异步和半同步的主从复制。启动/停止/升级/降级/安装/卸载MHA不需要改变(包扩启动/停止)MySQL复制。当需要升级MHA到新的版本,不需要停止MySQL,仅仅替换到新版本的MHA,然后重启MHA Manager就好了。MHA运行在MySQL
5.0开始的原生版本上。一些其它的MySQL高可用解决方案需要特定的版本(比如MySQL集群、带全局事务ID的MySQL等等),但并不仅仅为了master的高可用才迁移应用的。在大多数情况下,已经部署了比较旧MySQL应用,并且不想仅仅为了实现Master的高可用,花太多的时间迁移到不同的存储引擎或更新的前沿发行版。MHA工作的包括5.0/5.1/5.5的原生版本的MySQL上,所以并不需要迁移。4)无需增加大量的服务器MHA由MHA Manager和MHA Node组成。MHA Node运行在需要故障切换/恢复的MySQL服务器上,因此并不需要额外增加服务器。MHA Manager运行在特定的服务器上,因此需要增加一台(实现高可用需要2台),但是MHA Manager可以监控大量(甚至上百台)单独的master,因此,并不需要增加大量的服务器。即使在一台slave上运行MHA Manager也是可以的。综上,实现MHA并没用额外增加大量的服务。5)无性能下降MHA适用与异步或半同步的MySQL复制。监控master时,MHA仅仅是每隔几秒(默认是3秒)发送一个ping包,并不发送重查询。可以得到像原生MySQL复制一样快的性能。6)适用于任何存储引擎MHA可以运行在只要MySQL复制运行的存储引擎上,并不仅限制于InnoDB,即使在不易迁移的传统的MyISAM引擎环境,一样可以使用MHA。 |
三、MHA高可用环境部署记录
1)机器环境
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
ip地址 主机名 角色182.48.115.236 Node_Master 写入,数据节点182.48.115.237 Node_Slave 读,数据节点,备选Master(candicate master)182.48.115.238 Manager_Slave 读,数据节点,也作为Manager server(即也作为manager节点)........................................................................................................为了节省机器,这里选择只读的从库182.48.115.237(从库不对外提供读的服务)作为候选主库,即candicate master,或是专门用于备份同样,为了节省机器,这里选择182.48.115.238这台从库作为manager server(实际生产环节中,机器充足的情况下, 一般是专门选择一台机器作为Manager server)........................................................................................................关闭三台机器的iptables和selinux部署节点之间ssh无密码登陆的信任关系(即在所有节点上做ssh免密码登录,包括对节点本机的信任)[root@Node_Master ~]# ssh-copy-id 182.48.115.236[root@Node_Master ~]# ssh-copy-id 182.48.115.237[root@Node_Master ~]# ssh-copy-id 182.48.115.238[root@Node_Slave ~]# ssh-copy-id 182.48.115.236[root@Node_Slave ~]# ssh-copy-id 182.48.115.237[root@Node_Slave ~]# ssh-copy-id 182.48.115.238[root@Manager_Slave ~]# ssh-copy-id 182.48.115.236[root@Manager_Slave ~]# ssh-copy-id 182.48.115.237[root@Manager_Slave ~]# ssh-copy-id 182.48.115.238现在3台节点已经能实现两两互相ssh通了,不需要输入密码即可。如果不能实现任何两台主机互相之间可以无密码登录,后面的环节可能会有问题。 |
2)实现主机名hostname登录(在三台节点上都需要执行)(这一步不是必须要操作的)
|
1
2
3
4
5
6
7
8
9
|
分别设置三台节点机器的主机名(主机名上面已提出),并绑定hosts.三台机器的/etc/hosts文件的绑定信息如下:[root@Node_Master ~]# vim /etc/hosts.......182.48.115.236 Node_Master182.48.115.237 Node_Slave182.48.115.238 Manager_Slave相互验证下使用主机名登陆是否正常,是否可以相互使用主机名ssh无密码登陆到对方。 |
3)准备好Mysql主从环境
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
架构如下,一主二从的架构:主库:182.48.115.236 从库:182.48.115.237主库:182.48.115.236 从库:182.48.115.238.......................................................................................------主库配置------server-id=1 log-bin=mysql-bin binlog-ignore-db=mysql sync_binlog = 1 binlog_checksum = none binlog_format = mixed------从库1配置-------server-id=2 log-bin=mysql-bin binlog-ignore-db=mysql //千万要注意:主从同步中的过滤字段要一致,否则后面使用masterha_check_repl 检查复制时就会出错!slave-skip-errors = all------从库2配置-------server-id=3 log-bin=mysql-bin binlog-ignore-db=mysql slave-skip-errors = all 然后主库授权给从库连接的权限,设置后,最好在从库上验证下是否能使用授予的权限连接主库。然后在从库上根据主库的“show master status;” 信心进行change master.....同步设置。注意:主从设置时,如果设置了bbinlog-ignore-db 和 replicate-ignore-db 过滤规则,则主从必须相同。即要使用binlog-ignore-db过滤字段,则主从配置都使用这个,要是使用replicate-ignore-db过滤字段,则主从配置都使用这个,千万不能主从配置使用的过滤字段不一样!因为MHA 在启动时候会检测过滤规则,如果过滤规则不同,MHA 不启动监控和故障转移。....................................................................................... |
4)创建用户mha管理的账号(在三台节点上都需要执行)
|
1
2
3
4
5
6
7
8
9
10
11
12
|
mysql> GRANT SUPER,RELOAD,REPLICATION CLIENT,SELECT ON *.* TO manager@\'182.48.115.%\' IDENTIFIED BY \'manager_1234\';Query OK, 0 rows affected (0.06 sec)mysql> GRANT CREATE,INSERT,UPDATE,DELETE,DROP ON*.* TO manager@\'182.48.115.%\';Query OK, 0 rows affected (0.05 sec)创建主从账号(在三台节点上都需要执行):mysql> GRANT RELOAD, SUPER, REPLICATION SLAVE ON*.* TO \'repl\'@\'182.48.115.%\' IDENTIFIED BY \'repl_1234\';Query OK, 0 rows affected (0.09 sec)mysql> flush privileges;Query OK, 0 rows affected (0.06 sec) |
5)开始安装mha
mha包括manager节点和data节点,其中:
data节点包括原有的MySQL复制结构中的主机,至少3台,即1主2从,当master failover后,还能保证主从结构;只需安装node包。
manager server:运行监控脚本,负责monitoring 和 auto-failover;需要安装node包和manager包。
5.1)在所有data数据节点机上安装安装MHA node
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
下载mha4mysql-node-0.56.tar.gz下载地址:http://pan.baidu.com/s/1cphgLo提取密码:7674 [root@Node_Master ~]# yum -y install perl-DBD-MySQL //先安装所需的perl模块[root@Node_Master ~]# tar -zvxf mha4mysql-node-0.56.tar.gz [root@Node_Master ~]# cd mha4mysql-node-0.56[root@Node_Master mha4mysql-node-0.56]# perl Makefile.PL................................................................................................................这一步可能报错如下:1)Can\'t locate ExtUtils/MakeMaker.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5......解决办法:[root@Node_Master mha4mysql-node-0.56]# yum install perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker2)Can\'t locate CPAN.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5....解决办法:[root@Node_Master mha4mysql-node-0.56]# yum install -y perl-CPAN ................................................................................................................[root@Node_Master mha4mysql-node-0.56]# make && make install |
5.2)在manager节点(即182.48.115.238)上安装MHA Manager(注意manager节点也要安装MHA node)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
首先下载第三方yum源[root@Manager_Slave ~]# rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm安装perl的mysql包:[root@Manager_Slave ~]#
yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch
perl-Parallel-ForkManager perl-Config-IniFiles perl-Time-HiRes -y安装MHA Manager软件包:下载地址:https://pan.baidu.com/s/1slyfXN3提取密码:86wb[root@Manager_Slave ~]# tar -vxf mha4mysql-manager-0.56.tar [root@Manager_Slave ~]# cd mha4mysql-manager-0.56 [root@Manager_Slave mha4mysql-manager-0.56]# perl Makefile.PL [root@Manager_Slave mha4mysql-manager-0.56]# make && make install安装完MHA Manager后,在/usr/local/bin目录下会生成以下脚本:[root@Manager_Slave mha4mysql-manager-0.56]# ll /usr/local/bin/总用量 84-r-xr-xr-x. 1 root root 16367 5月 31 21:37 apply_diff_relay_logs-r-xr-xr-x. 1 root root 4807 5月 31 21:37 filter_mysqlbinlog-r-xr-xr-x. 1 root root 1995 5月 31 22:23 masterha_check_repl-r-xr-xr-x. 1 root root 1779 5月 31 22:23 masterha_check_ssh-r-xr-xr-x. 1 root root 1865 5月 31 22:23 masterha_check_status-r-xr-xr-x. 1 root root 3201 5月 31 22:23 masterha_conf_host-r-xr-xr-x. 1 root root 2517 5月 31 22:23 masterha_manager-r-xr-xr-x. 1 root root 2165 5月 31 22:23 masterha_master_monitor-r-xr-xr-x. 1 root root 2373 5月 31 22:23 masterha_master_switch-r-xr-xr-x. 1 root root 5171 5月 31 22:23 masterha_secondary_check-r-xr-xr-x. 1 root root 1739 5月 31 22:23 masterha_stop-r-xr-xr-x. 1 root root 8261 5月 31 21:37 purge_relay_logs-r-xr-xr-x. 1 root root 7525 5月 31 21:37 save_binary_logs其中:masterha_check_repl 检查MySQL复制状况masterha_check_ssh 检查MHA的SSH配置状况masterha_check_status 检测当前MHA运行状态masterha_conf_host 添加或删除配置的server信息masterha_manager 启动MHAmasterha_stop 停止MHAmasterha_master_monitor 检测master是否宕机masterha_master_switch 控制故障转移(自动或者手动)masterha_secondary_check 多种线路检测master是否存活另外:在../mha4mysql-manager-0.56/samples/scripts下还有以下脚本,需要将其复制到/usr/local/bin[root@Manager_Slave mha4mysql-manager-0.56]# cd samples/scripts/[root@Manager_Slave scripts]# ll总用量 32-rwxr-xr-x. 1 4984 users 3648 4月 1 2014 master_ip_failover //自动切换时VIP管理脚本,不是必须,如果我们使用keepalived的,我们可以自己编写脚本完成对vip的管理,比如监控mysql,如果mysql异常,我们停止keepalived就行,这样vip就会自动漂移-rwxr-xr-x. 1 4984 users 9870 4月 1 2014 master_ip_online_change //在线切换时VIP脚本,不是必须,同样可以可以自行编写简单的shell完成-rwxr-xr-x. 1 4984 users 11867 4月 1 2014 power_manager //故障发生后关闭master脚本,不是必须-rwxr-xr-x. 1 4984 users 1360 4月 1 2014 send_report //故障切换发送报警脚本,不是必须,可自行编写简单的shell完成[root@Manager_Slave scripts]# cp ./* /usr/local/bin/ |
5.3)在管理节点(182.48.115.238)上进行下面配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
[root@Manager_Slave mha4mysql-manager-0.56]# mkdir -p /etc/masterha [root@Manager_Slave mha4mysql-manager-0.56]# cp samples/conf/app1.cnf /etc/masterha/[root@Manager_Slave mha4mysql-manager-0.56]# vim /etc/masterha/app1.cnf [server default]manager_workdir=/var/log/masterha/app1 //设置manager的工作目录manager_log=/var/log/masterha/app1/manager.log //设置manager的日志 ssh_user=root //ssh免密钥登录的帐号名repl_user=repl //mysql复制帐号,用来在主从机之间同步二进制日志等repl_password=repl_1234 //设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码ping_interval=1 //设置监控主库,发送ping包的时间间隔,用来检查master是否正常,默认是3秒,尝试三次没有回应的时候自动进行railovermaster_ip_failover_script= /usr/local/bin/master_ip_failover //设置自动failover时候的切换脚本master_ip_online_change_script= /usr/local/bin/master_ip_online_change //设置手动切换时候的切换脚本 [server1]hostname=182.48.115.236port=3306master_binlog_dir=/data/mysql/data/ //设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录 [server2]hostname=182.48.115.237port=3306candidate_master=1 //设置为候选master,即master机宕掉后,优先启用这台作为新master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slavecheck_repl_delay=0 //默认情况下如果一个slave落后master
100M的relay
logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的mastermaster_binlog_dir=/data/mysql/data/ [server3]hostname=182.48.115.238Linux云计算-MySQL-高可用集群架构-MHA 架构
|