redis的LRU算法
Posted lifehacker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis的LRU算法相关的知识,希望对你有一定的参考价值。
前文再续,书接上一回。上次讲到redis的LRU算法,文章实在精妙,最近可能有机会用到其中的技巧,顺便将下半部翻译出来,实现的时候参考下。
搏击俱乐部的第一法则:用裸眼观测你的算法
Redis2.8的LRU实现已经上线了,在不同的负载环境下经过测试,用户没有抱怨Redis的清理机制。为了继续改进,我希望能观察到算法的性能,同时不会浪费大量CPU,不增加1比特空间占用。
我设计了一个测试用例。导入指定数量的key,然后顺序访问他们,好让他们的最近访问时间顺序递减。再添加50%的key,那么之前的key有50%就会被淘汰掉。理想情况下,被淘汰的应该是前50%的。如下图:
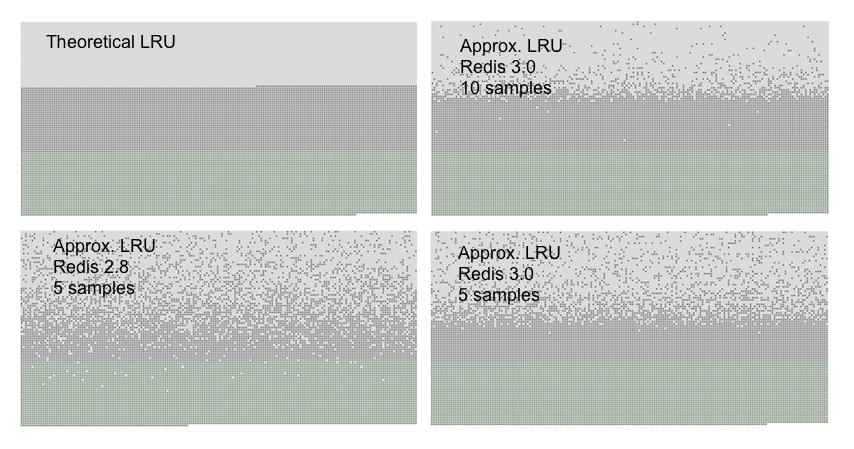
绿色的是新添加的key,灰色的是第一次添加的key,白色表示被移除的。
LRU v2:不要丢掉重要信息
当采用了N-key取样时,默认会建立16个key的池,将里面的key按空闲时间排序。新key只会在池不满或者空闲时间大于池里最小的,才能进池。
这个实现极大的提升了性能,实现又简单,没有大bug。只要一点点性能监控和一些memmove()就完成了。
同时,新的redis-cli模式(-lru-test)支持测试LRU精度,可以更接近真实的负载来看新算法的工况,尝试不同算法的时候,至少可以发现明显的速度退化。
最近最少访问(LFU)
我最近又部分重构了Redis cache的换页算法。这些工作源于一个issue:当你在Redis 3.2有多个数据库的时候,算法总是做局部选择。比如DB 0的所有key都用的很频繁,DB 1的所有key都用的很少。Redis会从每个DB里丢弃一个key。理性的选择应该是先丢弃DB 1的key,丢完以后再丢DB 0的
Redis用作cache的时候,通常不会跟不同DB混合用,但我还是开始着手改进,最后将db的id包括在池里,然后所有DB都共用一个池,这个实现比原始先快20%
这次改进激起了我对Redis这块子系统的好奇心。我花了好些天进行优化,如果我用一个大点的池子,会好点吗?如果选择key的时候考虑了流逝的时间,效果会不会更好?
最后,我终于明白到,LRU算法会受到取样数量限制,只要数量足够,效果就很好,很难再改进。正如上图所示,每次取样10个键,已经和理论上的LRU几乎一样准确了。
因为原始算法难以改进,我开始想其他办法。回顾前文,其实我们真正想要的,是保留未来最有可能访问的key,即是最常访问的key,而不是最新访问的key。这就是LFU算法。理论上LFU的实现很简单,只要给每个key挂一个计数器,我们就可以知道给定的key是不是比另一个key访问更多了。
当然,LFU的实现上有几个通用的难点:
1. LFU里没法使用链表法转移到头部的技巧了。因为完美LFU需要key严格按访问量排序。当访问量一致时,排序算法可能劣化为O(N),即使计数器只变了一点点
2. LFU没法简单的只在访问时对计数器加一。因为访问模式会随着时间发生变化,所以一个高分的key需要随着时间流逝而分数递减。
在Redis里第一个问题不是问题,我们可以沿用LRU的随机取样方法。第二个问题仍然存在,我们需要一个方法来递减分数,或者随着时间流逝将计数器折半。
24bit空间实现的LFU
在Redis里,我们可以用的就是LRU的24bit空间,需要一些奇技淫巧来实现。
在24bit空间里,需要塞下:
1. 某种类型的访问计数器
2. 足够的信息来决定何时折半计数器
我的解决方案如下:
16 bits 8 bits +----------------+--------+ + Last decr time | LOG_C | +----------------+--------+
8bit用来计数,16bit用来记录上次递减的时间
你可能会认为,8bit计数器很快就会溢出了吧?这就是技巧所在:我用的是对数计数器。具体代码如下:
uint8_t LFULogIncr(uint8_t counter) { if (counter == 255) return 255; double r = (double)rand()/RAND_MAX; double baseval = counter - LFU_INIT_VAL; if (baseval < 0) baseval = 0; double p = 1.0/(baseval*server.lfu_log_factor+1); if (r < p) counter++; return counter; }
计数器的值越大,真正加一的概率越小。上述代码算出一个概率p,介乎0到1之间,计数器越大,p越小。然后生成0-1之间的随机数r,只有r<p的时候,计数器才会加一。
现在我们来看看计数器折半的问题。转成分钟为单位的unix时间,低16位会存在上面保留的16位空间内。当Redis进行随机取样,扫描key空间的时候,所有遇到的key都会被检查是否应该递减。如果上次递减实在N分钟之前(N是可配置的),并且计数器的值是高分值,那计数器就会被折半。如果计数器是低分值,则只会递减。(希望我们可以更好的分辨少访问量的key,因为我们的计数器精度比较低)
还有一个问题,新的key需要一个生存的机会。Redis里新key会从5分开始。上面的递减算法已经考虑到这个分数,如果key分数低于5分,更容易被丢弃(一般是长时间没访问的非活跃key)。
以上是关于redis的LRU算法的主要内容,如果未能解决你的问题,请参考以下文章