JDK之数据结构---集合
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK之数据结构---集合相关的知识,希望对你有一定的参考价值。
参考技术A 集合的分类ArrayList与LinkedList区别
HashSet、TreeSet、LinkedHashSet的区别
HashMap、TreeMap、LinkedHashMap区别
HashMap、HashTable的区别
HashSet、HashMap区别
HashMap是怎么样的存储格式,怎么样扩容,怎么处理冲突
集合安全问题
1.数组与集合的区别:
数组是静态的,固定大小的,相对集合来说轻量级。而集合是可以动态扩展容量。
2.集合的分类
java中的集合框架有两个基本接口
Collection框架:List接口(ArrayList、LinkedList)、Set接口(HashSet、TreeSet、LinkedHashSet)、Queue接口(ArrayDeque一种用循环数组实现的双端队列)
Map框架(键值对存储):(HashMap、TreeMap、LinkedHashMap)
3.ArrayList与LinkedList区别
ArrayList是可改变大小的数组,动态增长的索引序列,存储空间是连续分布的,数组中任意元素的访问的时间复杂度为O(1),访问快速,但是增加删除需要移动大量元素,速度慢。
而LinkedList,高效插入和删除的有序序列,存储空间动态分配,访问链表的元素,需要从第一个到访问的那个元素,速度相对较慢,而对于增加和删除元素,只需修改元素的指针就行,相对较快。
4.HashSet、TreeSet、LinkedHashSet的区别
HashSet:是一种没有重复元素的无序集合。
TreeSet:是一种有序集合。
LinkedHashSet:使用链表维护元素的次序,通过元素的插入顺序保存的有序集合。
备注:当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
如果两个对象通过equals方法比较返回true时,其hashCode也是相同的。反之如果hashCode相同,equals不一定相同。
5.HashMap、TreeMap、LinkedHashMap区别
HashMap:一种存储键值关联的无序散列映射表。
TreeMap:一种有序存储键值的映射表。
LinkedHashMap:一种记住键值插入次序的映射表。
6.HashMap、HashTable的区别
HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。而HashTable支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。
HashMap最多只允许一条记录的键为Null,允许多条记录的值为 Null。而HashTable它不允许记录的键或者值为空。
7.HashSet、HashMap区别
HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key。
HashSet实现了Set接口,HashMap实现了Map接口
HashSet仅存储对象key,HashMap是对键值对的映射
HashSet实添加元素是add,HashMap添加元素用put
8.HashMap是怎么样的存储格式,怎么样扩容,怎么处理冲突?
a.键值对存储,由散列函数hashCode()为实例对象产生一个散列码hashcode,将散列码与桶的总数取余,得到索引存储在散列表hashtable中,在散列表内部,用桶来保存键值对,用链表或数组实现。
b.扩容:负载因子0.75 如果表中超过75%的位置已经填入元素,那么这个表就会用双倍的桶数进行再散列。
c.冲突处理:hashmap的冲突处理是拉链法
d.其他解决冲突处理的方法:
开放地址法:查找数组中的空位
线性探测法:查找冲突位置的下一个位置
拉链法:使用链表解决,将冲突的key放到原来的数据节点后面
9.集合安全:
a.线程安全类(Vector、HashTable)在核心方法上加了synchronized
ArrayList不支持线程同步,而Vector增加同步机制,线程安全。
HashMap不支持线程的同步,而HashTable相比较增加同步机制,线程安全。
b.Collections类:(1.5后新加)
可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,synchronizedList等方法
提供了多个静态方法,包装集合,将指定集合包装成线程同步的集合。
c.并发集合(ConcurrentHashMap):
通过复杂的策略,不仅保证了多线程的安全,也提高了并发的效率。
最核心的就是锁分段技术,不直接对整个hashmap的表锁定,由多个segment组成。
集合之LinkedList(含JDK1.8源码分析)
LinkedList的数据结构
LinkedList的增删改查
增:add
说明:add函数用于向LinkedList中添加一个元素,并且添加到链表尾部。具体添加到尾部的逻辑是由linkLast函数完成的。
举例:
public class Test { public static void main(String[] args) { List<String> list = new LinkedList<>(); list.add("zhangsan"); list.add("lisi"); list.add("wangwu");
list.add("zhangsan");
System.out.println(list);
}
}
结果:
[zhangsan, lisi, wangwu, zhangsan]
add源码分析:
/** * Appends the specified element to the end of this list. * * <p>This method is equivalent to {@link #addLast}. * * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { linkLast(e); return true; }
LinkLast方法如下:
/** * Links e as last element. */ void linkLast(E e) { //将last节点保存 final Node<E> l = last; //构造新节点 final Node<E> newNode = new Node<>(l, e, null); //将新构造的节点赋值给last节点,便于下次添加元素时使用 last = newNode; //判断保存的last节点是否为null if (l == null) //为null,首次添加,first节点与last节点一样,都是新节点 first = newNode; else //不为null,说明list中已有元素,将newNode赋值给未添加元素e之前,list中已经存在的last节点的next属性 l.next = newNode; //size加1 size++; //结构性修改加1 modCount++; }
图示说明添加元素后链表状态的改变:
list.add("zhangsan");
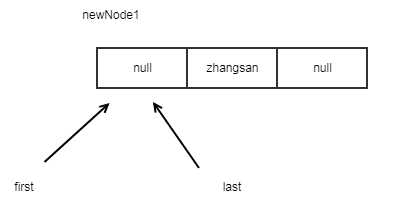
list.add("lisi");
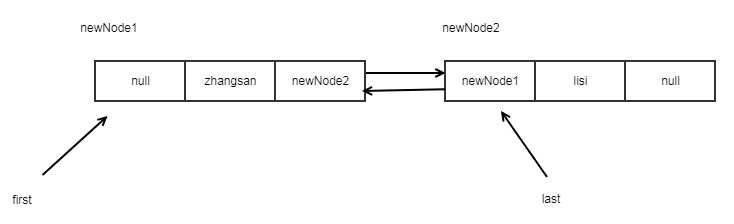
list.add("wangwu");
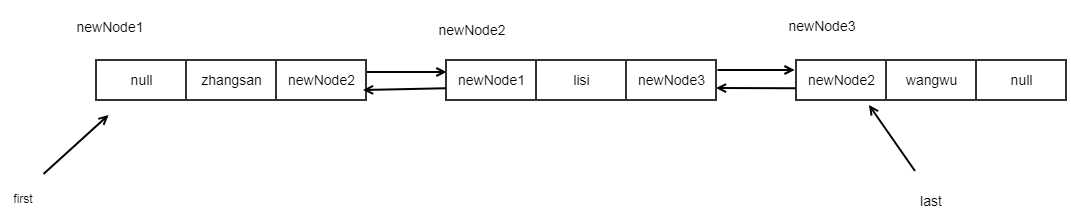
由此可见,双向链表的含义即:由上一个节点的next属性可以得到下一个节点,下一个节点的prev属性可以得到上一个节点。上下两个节点之间互相指向关联。
以上是关于JDK之数据结构---集合的主要内容,如果未能解决你的问题,请参考以下文章