大话JDK之数据结构和算法
Posted 码农私房菜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大话JDK之数据结构和算法相关的知识,希望对你有一定的参考价值。
不像C C++工程师,Java工程师对数据结构算法的感情可能没那么深,这要归功于JDK封装得漂亮呀。集合框架两大块,Collection和Map,Collection下是List、Set、Queue三大接口。又封装了Collections、Arrays等工具类。太特么友好了。
今天就来拆解一下JDK中的数据结构和算法实现。
动态数组
在封装的集合里面,用到数组基本上就都是动态数组。数组和链表作为计算机底层存储数据的两个最大载体,数组以O(1)效率寻址而被广泛使用=。=
ArrayList,内部是动态数组,初始化容量是10,扩容为原容量1.5倍。这是Java中最常用的数据结构了,但是线程不安全。线程安全的动态数组是Vector,使用synchronized实现线程安全。当然也可以用Collections.synchronizedList方法包装一下,也是线程安全的。不过synchronized的性能可能不是最好的。对于并发动态数组,JDK中还提供了CopyOnWriteArrayList,读写分离的思想,或者说是一种“不变模式”面对并发,要修改的时候,不修改原来的数组,而是复制一份修改复制出来的数组,修改完之后再改一下引用,比较巧妙地避开了锁的使用。适用于读多写少的场景,读读,读写都可以并行。缺点是弱一致性。
HashMap,底层也使用了数组,不管是数组+链表还是数组+链表+红黑树,数组才是HashMap高效率的根本原因。
ArrayDeque,用循环数组实现的双端队列,可以当栈使用,不常用。
PriorityQueue,这也是堆的实现,这个特殊的二叉树,因为元素之间特殊的关系,而用数组表示。具体下面再讲。
双向链表
LinkedList,比较常用的数据结构,特点是按需分配空间不需要多分配也不需要扩容,优缺点基本上和数组对立。Java中基本上带有linked的都使用双向链表实现的。例如还有LinkedHashMap,LinkedHashSet,ConcurrentLinkedQueue等。
队列
Queue这个接口的实现,都是队列。
实现类相当多,文档上来看,有这么些。
ArrayBlockingQueue , ArrayDeque , ConcurrentLinkedDeque , ConcurrentLinkedQueue , DelayQueue , LinkedBlockingDeque , LinkedBlockingQueue , LinkedList , LinkedTransferQueue , PriorityBlockingQueue , PriorityQueue , SynchronousQueue
高富帅队列里分为两大块,
阻塞队列,用ReentrantLock实现的。LinkedBlockingQueue ArrayBlockingQueue PriorityBlockingQueue DelayQueue
非阻塞队列,用CAS实现。 ConcurrentLinkedQueue LinkedTransferQueue
屌丝队列就是,LinkedList ArrayDeque这种...
栈
Stack,就是栈,他没有子类了。
Java中Deque这个接口以及他的子类,也是LIFO操作的。例如上面提到的ArrayDeque,的确既可以先进先出也可以后进先出,实现了多个接口当然就支持多种结构。看右下角实现的接口。
哈希表
HashMap,HashSet,LinkedHashMap,以及并发的容器,ConcurrentHashMap等。这个家族,以后再“细说”。
跳跃表
ConcurrentSkipListMap,在链表的基础上加了多层索引结构,有序、无锁并发容器。
红黑树
JDK中带有Tree的都是红黑树实现的,TreeMap、TreeSet、。红黑树是一种非绝对平衡的二叉树,要理解红黑树的话,最好是先理解一下二三树,二三树是绝对平衡的树,稍微转变一下就成了红黑树了。
堆
PriorityQueue,逻辑上是树,物理存储结构是动态数组。
循环数组
ArrayDeque,循环数组,专门维护了头尾变量,使得队列操作非常高效。
位向量
EnumSet,BitSet都是位向量的实现,非常高效。
算法:
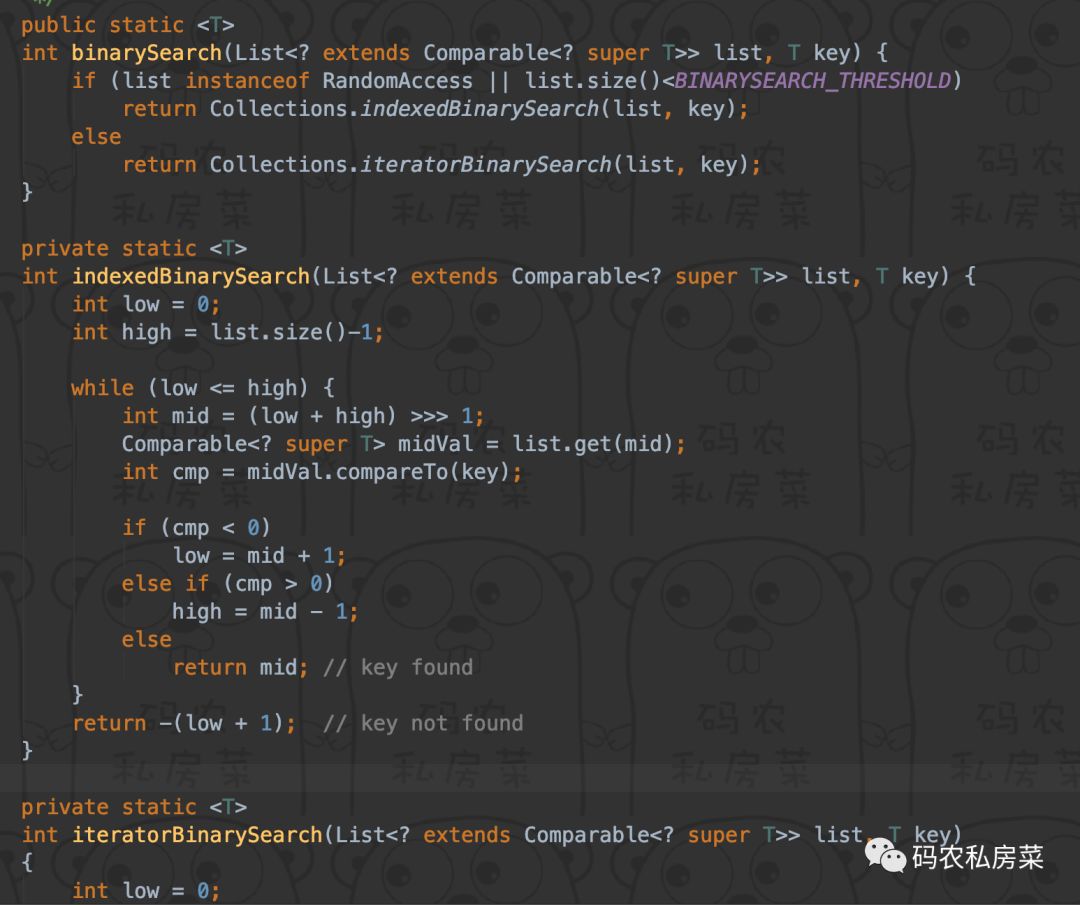
二分查找
Collections.binarySearch()
对于实现了随机读取接口的数组类List还判断了一下,采取不同策略。一个用get(i)一个用Iterator方式。
排序-插入、堆、快排、归并
排序的策略一直在变化(优化),以JDK1.8为例哈。
相关类和方法,
Arrays.sort()系列重载方法。首先是一发判断,如果配置了要使用传统的归并排序,则使用归并排序,否则使用ComparableTimSort。具体归并的逻辑是如果长度小于7,就使用插入排序,否则使用归并。

ComparableTimSort,这是对归并排序的一种优化,效率更高更稳定。
DualPivotQuicksort,非常高端的优化版的快排。这两个都需要以后“细说”
哈希算法
好的哈希算法,分散而单调。以String和HashMap中哈希算法为例。好像我也无能为力评判这两个哈希算法=。=
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
LRU
这是缓存淘汰用的算法,核心原理是认为经常使用的数据下次使用的概率会高很多。所以缓存被使用了就放链表前面,缓存空间不够了就从尾部删除数据。
LinkedHashMap就是顺序存储元素,也可以通过构造函数开启按照顺序访问元素,即实现了LRU。
以上是关于大话JDK之数据结构和算法的主要内容,如果未能解决你的问题,请参考以下文章