大数据框架-spark
Posted xiongchang95
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据框架-spark相关的知识,希望对你有一定的参考价值。
相关详细说明:https://www.csdn.net/article/2015-07-10/2825184
RDD:弹性分布式数据集。
Operation:Transformation 和Action,一个返回RDD,一个返回值。
Lineage:RDD之间的依赖关系,如何演变过来。
Partition:RDD分区,按block切分
narrow dependency(窄依赖) :父RDD全进入子RDD
wide dependency(宽依赖)
Application[一个spark-submit提交的程序]
Job[一个计算序列的最终结果Action操作,多个RDD以及作用于RDD之上的Operation]
stage[计算序列的中间结果]
[划分stage 的重要依据是有无shuflle (数据重组)发生,由DAGSchedule进行划分,Shuffle在Spark中是把父RDD中KV对按照Key重新分区,得到一个新的子RDD,包括这几个操作reduceByKey、groupByKey、sortByKey、countByKey、join、cogroup]
Task[每个partition在一个executor上的Operation是一个Task,即一个thread]
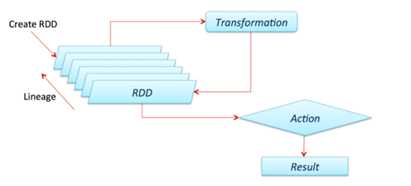
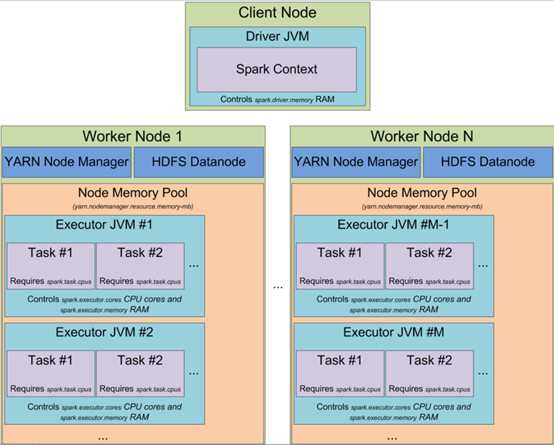
Spark(standalone模式)基本组件;
master(RM):负责资源管理,sparkonYarn模式下就是RM
worker(NM):一个worker可以有多个executor
executor(Container,可以看作资源集合、也可看作task的执行池,一个JVM进程):
当以YARN模式启动spark集群时,可以指定
executors的数量(-num-executors 或者 spark.executor.instances 参数)
executor 固有的内存大小(-executor-memory 或者 spark.executor.memory),executor使用的cpu核数(-executor-cores 或者 spark.executor.cores)
executor分配给每个task的core的数量(spark.task.cpus)
driver 上使用的内存(-driver-memory 或者 spark.driver.memory)。
driver(AppMaster):申请资源并监控任务执行状态。通过DAGScheduler划分形成TaskSet,将具体Task交给对应worker中的executor线程池执行。
以上是关于大数据框架-spark的主要内容,如果未能解决你的问题,请参考以下文章
流式大数据处理的三种框架:Storm,Spark和Samza