一起学Hadoop——二次排序算法的实现
Posted alunbar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一起学Hadoop——二次排序算法的实现相关的知识,希望对你有一定的参考价值。
二次排序,从字面上可以理解为在对key排序的基础上对key所对应的值value排序,也叫辅助排序。一般情况下,MapReduce框架只对key排序,而不对key所对应的值排序,因此value的排序经常是不固定的。但是我们经常会遇到同时对key和value排序的需求,例如Hadoop权威指南中的求一年的高高气温,key为年份,value为最高气温,年份按照降序排列,气温按照降序排列。还有水果电商网站经常会有按天统计水果销售排行榜的需求等等,这些都是需要对key和value同时进行排序。如下图所示:
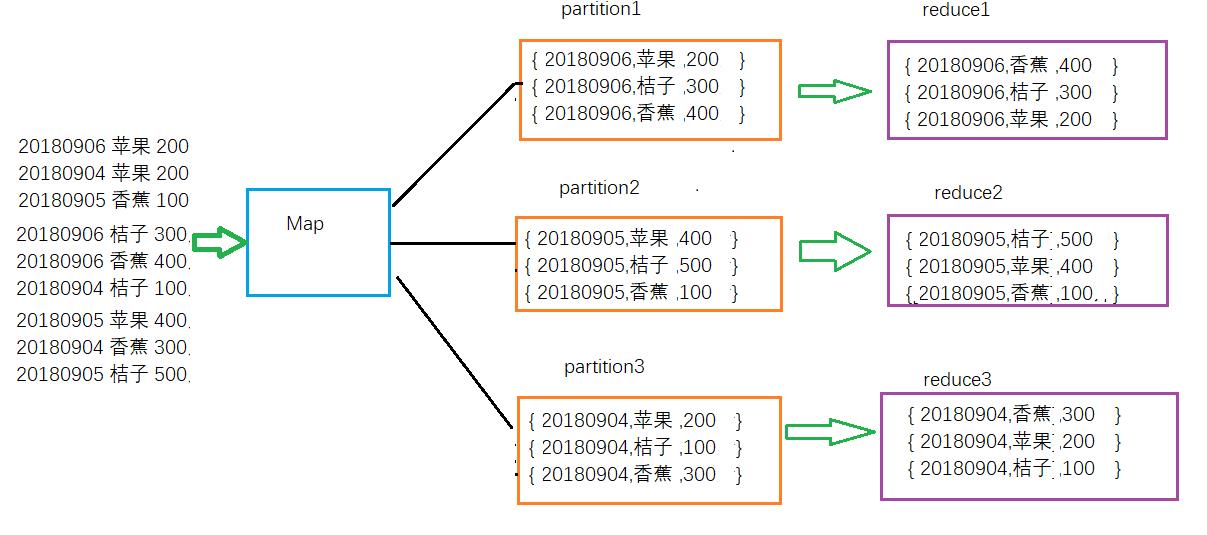
如何设计一个MapReduce程序解决对key和value同时排序的需求呢?这就需要用到组合键、分区、分组的概念。在这里又看到分区的影子,可知分区在MapReduce是多么的重要,一定要好好掌握,是优化的重点。
按照上图中数据流转的方向,我们首先设计一个Fruit类,有三个字段,分别是日期、水果名和销量,将日期、水果名和销量作为一个复合键;接着设计一个自定义Partition类,根据Fruit的日期字段分区,让相同日期的数据流向同一个partition分区中;最后定义一个分组类,实现同一个分区内的数据分组,然后按照销量字段进行二次排序。
具体实现思路:
1、定义Fruit类,实现WritableComparable接口,并且重写compareTo、equal和hashcode方法以及序列化和反序列化方法readFields和write方法。Java类要在网络上传输必须序列化和反序列化。在Map端的map函数中将Fruit对象当做key。compareTo方法用于比较两个key的大小,在本文中就是比较两个Fruit对象的排列顺序。
2、自定义第一次排序类,继承WritableComparable或者WritableComparator接口,重写compareTo或者compare方法,。就是在Map端对Fruit对象的第一个字段进行排序
3、自定义Partition类,实现Partitioner接口,并且重写getPartition方法,将日期相同的Fruit对象分发到同一个partition中。
4、定义分组类,继承WritableComparator接口,并且重写compare方法。用于比较同一分组内两个Fruit对象的排列顺序,根据销量字段比较。日期相同的Fruit对象会划分到同一个分组。通过setGroupingComparatorClass方法设置分组类。如果不设置分组类,则按照key默认的compare方法来对key进行排序。
代码如下:
1 import org.apache.hadoop.conf.Configured; 2 import org.apache.hadoop.io.WritableComparable; 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 import org.apache.hadoop.io.*; 7 import org.apache.hadoop.mapreduce.Partitioner; 8 import org.apache.hadoop.mapreduce.Mapper; 9 import org.apache.hadoop.mapreduce.Reducer; 10 import org.apache.hadoop.conf.Configuration; 11 import org.apache.hadoop.fs.FileSystem; 12 import org.apache.hadoop.fs.Path; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 17 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 18 import org.apache.hadoop.util.Tool; 19 import org.apache.hadoop.util.ToolRunner; 20 import org.slf4j.Logger; 21 import org.slf4j.LoggerFactory; 22 23 public class SecondrySort extends Configured implements Tool { 24 25 static class Fruit implements WritableComparable<Fruit>{ 26 private static final Logger logger = LoggerFactory.getLogger(Fruit.class); 27 private String date; 28 private String name; 29 private Integer sales; 30 public Fruit(){ 31 } 32 public Fruit(String date,String name,Integer sales){ 33 this.date = date; 34 this.name = name; 35 this.sales = sales; 36 } 37 38 public String getDate(){ 39 return this.date; 40 } 41 42 public String getName(){ 43 return this.name; 44 } 45 46 public Integer getSales(){ 47 return this.sales; 48 } 49 50 @Override 51 public void readFields(DataInput in) throws IOException{ 52 this.date = in.readUTF(); 53 this.name = in.readUTF(); 54 this.sales = in.readInt(); 55 } 56 57 @Override 58 public void write(DataOutput out) throws IOException{ 59 out.writeUTF(this.date); 60 out.writeUTF(this.name); 61 out.writeInt(sales); 62 } 63 64 @Override 65 public int compareTo(Fruit other) { 66 int result1 = this.date.compareTo(other.getDate()); 67 if(result1 == 0) { 68 int result2 = this.sales - other.getSales(); 69 if (result2 == 0) { 70 double result3 = this.name.compareTo(other.getName()); 71 if(result3 > 0) return -1; 72 else if(result3 < 0) return 1; 73 else return 0; 74 }else if(result2 >0){ 75 return -1; 76 }else if(result2 < 0){ 77 return 1; 78 } 79 }else if(result1 > 0){ 80 return -1; 81 }else{ 82 return 1; 83 } 84 return 0; 85 } 86 87 @Override 88 public int hashCode(){ 89 return this.date.hashCode() * 157 + this.sales + this.name.hashCode(); 90 } 91 92 @Override 93 public boolean equals(Object object){ 94 if (object == null) 95 return false; 96 if (this == object) 97 return true; 98 if (object instanceof Fruit){ 99 Fruit r = (Fruit) object; 100 // if(r.getDate().toString().equals(this.getDate().toString())){ 101 return r.getDate().equals(this.getDate()) && r.getName().equals(this.getName()) 102 && this.getSales() == r.getSales(); 103 }else{ 104 return false; 105 } 106 } 107 108 public String toString() { 109 return this.date + " " + this.name + " " + this.sales; 110 } 111 112 } 113 114 static class FruitPartition extends Partitioner<Fruit, NullWritable>{ 115 @Override 116 public int getPartition(Fruit key, NullWritable value,int numPartitions){ 117 return Math.abs(Integer.parseInt(key.getDate()) * 127) % numPartitions; 118 } 119 } 120 121 public static class GroupingComparator extends WritableComparator{ 122 protected GroupingComparator(){ 123 super(Fruit.class, true); 124 } 125 126 @Override 127 public int compare(WritableComparable w1, WritableComparable w2){ 128 Fruit f1 = (Fruit) w1; 129 Fruit f2 = (Fruit) w2; 130 131 if(!f1.getDate().equals(f2.getDate())){ 132 return f1.getDate().compareTo(f2.getDate()); 133 }else{ 134 return f1.getSales().compareTo(f2.getSales()); 135 } 136 } 137 } 138 139 public static class Map extends Mapper<LongWritable, Text, Fruit, NullWritable> { 140 141 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 142 String line = value.toString(); 143 String str[] = line.split(" "); 144 Fruit fruit = new Fruit(str[0],str[1],new Integer(str[2])); 145 //Fruit fruit = new Fruit(); 146 //fruit.set(str[0],str[1],new Integer(str[2])); 147 context.write(fruit, NullWritable.get()); 148 } 149 } 150 151 public static class Reduce extends Reducer<Fruit, NullWritable, Text, NullWritable> { 152 153 public void reduce(Fruit key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { 154 String str = key.getDate() + " " + key.getName() + " " + key.getSales(); 155 context.write(new Text(str), NullWritable.get()); 156 } 157 } 158 159 @Override 160 public int run(String[] args) throws Exception { 161 Configuration conf = new Configuration(); 162 // 判断路径是否存在,如果存在,则删除 163 Path mypath = new Path(args[1]); 164 FileSystem hdfs = mypath.getFileSystem(conf); 165 if (hdfs.isDirectory(mypath)) { 166 hdfs.delete(mypath, true); 167 } 168 169 Job job = Job.getInstance(conf, "Secondry Sort app"); 170 // 设置主类 171 job.setJarByClass(SecondrySort.class); 172 173 // 输入路径 174 FileInputFormat.setInputPaths(job, new Path(args[0])); 175 // 输出路径 176 FileOutputFormat.setOutputPath(job, new Path(args[1])); 177 178 // Mapper 179 job.setMapperClass(Map.class); 180 // Reducer 181 job.setReducerClass(Reduce.class); 182 183 // 分区函数 184 job.setPartitionerClass(FruitPartition.class); 185 186 // 分组函数 187 job.setGroupingComparatorClass(GroupingComparator.class); 188 189 // map输出key类型 190 job.setMapOutputKeyClass(Fruit.class); 191 // map输出value类型 192 job.setMapOutputValueClass(NullWritable.class); 193 194 // reduce输出key类型 195 job.setOutputKeyClass(Text.class); 196 // reduce输出value类型 197 job.setOutputValueClass(NullWritable.class); 198 199 // 输入格式 200 job.setInputFormatClass(TextInputFormat.class); 201 // 输出格式 202 job.setOutputFormatClass(TextOutputFormat.class); 203 204 return job.waitForCompletion(true) ? 0 : 1; 205 } 206 207 public static void main(String[] args) throws Exception{ 208 int exitCode = ToolRunner.run(new SecondrySort(), args); 209 System.exit(exitCode); 210 } 211 }
测试数据:
20180906 Apple 200
20180904 Apple 200
20180905 Banana 100
20180906 Orange 300
20180906 Banana 400
20180904 Orange 100
20180905 Apple 400
20180904 Banana 300
20180905 Orange 500
运行结果:
20180906 Banana 400
20180906 Orange 300
20180906 Apple 200
20180905 Orange 500
20180905 Apple 400
20180905 Banana 100
20180904 Banana 300
20180904 Apple 200
20180904 Orange 100
总结:
1、在使用实现WritableComparable接口的方式实现自定义比较器时,必须有一个无参的构造函数。否则会报Unable to initialize any output collector的错误。
2、readFields和write方法中处理字段的顺序必须一致,否则会报MapReduce Error: java.io.EOFException at java.io.DataInputStream.readFully(DataInputStream.java:197)的错误。
了解更多大数据的知识请关注我的微信公众号:summer_bigdata
欢迎可以扫码关注本人的公众号:

以上是关于一起学Hadoop——二次排序算法的实现的主要内容,如果未能解决你的问题,请参考以下文章
一起学Hadoop——使用自定义Partition实现hadoop部分排序