大数据学习之提交job流程,排序11
Posted hidamowang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习之提交job流程,排序11相关的知识,希望对你有一定的参考价值。
1实现接口->WritableCompareable
排序操作在hadoop中属于默认的行为。默认按照字典殊勋排序。
2 排序的分类:
1)部分排序
2)全排序
3)辅助排序
4)二次排序
3 案例: 在流量汇总输出文件里的数据 进行分区,每个分区中的数据进行排序
数据预览,这里只是进行了流量的汇总,没有进行分区和排序
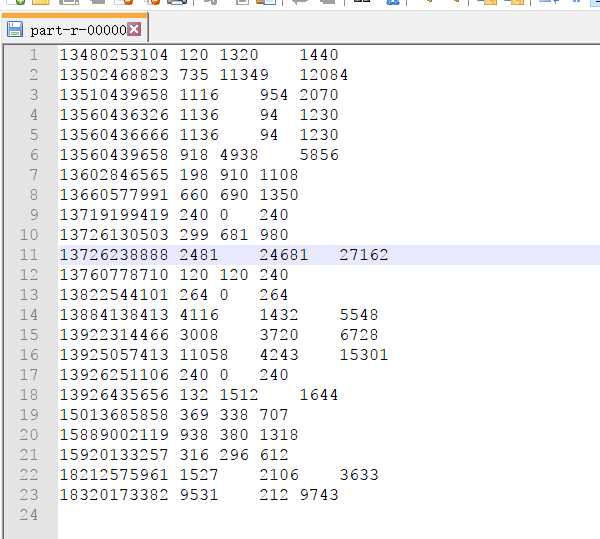
1:编写flowbean
实现WritableCompareable完成序列化并且完成排序
package it.dawn.YARNPra.基本用法.排序;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* @author Dawn
* @date 2019年5月7日09:04:04
* @version 1.0
* 直接继承 WritableComparable,
*/
public class FlowBean implements WritableComparable<FlowBean>{
private long upFlow;
private long dfFlow;
private long flowSum;
//无参构造
public FlowBean() {}
//有参构造
public FlowBean(long upFlow,long dfFlow) {
this.upFlow=upFlow;
this.dfFlow=dfFlow;
this.flowSum=upFlow+dfFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDfFlow() {
return dfFlow;
}
public void setDfFlow(long dfFlow) {
this.dfFlow = dfFlow;
}
public long getFlowSum() {
return flowSum;
}
public void setFlowSum(long flowSum) {
this.flowSum = flowSum;
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeLong(upFlow);
out.writeLong(dfFlow);
out.writeLong(flowSum);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
upFlow=in.readLong();
dfFlow=in.readLong();
flowSum=in.readLong();
}
@Override
public String toString() {
return upFlow+"\\t"+dfFlow+"\\t"+flowSum;
}
//排序
@Override
public int compareTo(FlowBean o) {
//倒序
return this.flowSum>o.getFlowSum()? -1 : 1;
}
}
2:编写Mapper类
package it.dawn.YARNPra.基本用法.排序;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author Dawn
* @date 2019年5月7日09:24:06
* @version 1.0
*
* 输入?
* 13480253104 120 1320 1440
* 输出?
* <key2 , v2>
* <流量上行+\\t+流量下行,手机号码>
*/
public class FlowSortMapper extends Mapper<LongWritable, Text, FlowBean, Text>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//1:读数据
String line=value.toString();
//2:切割
String[] fields=line.split("\\t");
//3:取出指定字段
long upFlow=Long.parseLong(fields[1]);
long dfFlow=Long.parseLong(fields[2]);
//4:输出到reduce阶段
context.write(new FlowBean(upFlow, dfFlow), new Text(fields[0]));
}
}
3:编写Reducer类
package it.dawn.YARNPra.基本用法.排序;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowSortReducer extends Reducer<FlowBean, Text, Text, FlowBean>{
@Override
protected void reduce(FlowBean k3, Iterable<Text> v3, Context context)
throws IOException, InterruptedException {
//直接输出
context.write(v3.iterator().next(), k3);
}
}
4:编写Partitioner类
package it.dawn.YARNPra.基本用法.排序;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class FlowSortPartitioner extends Partitioner<FlowBean, Text>{
@Override
public int getPartition(FlowBean key, Text value, int numPartitions) {
//1: 获取手机前3个数字
String phoneThree=value.toString().substring(0, 3);
//2:定义分区号
int partitioner=4;
if("135".equals(phoneThree)) {
return 0;
}else if("137".equals(phoneThree)) {
return 1;
}else if("138".equals(phoneThree)) {
return 2;
}else if("139".equals(phoneThree)) {
return 3;
}
return partitioner;
}
}
5:编写driver类
package it.dawn.YARNPra.基本用法.排序;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author Dawn
* @date 2019年5月7日09:22:12
* @version 1.0
* 需求?
* 将数据进行分区,并在每个分区中进行排序
*/
public class FlowSortDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1:添加配置
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
//2:设置主类
job.setJarByClass(FlowSortDriver.class);
//3:设置Mapper和Reduce类
job.setMapperClass(FlowSortMapper.class);
job.setReducerClass(FlowSortReducer.class);
//4:设置Map输出类
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
//5:设置Reduce输出类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//添加自定义分区
job.setPartitionerClass(FlowSortPartitioner.class);
job.setNumReduceTasks(5);
//6:设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("f:/temp/流量统计结果/out1/part-r-00000"));
FileOutputFormat.setOutputPath(job, new Path("f:/temp/流量统计结果/out2"));
//7提交任务
boolean rs=job.waitForCompletion(true);
System.out.println(rs ? "success" : "fail");
}
}
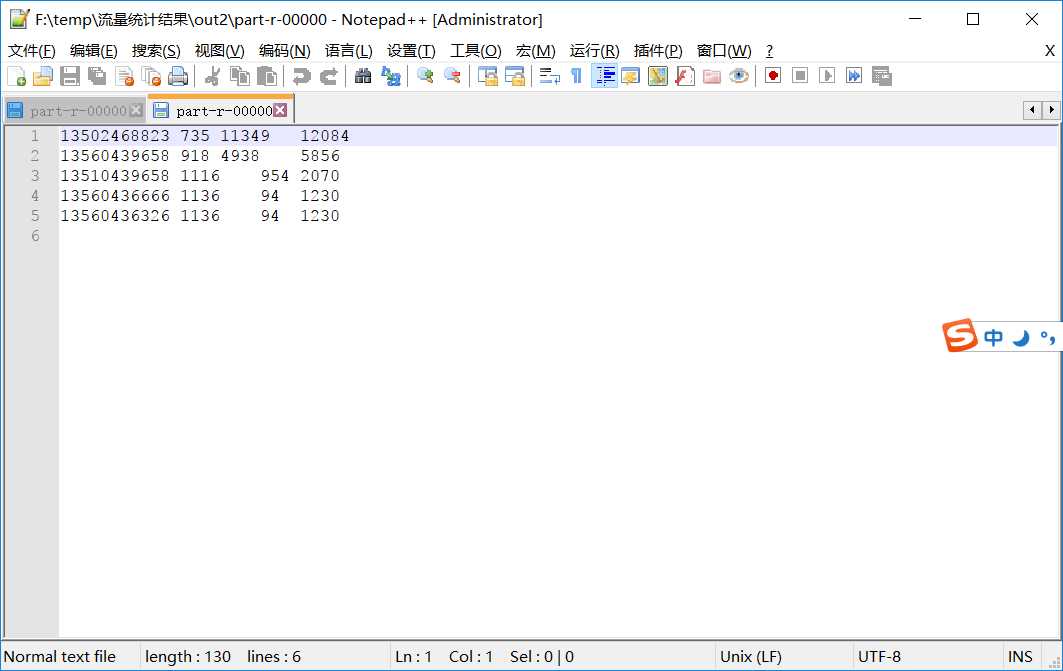
查看最终的输出结果:
以上是关于大数据学习之提交job流程,排序11的主要内容,如果未能解决你的问题,请参考以下文章