Oracle高级查询之over(partition by...)
Posted lclc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle高级查询之over(partition by...)相关的知识,希望对你有一定的参考价值。
为了方便学习和测试,所有的例子都是在Oracle自带用户Scott下建立的。
- create table EMP
- (
- empno NUMBER(4) not null,
- ename VARCHAR2(10),
- job VARCHAR2(9),
- mgr NUMBER(4),
- hiredate DATE,
- sal NUMBER(7,2),
- comm NUMBER(7,2),
- deptno NUMBER(2)
- )
- alter table EMP
- add constraint PK_EMP primary key (EMPNO);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7369, \'SMITH\', \'CLERK\', 7902, to_date(\'17-12-1980\', \'dd-mm-yyyy\'), 800, null, 20);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7499, \'ALLEN\', \'SALESMAN\', 7698, to_date(\'20-02-1981\', \'dd-mm-yyyy\'), 1600, 300, 30);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7521, \'WARD\', \'SALESMAN\', 7698, to_date(\'22-02-1981\', \'dd-mm-yyyy\'), 1250, 500, 30);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7566, \'JONES\', \'MANAGER\', 7839, to_date(\'02-04-1981\', \'dd-mm-yyyy\'), 2975, null, 20);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7654, \'MARTIN\', \'SALESMAN\', 7698, to_date(\'28-09-1981\', \'dd-mm-yyyy\'), 1250, 1400, 30);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7698, \'BLAKE\', \'MANAGER\', 7839, to_date(\'01-05-1981\', \'dd-mm-yyyy\'), 2850, null, 30);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7782, \'CLARK\', \'MANAGER\', 7839, to_date(\'09-06-1981\', \'dd-mm-yyyy\'), 2450, null, 10);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7788, \'SCOTT\', \'ANALYST\', 7566, to_date(\'19-04-1987\', \'dd-mm-yyyy\'), 3000, null, 20);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7839, \'KING\', \'PRESIDENT\', null, to_date(\'17-11-1981\', \'dd-mm-yyyy\'), 5000, null, 10);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7844, \'TURNER\', \'SALESMAN\', 7698, to_date(\'08-09-1981\', \'dd-mm-yyyy\'), 1500, 0, 30);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7876, \'ADAMS\', \'CLERK\', 7788, to_date(\'23-05-1987\', \'dd-mm-yyyy\'), 1100, null, 20);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7900, \'JAMES\', \'CLERK\', 7698, to_date(\'03-12-1981\', \'dd-mm-yyyy\'), 950, null, 30);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7902, \'FORD\', \'ANALYST\', 7566, to_date(\'03-12-1981\', \'dd-mm-yyyy\'), 3000, null, 20);
- insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
- values (7934, \'MILLER\', \'CLERK\', 7782, to_date(\'23-01-1982\', \'dd-mm-yyyy\'), 1300, null, 10);
注:标题中的红色order by是说明在使用该方法的时候必须要带上order by
一、rank()/dense_rank() over(partition by ...order by ...)
现在客户有这样一个需求,查询每个部门工资最高的雇员的信息,相信有一定oracle应用知识的同学都能写出下面的SQL语句:
- select * from (select ename, job, hiredate, e.sal, e.deptno
- from emp e,
- (select deptno, max(sal) sal from emp group by deptno) t
- where e.deptno = t.deptno
- and e.sal = t.sal)
- order by deptno;
- select * from (select ename 姓名, job 职业, hiredate 入职日期, e.sal 工资, e.deptno 部门
- from emp e,
- (select deptno, max(sal) sal from emp group by deptno) t
- where e.deptno = t.deptno
- and e.sal = t.sal)
- order by 部门;
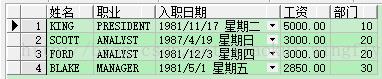
在满足客户需求的同时,大家应该习惯性的思考一下是否还有别的方法。这个是肯定的,就是使用本小节标题中rank() over(partition by...)或dense_rank() over(partition by...)语法,SQL分别如下:
- select empno, ename, job, hiredate, sal, deptno
- from (select empno, ename, job, hiredate, sal, deptno, rank() over(partition by deptno order by sal desc) r from emp)
- where r = 1;
- select empno, ename, job, hiredate, sal, deptno
- from (select empno, ename, job, hiredate, sal, deptno, dense_rank() over(partition by deptno order by sal desc) r from emp)
- where r = 1
为什么会得出跟上面的语句一样的结果呢?这里补充讲解一下rank()/dense_rank() over(partition by e.deptno order by e.sal desc)语法。
over: 在什么条件之上。
partition by e.deptno: 按部门编号划分(分区)。
order by e.sal desc: 按工资从高到低排序(使用rank()/dense_rank() 时,必须要带order by否则非法)
rank()/dense_rank(): 分级
整个语句的意思就是:在按部门划分的基础上,按工资从高到低对雇员进行分级,“级别”由从小到大的数字表示(最小值一定为1)。
那么rank()和dense_rank()有什么区别呢?
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
小作业:查询部门最低工资的雇员信息。
二、min()/max() over(partition by ...)
现在我们已经查询得到了部门最高/最低工资,客户需求又来了,查询雇员信息的同时算出雇员工资与部门最高/最低工资的差额。这个还是比较简单,在第一节的groupby语句的基础上进行修改如下:
-- 查询每位雇员信息的同时算出雇员工资与所属部门最高/最低员工工资的差额
- select ename 姓名, job 职业, hiredate 入职日期, e.deptno 部门, e.sal 工资, e.sal-me.min_sal 最低差额, me.max_sal-e.sal 最高差额
- from emp e, (select deptno, min(sal) min_sal, max(sal) max_sal from emp group by deptno) me
- where e.deptno = me.deptno order by e.deptno, e.sal;
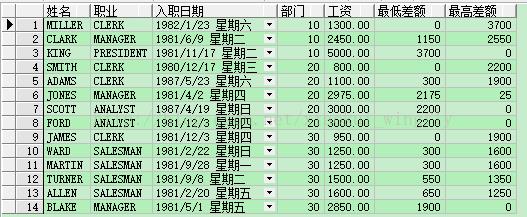
上面我们用到了min()和max(),前者求最小值,后者求最大值。如果这两个方法配合over(partition by ...)使用会是什么效果呢?大家看看下面的SQL语句:
- select ename 姓名, job 职业, hiredate 入职日期, deptno 部门,
- min(sal) over(partition by deptno) 部门最低工资,
- max(sal) over(partition by deptno) 部门最高工资
- from emp order by deptno, sal;
- select ename 姓名, job 职业, hiredate 入职日期, deptno 部门,
- nvl(sal - min(sal) over(partition by deptno), 0) 部门最低工资差额,
- nvl(max(sal) over(partition by deptno) - sal, 0) 部门最高工资差额
- from emp order by deptno, sal;
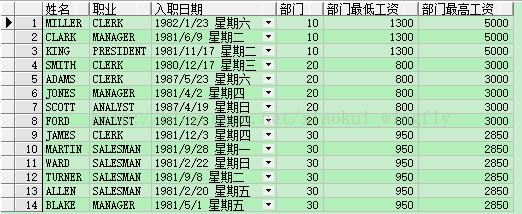

这两个语句的查询结果是一样的,大家可以看到min()和max()实际上求的还是最小值和最大值,只不过是在partition by分区基础上的。
小作业:如果在本例中加上order by,会得到什么结果呢?
三、lead()/lag() over(partition by ... order by ...)
中国人爱攀比,好面子,闻名世界。客户更是好这一口,在和最高/最低工资比较完之后还觉得不过瘾,这次就提出了一个比较变态的需求,计算个人工资与比自己高一位/低一位工资的差额。这个需求确实让我很是为难,在groupby语句中不知道应该怎么去实现。不过。。。。现在我们有了over(partition by ...),一切看起来是那么的简单。如下:
-- 计算个人工资与比自己高一位/低一位工资的差额
- select ename 姓名, job 职业, sal 工资, deptno 部门,
- lead(sal, 1, 0) over(partition by deptno order by sal) 比自己工资高的部门前一个,
- lag(sal, 1, 0) over(partition by deptno order by sal) 比自己工资低的部门后一个,
- nvl(lead(sal) over(partition by deptno order by sal) - sal, 0) 比自己工资高的部门前一个差额,
- nvl(sal - lag(sal) over(partition by deptno order by sal), 0) 比自己工资高的部门后一个差额
- from emp;
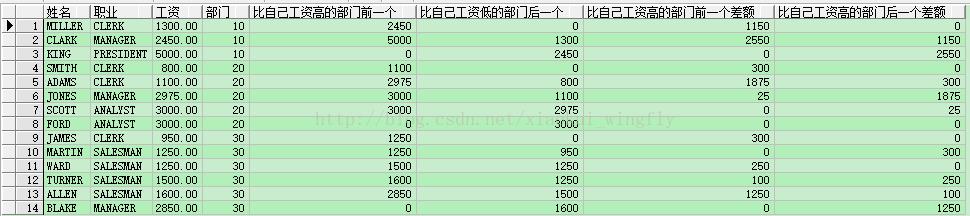
看了上面的语句后,大家是否也会觉得虚惊一场呢(惊出一身冷汗后突然鸡冻起来,这样容易感冒)?我们还是来讲解一下上面用到的两个新方法吧。
lead(列名,n,m): 当前记录后面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录后面第一行的记录<列名>的值,没有则默认值为null。
lag(列名,n,m): 当前记录前面第n行记录的<列名>的值,没有则默认值为m;如果不带参数n,m,则查找当前记录前面第一行的记录<列名>的值,没有则默认值为null。
下面再列举一些常用的方法在该语法中的应用(注:带order by子句的方法说明在使用该方法的时候必须要带order by):
- select ename 姓名, job 职业, sal 工资, deptno 部门,
- first_value(sal) over(partition by deptno) first_sal,
- last_value(sal) over(partition by deptno) last_sal,
- sum(sal) over(partition by deptno) 部门总工资,
- avg(sal) over(partition by deptno) 部门平均工资,
- count(1) over(partition by deptno) 部门总数,
- row_number() over(partition by deptno order by sal) 序号
- from emp;

重要提示:大家在读完本片文章之后可能会有点误解,就是OVER (PARTITION BY ..)比GROUP BY更好,实际并非如此,前者不可能替代后者,而且在执行效率上前者也没有后者高,只是前者提供了更多的功能而已,所以希望大家在使用中要根据需求情况进行选择。
原文摘自傅老师课堂 Mr傅:http://blog.csdn.NET/fu0208/article/details/7179001
http://blog.csdn.net/huxu981598436/article/details/38129177
row_number()浅析:
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的).
与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪列rownum然后再进行排序,而此函数在包含排序从句后是先排序再计算行号码.
row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序)。
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where group by order by 的执行。
partition by 是数据的分区取数,用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,它和聚合函数不同的地方在于它能够返回一个分组中的多条记录,而聚合函数一般只有一个反映统计值的记录。
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内).
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的 .
lag(arg1,arg2,arg3):
arg1是从其他行返回的表达式
arg2是希望检索的当前行分区的偏移量。是一个正的偏移量,时一个往回检索以前的行的数目。
arg3是在arg2表示的数目超出了分组的范围时返回的值。
举例:
SQL> DESC T1;
Name Null? Type
----------------------------------------- -------- ----------------------------
ID NUMBER
NAME VARCHAR2(10)
DATE1 DATE
SQL> SELECT * FROM T1;
ID NAME DATE1
---------- ------------------------------ ------------------
101 aaa 09-SEP-13
101 bbb 10-SEP-13
101 ccc 11-SEP-13
102 ddd 08-SEP-13
102 eee 11-SEP-13
SQL> SELECT ID,NAME,DATE1,ROW_NUMBER() OVER(partition by ID order by DATE1 desc) as RN FROM T1;
ID NAME DATE1 RN
---------- ------------------------------ ------------------ ----------
101 ccc 11-SEP-13 1
101 bbb 10-SEP-13 2
101 aaa 09-SEP-13 3
102 eee 11-SEP-13 1
102 ddd 08-SEP-13 2
把上面语句作为一个子表语句,嵌入到另一条语句中:
SQL> SELECT ID,NAME,DATE1 FROM (SELECT ID,NAME,DATE1,ROW_NUMBER()
OVER(partition by ID order by DATE1 desc) as RN FROM T1)T WHERE T.RN=1;
ID NAME DATE1
---------- ------------------------------ ------------------
101 ccc 11-SEP-13
102 eee 11-SEP-13
再看几个SQL语句:
语句一:
select row_number() over(order by sale/cnt desc) as sort, sale/cnt
from (
select -60 as sale,3 as cnt from dual union
select 24 as sale,6 as cnt from dual union
select 50 as sale,5 as cnt from dual union
select -20 as sale,2 as cnt from dual union
select 40 as sale,8 as cnt from dual);
执行结果:
SORT SALE/CNT
---------- ----------
1 10
2 5
3 4
4 -10
5 -20
语句二:查询员工的工资,按部门排序
select ename,sal,row_number() over (partition by deptno order by sal desc) as sal_order from scott.emp;
执行结果:
ENAME SAL SAL_ORDER
-------------------- ---------- ----------
KING 5000 1
CLARK 2450 2
MILLER 1300 3
SCOTT 3000 1
FORD 3000 2
JONES 2975 3
ADAMS 1100 4
SMITH 800 5
BLAKE 2850 1
ALLEN 1600 2
TURNER 1500 3
WARD 1250 4
MARTIN 1250 5
JAMES 950 6
已选择14行。
语句三:查询每个部门的最高工资
select deptno,ename,sal from
(select deptno,ename,sal,row_number() over (partition by deptno order by sal desc) as sal_order
from scott.emp) where sal_order <2;
执行结果:
DEPTNO ENAME SAL
---------- -------------------- ----------
10 KING 5000
20 SCOTT 3000
30 BLAKE 2850
已选择3行。
语句四:
select deptno,sal,rank() over (partition by deptno order by sal) as rank_order from scott.emp order by deptno;
执行结果:
DEPTNO SAL RANK_ORDER
---------- ---------- ----------
10 1300 1
10 2450 2
10 5000 3
20 800 1
20 1100 2
20 2975 3
20 3000 4
20 3000 4
30 950 1
30 1250 2
30 1250 2
30 1500 4
30 1600 5
30 2850 6
已选择14行。
语句五:
select deptno,sal,dense_rank() over(partition by deptno order by sal) as dense_rank_order from scott.emp order by deptn;
执行结果:
DEPTNO SAL DENSE_RANK_ORDER
---------- ---------- ----------------
10 1300 1
10 2450 2
10 5000 3
20 800 1
20 1100 2
20 2975 3
20 3000 4
20 3000 4
30 950 1
30 1250 2
30 1250 2
30 1500 3
30 1600 4
30 2850 5
已选择14行。
语句六:
select deptno,ename,sal,lag(ename,1,null) over(partition by deptno order by ename) as lag_ from scott.emp order by deptno;
执行结果:
DEPTNO ENAME SAL LAG_
---------- -------------------- ---------- --------------------
10 CLARK 2450
10 KING 5000 CLARK
10 MILLER 1300 KING
20 ADAMS 1100
20 FORD 3000 ADAMS
20 JONES 2975 FORD
20 SCOTT 3000 JONES
20 SMITH 800 SCOTT
30 ALLEN 1600
30 BLAKE 2850 ALLEN
30 JAMES 950 BLAKE
30 MARTIN 1250 JAMES
30 TURNER 1500 MARTIN
30 WARD 1250 TURNER
已选择14行。
很多年以后,还有很多程序员不知道SQL Server2005有了更方便的分页方法,这就是ROW_NUMBER()函数。我们知道SQL2000时代的分页方式是TOP加NOT IN截取中间数据,效率也是很不错的,但这两种效率到底如何呢,我们这次以一万、十万和百万数据量的数据做演示,比较这两种分页方式的效率。另外为何使用 TOP+NOT IN来和ROW_NUMBER()比较,是因为和游标方式及ISNULL方式分页来说,TOP+NOT IN方式效率更高。前人已有证明,可参考这篇文章:http://www.cnblogs.com/morningwang/archive/2009/01/02/1367277.html ,或者自行搜索更权威文章。
准备工作
准备工具:电脑(当然了o(∩_∩)o )和程序员一名。
同一测试环境,电脑配置如下,数据如有不实,请找周鸿祎~

建立数据表,插入相应数据。表结构如下,Id为自增长主键:
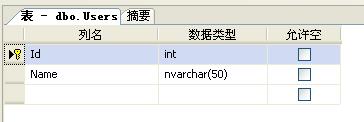
插入100万条测试数据:
user table3godeclare @index intset @index=0while @index<1000000 begin insert into Users(Name) values(\'walkingp\') set @index=@index+1 end |
接下来先扫盲一下ROW_NUMBER()函数。
ROW_NUMBER()函数
ROW_NUMBER()函数是根据参数传递过来的order by子句的值,返回一个不断递增的整数值,也就是它会从1一直不断自增1,直到条件不再满足。例如表Users(Id,Name),使用以下sql语句进行查询:
select id,name,row_number() over(order by Id desc) as rowNum from users where id<10select id,name,row_number() over(order by Id) as rowNum from users where id<10 |
两条语句order by排序相反,执行结果如下:
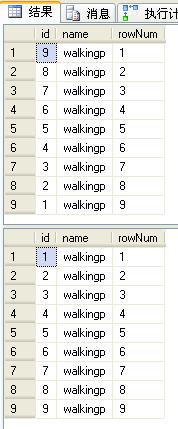
孰优孰劣
以下两种情况,同样取500000到500100中间的数据。
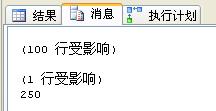
1、使用ROW_NUMBER()函数。
SQL语句如下:
declare @time datetimedeclare @ms intset @time= getdate()select Id,Name from (select row_number() over(order by Id) as rowNum,* from users) ast where rowNum between 500000 and 500100set @ms=datediff(ms,@time,getdate())print @ms--毫秒数 |
测试了几次,平均在250毫秒:
2、使用TOP加NOT IN方法。
SQL语句如下: