大数据--spark
Posted dsjxb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据--spark相关的知识,希望对你有一定的参考价值。
在刚接触大数据的时候,我们主要接受的是关于hadoop的相关知识,虽然比较浅显,但是基本介绍了hadoop每一个过程或者组建的运行的原理以及架构,包括优缺点以及他的使用场景,例如hdfs、mapreduce、zookeeper以及hive、hbase等,但是,在这之后,为了满足大数据的增长需求以及更好的对数据进行处理得到数据中的有用信息,很多的时间场景下,Hadoop的计算速度以及模式已经不能完全的满足计算分析的需求,所以,在hadoop的基础上,我们增加了另外一个新的技术===spark
什么是spark呢?
在spark的官方网站上对于spark是这样定义的=Apache Spark是一种快速通用的集群计算系统。它提供Java,Scala,Python和R中的高级API,以及使用最先进的DAG调度,查询优化器和物理执行引擎,实现了在数据处理方面的一个高速和高性能,而且spark中封装了大量的库,例如 SQL和DataFrames,MLlib机器学习,GraphX和spark Streaming 可以在应用程序中直接使用在这个库,而且,为了实现spark的通用性,目前spark支持local、standalone、mesos、yarn四种运行模式
Spark是主要有scala语言进行编写,当然也包括java甚至是python,伯克利大学针对spark构建了一个数据分析栈
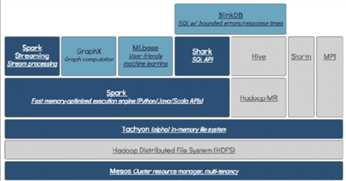
与大数据相关的需求包括:离线计算、实时计算、机器学习、交互式查询,若meiyouspark需要搭建mr、storm、mahout、hive四种不同的集群进行相应的处理,但是,spark中的不同集群封装了不同的处理集群进行出去,然后在运行的时候只需要搭建一套spark就可以完成几乎所有的操作
Spark的体系架构:
结合上面的讲解,spark的体系架构主要包括数据存储、API、管理框架三个方面
数据存储:spark用hdfs文件系统存储数据,与hadoop相同,所以它可以存储兼容于所有的Hadoop的数据源
API:spark的编程语言是基于JVM的,而除了基于JVM的scala和java两种之外,spark还只是python和R语言,一共四种API
资源管理框架:

Spark相比hadoop来说发展迅速,在短短的几年间就完成了相关的设计,在到09-16年年间进行了版本的更新和设计,完善了spark的功能,用户能够更好地使用和体验
Spark的设计就是为了效率快,执行时间短,那spark为什么比mapreduce快呢?Mapreduce是基于磁盘的迭代计算(每次计算的逻辑一样但是计算的数据不一样),每一次的计算会将结果放置到hdfs中,当下一次进行计算的时候在去hdfs中读取上一次计算的结果进行计算
而spark可已经数据持久化到 内存中,而内存的读取速度比磁盘的要快很多倍,在一个原因就是因为spark执行的是并行的计算框架,减少了数据的落地
Spark的特性
1、高效率:基于内存的迭代运算,效率高,而且知识DAG的分布式的并行计算框架,减少了迭代过程的数据落地
2、容错性高:spark中的弹性数据集(RDD)的抽象,如果数据集的一部分丢失,需要进行重建,而且数据集的操作类型更加丰富
为提高spark的容错性,引进了分布式弹性数据集(RDD)的抽象,他是分布在节点上的一组只读数据集合,可以通过不同的算子进行操作,而这些算子主要可以分为三类:transformation类算子:代表的map、flatmap等,是一种延迟操作,提前对数据进行操作
Action类算子:触发transformation类的执行,提交job,并将数据输出spark
持久化类算子:cache、persist算子,将数据持久化到内存,提升了计算的效率
对于这RDD操作的算子后期还会详细讲解
除了引入RDD这一特点之外,还有许多其他的结构来支持spark的高性能
·Spark Core封装了一部分的计算框架和运行框架以及RDD
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统·Spark SQL
SparkSQL的前身是Shark,Shark是伯克利实验室Spark生态环境的组件之一,它修改了内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升
这就是spark的初期介绍,后面我们还会就spark的各个组件进行相应的详细介绍
以上是关于大数据--spark的主要内容,如果未能解决你的问题,请参考以下文章