工程中的CTR丨是啥意思?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工程中的CTR丨是啥意思?相关的知识,希望对你有一定的参考价值。
CTR是“Cycle Time Reduction”缩写,是通过省略不必要的工作步骤来缩短业务流程或产品设计的循环时间,从而使公司能对客户需求做出快速反应持续实施的系统方法。临界温度热敏电阻CTR(Crit1Cal Temperature Resistor)具有负电阻突变特性,在某一温度下,电阻值随温度的增加激剧减小,具有很大的负温度系数.构成材料是钒、钡、锶、磷等元素氧化物的混合烧结体,是半玻璃状的半导体,也称CTR为玻璃态热敏电阻.骤变温度随添加锗、钨、钼等的氧化物而变.这是由于不同杂质的掺入,使氧化钒的晶格间隔不同造成的.若在适当的还原气氛中五氧化二钒变成二氧化钒,则电阻急变温度变大;若进一步还原为三氧化二钒,则急变消失.产生电阻急变的温度对应于半玻璃半导体物性急变的位置,因此产生半导体-金属相移.CTR能够作为控温报警等应用. 参考技术A 英文全名是click-through rate,翻译成中文是点击率的意思,一般指的是点击率预估任务,也就是给定一个内容item id,预测用户user id点击这个item的概率。 参考技术B 苏子夜坐,有鼠方啮。拊床而止之,既止复作。使童子烛之,有橐中空,嘐嘐聱聱,声在橐中。曰:“嘻!此鼠之见闭而不得去者也。”发而视之,寂无所有,举烛而索,中有死鼠。童子惊曰:“是方啮也,而遽死耶?向为何声,岂其鬼耶?”覆而出之,堕地乃走,虽有敏者,莫措其手。
苏子叹曰:“异哉!是鼠之黠也。闭于橐中,橐坚而不可穴也。故不啮而啮,以声致人;不死而死,以形求脱也。吾闻有生,莫智于人。拢龙伐蛟,登龟狩麟,役万物而君之,卒见使于一鼠;堕此虫之计中,惊脱兔于处女,乌在其为智也。”
坐而假寐,私念其故。若有告余者曰:“汝惟多学而识之,望道而未见也。不一于汝,而二于物,故一鼠之啮而为之变也。人能碎千金之璧,不能无失声于破釜;能搏猛虎,不能无变色于蜂虿:此不一之患也。言出于汝,而忘之耶?”余俛而笑,仰而觉。使童子执笔,记余之作。
这是一篇别开生面的游记文,它不注重山川形胜的描写,而注重辩难与议论,其所阐发的道理又是通过游程的记录来说明,这需要处理好记游、辩难和议论三者关系。作者巧妙地把记游作为辩难的根据,而议论则是对辩难的生发和引申,不仅讲清了知与实践的关系、知与见识的关系、知与言的关系,而且把石钟山的壮丽风光描绘得生动传神。这种于形象描绘中熔入理性分析的高超技巧,是他人难以企及的。
石钟山在今江西省湖口县鄱阳湖东岸。 参考技术C
这篇文章是阿里巴巴的gaikun团队于2018年发表于KDD的文章[1],目前已经在各大公司的点击率预估(CTR)场景都得到广泛的应用。这篇文章就从模型和代码实现方面简单介绍一下这篇文章提出的DIN模型。
1.背景
随着深度学习的发展,许多研究者将DNN网络应用到CTR的任务上来。大部分目前使用的深度学习模型都可以认为是Embedding&MLP结构,即大规模的、稀疏的输入数据首先被压缩成低维的embedding,变成固定长度的输入向量,被输入到全连接网络中去。这些模型大大减少了特征工程的工作量,因此广为流行。
但这些方法仍然有缺点,最大的缺点就是固定维数的向量不能充分地表达用户兴趣的Diversity(一般是用用户过去的购买行为或者点击行为来表示用户的兴趣),为了增加模型的学习能力,要扩大embedding的维度,而在样本有限的情况下,通常会造成过拟合的问题。
除此之外,给定一个商品,决定用户是否点击进去查看的往往是用户的部分兴趣而非所有兴趣,通常来说是最近的一些行为相关性更大一些。所以这篇文章提出的DIN模型对于不同的商品,将对应适应性的用户兴趣特征来输入,以解决固定特征维度不能充分表达用户行为的问题。其主要的中心思想,就是结合attention机制对用户的历史行为进行了加权处理,对于不同的商品,权重不一致。[2]
2.模型
2.1 MLP
首先看一下传统的DNN在点击率预估上的一般方法:
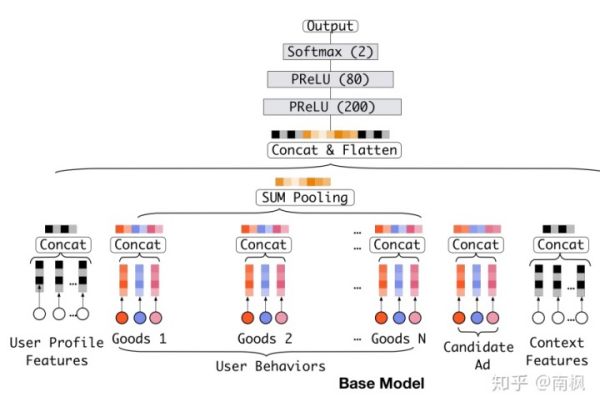
传统DNN模型一般是按照Embedding Layer&Pooling Layer->Concat->MLP的框架来构建模型的,在Embedding Layer -> Pooling Layer得到用户兴趣表示的时候,没有考虑用户与推荐商品之间的关系,即不同的推荐商品之间的权重是一致的。这正是上文DIN要解决的问题。
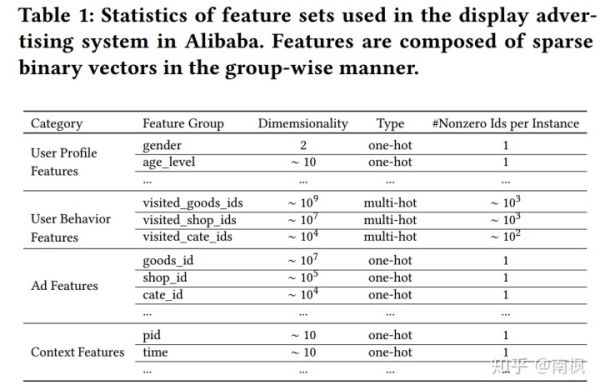
同时,由上图可以看出,一般CTR问题的输入包含四种类型的特征:
2.2 DIN
为了解决上述提出的问题,DIN利用attention机制,在得到用户兴趣表示时赋予不同的历史行为不同的权重,即通过Embedding Layer -> Pooling Layer+attention实现局部激活。从而在训练过程中根据当前的候选商品,来反向的激活用户历史的兴趣爱好,赋予不同历史行为不同的权重。也就是说对于不同的候选商品输入,得到的兴趣特征是不同的。网络结构如下图:
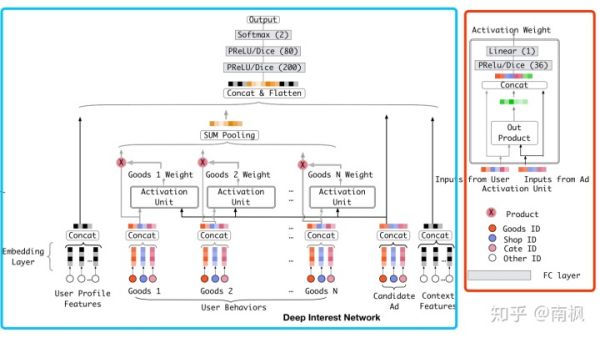
上图的左边就是DIN的模型架构图,输入还是同样的四种类型特征,而在User Profile Feature和Context Feature这两种类型的处理和上述的MLP方法保持不变。对于User Behaviors和Candidate Ad这两种特征,文章提出的是一种类似NLP中常用的Attention结构(Activation Unit)。如上述右图所示:
每个兴趣商品(Goods)要和候选商品(Candidate Ad)要进行Out Product等操作,并将外积和自身的embedding表示进行concat,输入到FC得到一个权值,对应的就是当前兴趣商品的权值。在算出所有商品的权值之后,再对所有的商品的embedding进行加权求和,结果就是用户对于当前候选商品的兴趣表示。对应的公式如下:
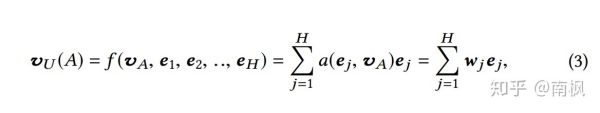
其中:
是候选商品的Embedding表示
是用户的兴趣商品的Embedding表示
函数a(*, *)表示上述的Activation Unit, 得到的权重是
简单看一下这里Activation Unit对应的代码,应该是官方,来源于https://github.com/zhougr1993/DeepInterestNetwork/blob/master/din/model.py[3]:
def attention(queries, keys, keys_length):''' queries: [B, H] keys: [B, T, H] keys_length: [B] '''
queries_hidden_units = queries.get_shape().as_list()[-1]
queries = tf.tile(queries, [1, tf.shape(keys)[1]])
queries = tf.reshape(queries, [-1, tf.shape(keys)[1], queries_hidden_units])
din_all = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att', reuse=tf.AUTO_REUSE)
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.reshape(d_layer_3_all, [-1, 1, tf.shape(keys)[1]])
outputs = d_layer_3_all
# Mask
key_masks = tf.sequence_mask(keys_length, tf.shape(keys)[1]) # [B, T]
key_masks = tf.expand_dims(key_masks, 1) # [B, 1, T]
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(key_masks, outputs, paddings) # [B, 1, T]
# Scale
outputs = outputs / (keys.get_shape().as_list()[-1] ** 0.5)
# Activation
outputs = tf.nn.softmax(outputs) # [B, 1, T]
# Weighted sum
outputs = tf.matmul(outputs, keys) # [B, 1, H]
return outputs
输入:
queries是候选商品的embedding表示;
keys是用户浏览过的兴趣商品embeddings表示;
keys_length 表示兴趣商品的数量,因为输入的keys对应的shape相同,所以根据不同的用户,需要额外输入兴趣商品的数量。
过程:
先对queries reshape成(B, 1, H)
拼接[queries, keys, queries-keys, queries*keys],将候选商品和兴趣商品信息融合得到din_all
对于din_all进行多次MLP计算得到权值,然后reshape为(B, 1, T)
再根据输入的keys_length mask掉超过兴趣商品数量的维度
最后用softmax归一化权值,并且对兴趣商品的embeddings进行加权求和并返回结果
这个地方用的attention方法和我之前介绍过的 self attention 南枫:【NLP】换一种方式进行机器翻译-Transformer(模型和代码解析) [4]有很多相似之处,这里简单看一下不同点:
self attention中queries和keys的shape一般是相同的,且都是序列形式。而这里的queries的输入是单纯的向量。
信息融合的方式: self attention使用的是queries和keys进行矩阵乘法来得到权值,而DIN使用的是拼接[queries, keys, queries-keys, queries*keys],再进行MLP。这里加入更多的side information,符合推荐系统常用的交叉特征。
推荐系统工程师必看!Embedding技术在深度学习CTR模型中的应用
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
在专栏之前的文章中,我们总结了深度学习 CTR 模型的发展过程和各模型的特点。这篇文章中,我希望单独将 Embedding 技术抽取出来进行讲解。因为作为深度学习 CTR 模型中基础性的,也是不可或缺的“基本操作”,Embedding 技术发挥着至关重要的作用。具体来讲,Embedding 技术在深度学习 CTR 模型中主要应用在下面三个方向:
在深度学习网络中作为 Embedding 层,完成从高维稀疏特征向量到低维稠密特征向量的转换;
作为预训练的 Embedding 特征向量,与其他特征向量连接后一同输入深度学习网络进行训练;
通过计算用户和物品的 Embedding 相似度,Embedding 可以直接作为推荐系统或计算广告系统的召回层或者召回方法之一。
下面逐一介绍 Embedding 与深度学习 CTR 模型结合的具体方法。
由于高维稀疏特征向量天然不适合多层复杂神经网络的训练,因此如果使用深度学习模型处理高维稀疏特征向量,几乎都会在输入层到全连接层之间加入 Embedding 层完成高维稀疏特征向量到低维稠密特征向量的转换。典型的例子是微软的 Deep Crossing 模型和 Google 的 Wide&Deep 模型的深度部分(如图 1)。
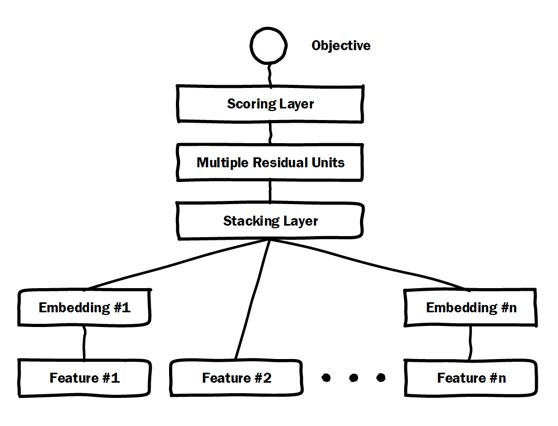
a 微软 Deep Crossing 模型
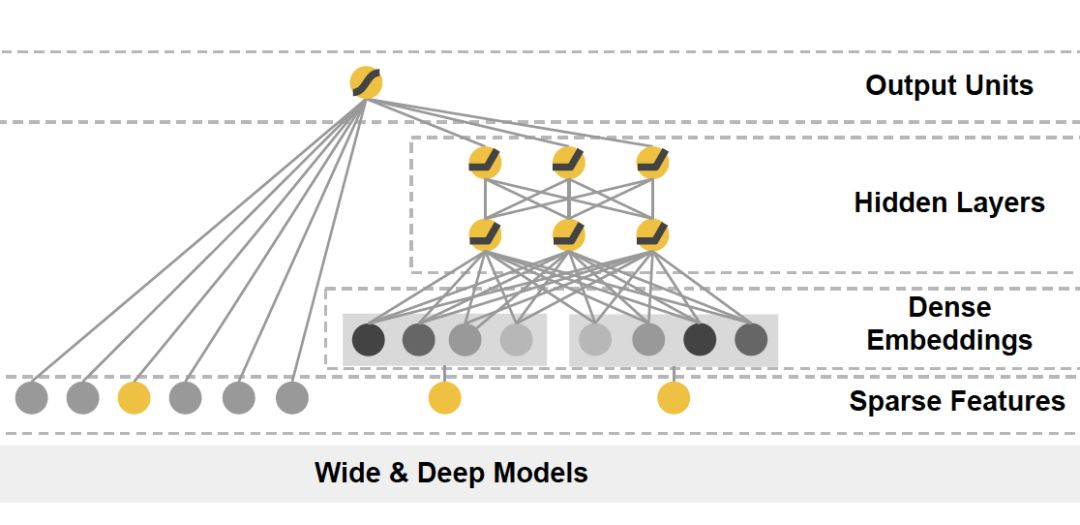 b Google W&D 中的 Deep 部分
b Google W&D 中的 Deep 部分
图 1 Deep Crossing 和 Wide&Deep 模型结构
读者可以清晰地看到 Deep Crossing 模型中的 Embedding 层将每一个 Feature 转换成稠密向量,Wide&Deep 模型中 Deep 部分的 Dense Embeddings 层同样将稀疏特征向量进行转换。广义来说,Embedding 层的结构可以比较复杂,只要完成高维向量的降维就可以了,但一般为了节省训练时间,深度神经网络中的 Embedding 层是一个高维向量向低维向量的直接映射(如图 2)。
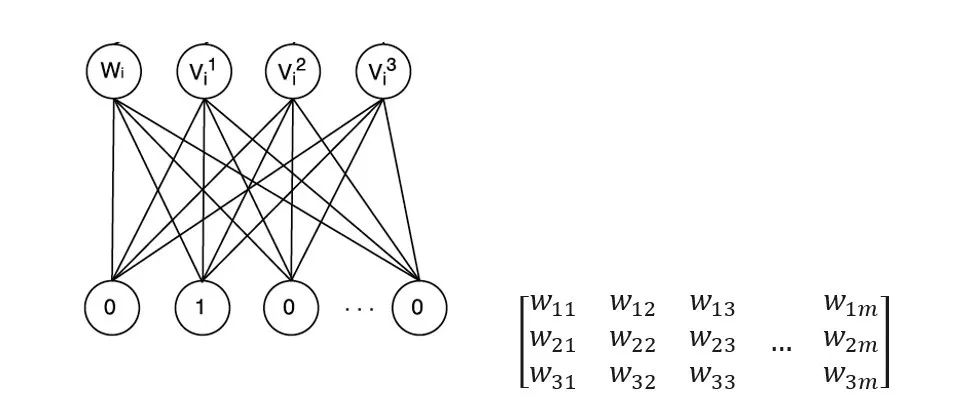
图 2 Embedding 层的图示和矩阵表达
用矩阵的形式表达 Embedding 层,本质上是求解一个 m(输入高维稀疏向量的维度) x n(输出稠密向量的维度)维的权重矩阵的过程。如果输入向量是 one-hot 特征向量的话,权重矩阵中的列向量即为相应维度 one-hot 特征的 embedding 向量。
将 Embedding 层与整个深度学习网络整合后一同进行训练是理论上最优的选择,因为上层梯度可以直接反向传播到输入层,模型整体是自洽和统一的。但这样做的缺点同样显而易见的,由于 Embedding 层输入向量的维度甚大,Embedding 层的加入会拖慢整个神经网络的收敛速度。
这里可以做一个简单的计算。假设输入层维度是 100,000,embedding 输出维度是 32,上层再加 5 层 32 维的全连接层,最后输出层维度是 10,那么输出层到 embedding 层的参数数量是 32*100,000= 3,200,000,其余所有层的参数总数是 (32*32)*4+32*10=4416。那么 embedding 层的权重总数占比是 3,200,000 / (3,200,000 + 4416) = 99.86%。
也就是说 embedding 层的权重占据了整个网络权重的绝大部分。那么训练过程可想而知,大部分的训练时间和计算开销都被 Embedding 层所占据。正因为这个原因,Embedding 层往往采用预训练的方式完成。
通过上面对 Embedding 层的介绍,读者们已经知道 Embedding 层的训练开销是巨大的。为了解决这个问题,Embedding 的训练往往独立于深度学习网络进行。在得到稀疏特征的稠密表达之后,再与其他特征一起输入神经网络进行训练。典型的采用 Embedding 预训练方法的模型是 FNN(如图 3)。
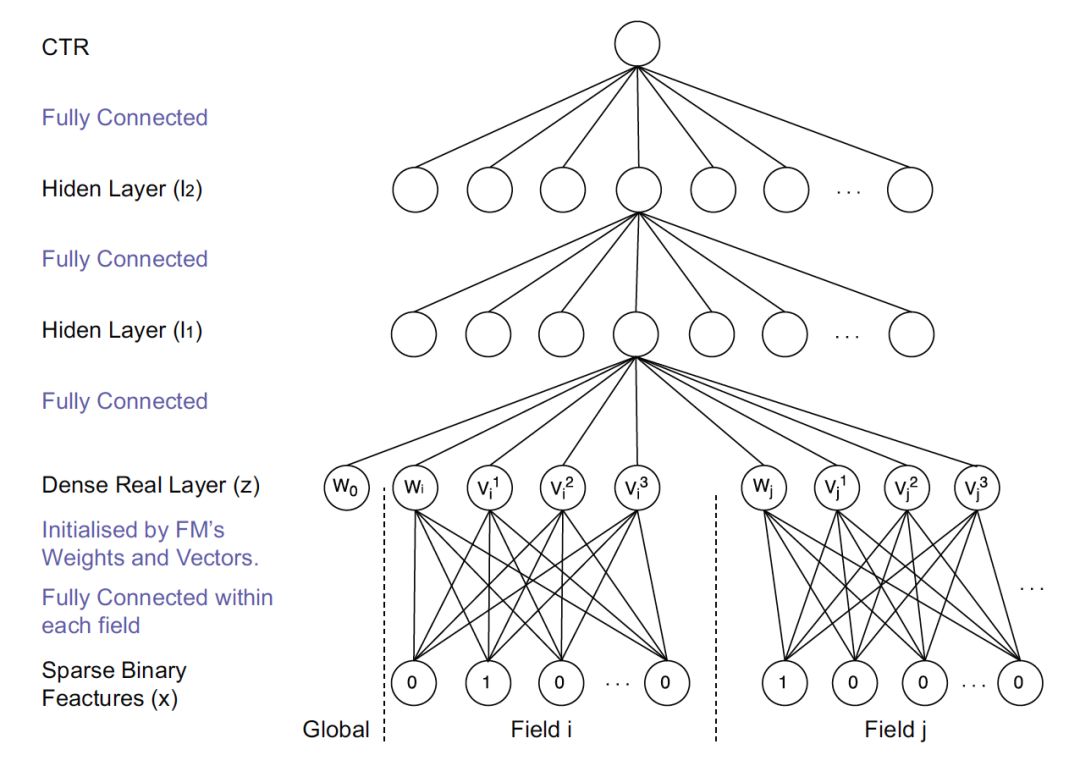
图 3 FMM 模型结构
FNN 利用了 FM 训练得到的物品向量,作为 Embedding 层的初始化权重,从而加快了整个网络的收敛速度。在实际工程中,直接采用 FM 的物品向量作为 Embedding 特征向量输入到后续深度学习网络也是可行的办法。
再延伸一点讲,Embedding 的本质是建立高维向量到低维向量的映射,而“映射”的方法并不局限于神经网络,实质上可以是任何异构模型,这也是 Embedding 预训练的另一大优势。典型的例子是 2013 年 Facebook 提出的著名的 GBDT+LR 的模型,其中 GBDT 的部分本质上是完成了一次特征转换,也可以看作是利用 GBDT 模型完成 Embedding 预训练之后,将 Embedding 输入单层神经网络进行 CTR 预估的过程。
2015 年以来,随着大量 Graph Embedding 技术的发展,Embedding 本身的表达能力进一步增强,而且能够将各类特征全部融合进 Embedding 之中,这使 Embedding 本身成为非常有价值的特征。这些特点都使 Embedding 预训练成为更被青睐的技术途径。
诚然,将 Embedding 过程与深度网络的训练过程割裂,必然会损失一定的信息,但训练过程的独立也带来了训练灵活性的提升。举例来说,由于物品或用户的 Embedding 天然是比较稳定的(因为用户的兴趣、物品的属性不可能在几天内发生巨大的变化),Embedding 的训练频率其实不需要很高,甚至可以降低到周的级别,但上层神经网络为了尽快抓住最新的正样本信息,往往需要高频训练甚至实时训练。使用不同的训练频率更新 Embedding 模型和神经网络模型,是训练开销和模型效果二者之间权衡后的最优方案。
随着 Embedding 技术的进步,Embedding 自身的表达能力也逐步增强,利用 Embedding 向量的相似性,直接将 Embedding 作为推荐系统召回层的方案越来越多的被采用。其中 Youtube 推荐系统召回层(如图 4)的解决方案是典型的做法。
图 4 Youtube 采用 Embedding 作为推荐系统召回层
我曾经在文章 中介绍过了 Youtube 利用深度学习网络生成 Video Embedding 和 User Embedding 的方法。利用最终的 Softmax 层的权重矩阵,每个 Video 对应的列向量就是其 Item Embedding,而 Softmax 前一层的输出就是 User Embedding。在模型部署过程中,没有必要部署整个深度学习网络来完成从原始特征向量到最终输出的预测过程,只需要将 User Embedding 和 Item Embedding 存储到线上内存数据库,通过内积运算再排序的方法就可以得到 item 的排名。这大大加快了召回层的召回效率。
事实上,除了上述的三种主要的 Embedding 应用方向,业界对于 Embedding 的创新性研究不仅没有停止,而且有愈演愈烈之势,阿里的 EGES,Pinterest 的 GNN 应用,Airbnb 基于 Embedding 的搜索模型等大量表达能力非常强的 Embedding 方法的诞生,使 Embedding 本身就已经成为了优秀的 CTR 模型和推荐系统模型。作为计算广告和推荐系统领域的从业者,无论如何强调 Embedding 的重要性都不过分,也希望今后能与大家继续分享 Embedding 领域的前沿知识。
《深度学习 CTR 预估模型实践》专栏内容回顾:
你也「在看」吗? 以上是关于工程中的CTR丨是啥意思?的主要内容,如果未能解决你的问题,请参考以下文章