SQL预编译中order by后为什么不能参数化原因
一、背景
防sql注入都用参数化的方法,但是有些地方是不能参数化的。比如order by后就不能参数化,她有个同事挖sql注入时找有排序功能需求的位置(比如博客常按时间排序),基本十之六七都能挖到sql注入。
二、不能参数化的根本原因
2.1 以java为例进行说明
典型的java写的sql执行代码片段如下:
Connection conn = DBConnect.getConnection();
PreparedStatement ps = null;
ResultSet rs=null;
String sql = " SELECT passwd FROM test_table1 WHERE username = ? ";
ps = conn.prepareStatement(sql);
# 通过setString()指明该参数是字符串类型
ps.setString(1, username);
# 另外还有setInt()等一些其他方法
# ps.setInt(2, test_param);
rs = ps.executeQuery();
ps.setString(1, username)会自动给值加上引号。比如假设username=“ls”,那么拼凑成的语句会是String sql = " SELECT passwd FROM test_table1 WHERE username = \'ls\' ";
再看order by,order by后一般是接字段名,而字段名是不能带引号的,比如 order by username;如果带上引号成了order by \'username\',那username就是一个字符串不是字段名了,这就产生了语法错误。
所以order by后不能参数化的本质是:一方面预编译又只有自动加引号的setString()方法,没有不加引号的方法;而另一方面order by后接的字段名不能有引号。(至于为什么不弄个能不自动加引号的set方法那就不太懂了)
更本质的说法是:不只order by,凡是字符串但又不能加引号的位置都不能参数化;包括sql关键字、库名表名字段名函数名等等。
2.2 不能参数化位置的防sql注入办法
不能参数化的位置,不管怎么拼接,最终都是和使用“+”号拼接字符串的功效一样:拼成了sql语句但没有防sql注入的效果。
但好在的一点是,不管是sql关键字,还是库名表名字段名函数名对于后台开发者来说他的集合都是有限的,更准确点应该说也就那么几个。
这时我们应可以使用白名单的这种针对有限集合最常用的处理办法进行处理,如果传来的参数不在白名单列表中,直接返回错误即可。
代码类似如下:
if para_str.equals("key_str1"){
...;
}
else if test_str.equals("key_str2"){
...;
}
else{
throw new Exception("parameter error.");
}
三、python中如何使用预编译
import pymysql
class TestDB():
def __init__(self):
# 数据库连接信息,改成自己的。ip-用户名-密码-数据库名
self.test_db = pymysql.connect("192.168.220.128","root","toor","test_db")
# 游标
self.cursor = self.test_db.cursor()
def query_password_by_username(self, username):
# 我们知道python中构造字符串的方法一般有四种
# 第一种。+号拼接形式,形如:
# self.cursor.execute("SELECT passwd FROM test_table1 WHERE username = \'" + username + "\'")
# 第二种。format()形式,形如:
# self.cursor.execute("SELECT passwd FROM test_table1 WHERE username = \'{}\'".format(username))
# 第三种。最新的f-string形式,形如:
# self.cursor.execute(f"SELECT passwd FROM test_table1 WHERE username = \'{username}\'")
# 第四种。现在仍比较多见的%s形式,形如:
# self.cursor.execute("SELECT passwd FROM test_table1 WHERE username = \'%s\'" % (username))
# 但不管是以上四种的哪一种(包括可能这里没提到的一些字符串构造写法),他们都没有预防sql注入的效果
# 从他们自身角度说,他们本来就是为了构造字符串,并不是专门为了构造sql语句同时防止sql注入
# 从pymysql角度说,他接收到的就是一个写好的sql语句,没有任何特征可供他判断这条sql语句有没有被注入过,他只能直接执行
# execute() 函数本身有接受sql语句参数位的,可以通过python自身的函数处理sql注入问题,启用该功能的写法如下:
self.cursor.execute("SELECT passwd FROM test_table1 WHERE username = %s", (username))
args = (id, type)
cur.execute(\'select id, type ,name from xl_bugs where id = %s and type = %s\', args )
错误用法:
sql = "select id,type,name from xl_bugs where id = %s and type = %s" % (id, type)
cur.execute(sql)
# 在写法上,相较于第四种%s构造形式差别不大,一是用逗号(,)代替了百分号(%);二是%s两边去掉了单引号。但有着本质上的差别
# %先格式化成一条语句交给pymysql执行,pymysql并不能参与sql语句的构造,只能传过来什么执行什么
# ,相当于分成模板和参数元组两个参数传给pymysql,最后的sql语句由pymysql构造而成,这样pymysql就能处理参数防止sql注入
# 不过要注意,如果参数本身是整形而不是字符串类型,那么这种方法虽然也会有异常,但其实是有正确结果输出的。
# 主要的问题在于我不知道execute()本质上是怎么实现防sql注入的。
user_record = self.cursor.fetchone()
return user_record
if __name__ == "__main__":
obj = TestDB()
# 正常形式
username = "ls"
print(f"normal given username is: {username}")
user_record = obj.query_password_by_username(username)
print(f"the password is: {user_record[0]}\\n")
# 注入形式
username = "ls\' and 1 = 2 union select version() -- "
print(f"inject given username is: {username}")
user_record = obj.query_password_by_username(username)
print(f"the password is: {user_record[0]}\\n")
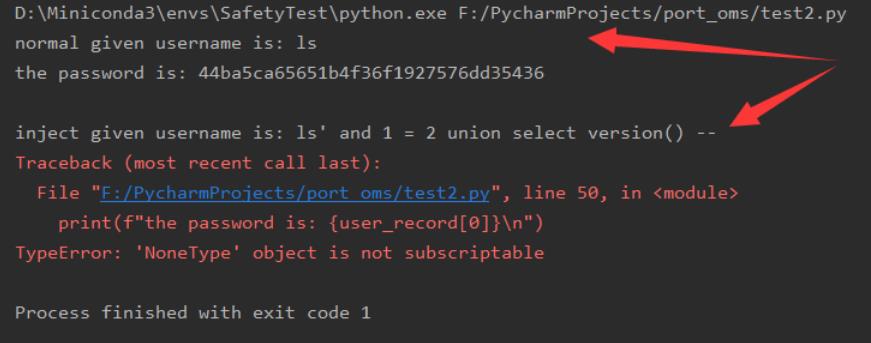
使用预编译结果如下,注入失败:
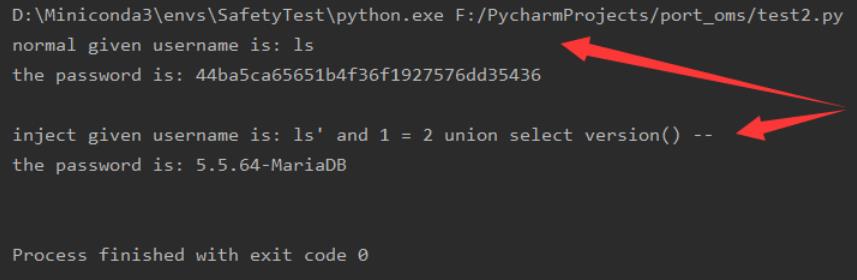
不使用预编译,使用一般字符串构造 结果如下,注入成功:
参考:
https://www.cnblogs.com/lsdb/p/12084038.html
https://www.cnblogs.com/sevck/p/6733702.html