大数据启蒙-初识HDFS
Posted Liguangyang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据启蒙-初识HDFS相关的知识,希望对你有一定的参考价值。
分治思想:
我有一万个元素,查找其中的一个元素,最简单的遍历方法
复杂度为O(4) (遍历四次),如何实现
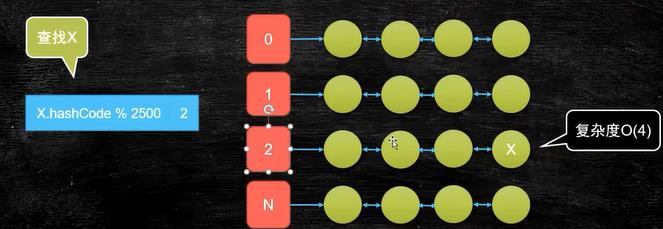
准备2500个数组
查找x
补充知识:什么是hash & 什么是hashCode
https://blog.csdn.net/weixin_38405253/article/details/91922340
小案例:https://www.runoob.com/java/java-string-hashcode.html
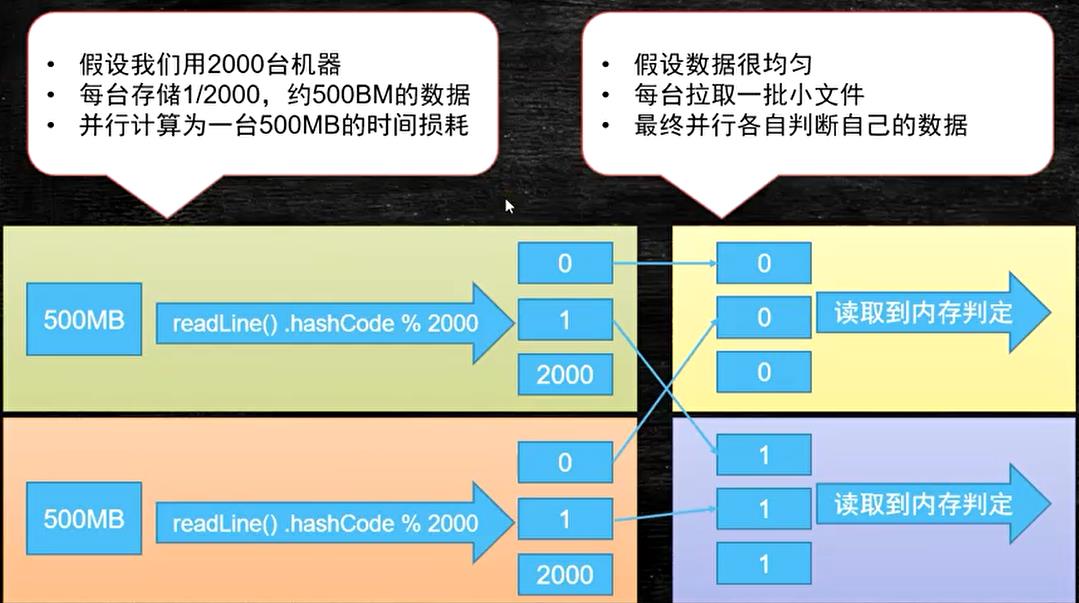
内存寻址比io寻址快10万倍
计算机除了cpu内存之外都叫IO设备
假设lo速度是500MB每秒,1T文件读取一遍需要约30分钟,找寻操作要进行多次查询好,io限制了计算机的计算能力

hash算法(找重复值):hashCode的值是稳定的,相同的行一定会去到一个小文件里
(文件排序):
先抽取50M文件,抽取xxx份

向多节点靠近
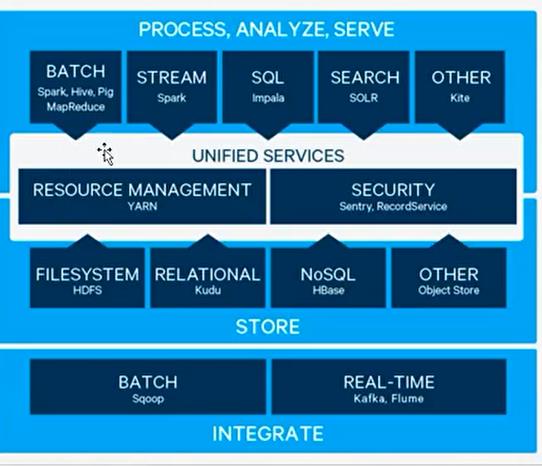
大数据生态
存储模型(HDFS)文件是一个字节数组
文件按线性字节切割成块(block),具有offset(偏量),id
文件与文件的block大小可以不一样
文件除了最后一个block,其他的block大小是一致的
block的大小依据硬件的I/O特性调整
block被分散存放在集群的节点中,具有location(地址)
Block具有副本,没有主从概念,副本不能出现在同一个节点
副本是满足可靠性和性能的关键
文件上传可以只等block大小和副本数,上传只能修改副本数
一次写入多次读取,不支持修改
支持追加数据
分布式系统那么多,为啥要在开发一个HDFS
HDFS能更好的使用的应用层--》不允许修改,只能增加,删除
这样文件块就不会大量的泛洪 ,不会大量消耗CPU内存性能
以上是关于大数据启蒙-初识HDFS的主要内容,如果未能解决你的问题,请参考以下文章