初识Hadoop,轻松应对海量数据存储与分析所带来的挑战
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识Hadoop,轻松应对海量数据存储与分析所带来的挑战相关的知识,希望对你有一定的参考价值。
目录
一、前言:什么是Hadoop?
官方解释:The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing.
(Hadoop是一个由Apache基金会发行的开源的、可靠的、可扩展的分布式计算基础架构。)
Hadoop是apache下的一个顶级项目,域名为hadoop.apache.org,首页如图:

Hadoop中文直译为“分布式计算”,

那么Hadoop和大象有什么关系?大象是Hadoop的图标icon,没有任何实际意义,就像Java语言的图标是一倍咖啡一样,大数据领域的工具名和工具图标都习惯于用动物的名称,仅此而已。如:Hive蜜蜂、Pig猪、Shark鲨鱼、zookeeper动物园管理者等。
hadoop最核心的概念就是HDFS和MapReduce,其中,HDFS是分布式文件系统,用于数据存储,MapReduce是分布式计算框架,用于数据处理,如下图:

解释上图:
Hadoop:Open Source data management with scale-out storage & distributed processing.(Hadoop: 实现了可扩展存储和分布式处理的开源数据管理)
Hadoop四个关键特性Key Characteristics:可扩展性Scalable、可靠性Reliable、弹性Flexible/高效性Efficient(ps:这个有争议,有的地方是Flexible,有的地方是Efficient,这里标明)、经济性Economical
数据存储Storage:HDFS,包括Distributed access "nodes"(分布式访问节点)、Natively redundant(本地备份)、Name node tracks locations(namenode结点跟踪位置)
数据处理Processing:Map Reduce,包括Splits a task accross processors "near" the data & assemblers results(在靠近数据和程序结果的处理器之间拆分任务)、Self-Healing,High Bandwidth Clustered Storage(自身处理高带宽分布式存储)
二、Hadoop生态圈
截止2019年12月30日,Hadoop目前最新版本是Hadoop 2.10.0和Hadoop 3.2.1/3.1.3,分别对应的现有的Hadoop2和Hadoop3中的最高的版本,从版本号上来看,Hadoop2已经非常成熟,Hadoop3则刚刚开始,所有本文使用Hadoop2讲解(包括第六部分在Linux上搭建Hadoop环境)。
2.1 Hadoop2.x的生态系统
如图,展示Hadoop2.X整个生态环境:

注意:上图是正确,有的结构图中将YARN也标注为分布式计算框架,是错误的,YARN是一个资源管理系统,集群资源管理系统,本文第五部分有讲解。
2.2 Hadoop2.x各个组件
对照“2.1 Hadoop2.x的生态系统”,讲解其中的各个组件。
1、HDFS(HadoopDistributedFileSystem,即Hadoop分布式文件系统)
HDFS将大量数据分布到计算机集群上,数据一次写入,但可以多次读取用于分析,hdfs是整个Hadoop的基础,是Hadoop的一个组件。
2、Map Reduce(分布式计算框架)
Map Reduce=mapping+reduce,是一个用于分布式并行数据处理的编程模型,数据处理时将作业分为mapping阶段(即映射阶段)和reduce阶段(归约阶段),MapReduce是hadoop的一个组件。
3、YARN(Yet Another Resource Negotiator,即集群资源管理系统)
YARN是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处,它是hadoop的一个组件。
4、Tez(DAG计算框架)
Tez是一个DAG计算框架,如图:

附:现在Tez用的比较少,反而是另外一个计算框架Spark用得很多,上面的生态图上没有(图上没有不是说不重要,spark是个很重要的工具,因为很常用),Spark是一个计算框架,所以应该是放在MapReduce、Tez、Storm这一层的。
Spark是在Scala语言中实现的,是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等(因为是通用引擎,所以我们一般不需要安装其他引擎了)
Spark属于内存计算,是小数据集上处理复杂迭代的交互系统,内存计算下,号称Spark 比 Hadoop 快100倍(通常这个号称的都有点吹牛逼,但spark确实在速度上突出,Spark the fastest open source engine for sorting a petabyte)。
在实际生产中,如果数据需要快速处理而且资源充足,则可以选择spark;如果资源是瓶颈,则可以使用tez;可以根据不同场景不同数据层次做出选择。和其他计算框架一样,Spark也是一个apache顶级项目。

5、Storm(流式计算框架)

6、Hive(数据仓库)
英文直译为蜂巢,在Hadoop是数据仓库,是一个apache顶级项目。

问题:Hive和下面的Hbase都是用于数据存储,两者有什么区别?
回答:如下表:
| Hive | Hbase | |
| 类型 | 数据仓库 | NoSql数据库/列式数据库 |
| 内部机制 | MR | 数据库引擎 |
| 增删查改 | 只支持导入和查询 | 都支持 |
7、Pig(数据流处理)

8、Mahout(数据挖掘库)

9、Zookeeper(分布式协作服务)
Zookeeper是Hadoop的分布式协调服务。Zookeeper被设计成可以在机器集群上运行,用于Hadoop操作的管理,而且很多Hadoop组件都依赖它。是一个具有高度可用性的服务,其实即使不是Hadoop,很多组件要搭建集群基本上都需要用到Zookeeper来管理,如Solr集群、
注意:

10、Hbase(实时分布式数据库)
Hbase一个的面向列的NoSQL数据库,用在分布式架构中,HBase用于对海量数据进行快速读取/写入。hbase不是hadoop的子集,它和hadoop一样,是一个apache顶级项目。

Hive、Hbase都用户数据存储,那么它们与我们传统的关系型数据库有什么区别呢?如下表:
| Hbase | mysql | |
| 类型 | NoSQL数据库、列式数据库 | 关系型数据库 |
| 存储数据量大小 | PB | GB、TB |
| 数据处理速度 | 数百万条查询/秒 | 数千条查询/秒 |
| 存储方式 | 按列存储 | 按行存储 |
| 数据类型 | Bytes | 各个数据类型,如varchar、int、datetime等 |
上表中,Hbase与传统数据库最大的区别不是存储的数据量的大小,而是数据处理速度,Hbase可以轻松应对PB级别的数据,传统数据库只能处理GB或TB级别数据,太大的数据量会采用水平分表,字段太多采用垂直分表(注意:两种最大区别是处理速度,如果是存储数据量的话,Mysql的也已达到PB级别,但是如果处理这么大的数据量,CRUD会非常慢,所以这里指的是处理速度)
附:计算机中的存储单位
计算机存储单位一般用bit、B、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB……来表示,它们之间的关系是:
1DB=1024NB、1NB=1024BB、1BB=1024YB、1YB=1024ZB、1ZB=1024EB 、1EB=1024PB 、1PB=1024TB、1TB=1024GB、1GB=1024MB、1MB=1024KB、1KB=1024B 、1B=8bit
11、Sqoop(数据库ETL工具)
ETL是Extract-Transform-Load,指抽取(extract)、转换(transform)、加载(load)三个操作,没错,Sqoop就是完成这三个操作的工具

12、Flume(日志收集工具)
很清楚,就是对日志操作的工具,因为Hadoop要存储和处理海量数据,不可避免的有大量的日志,所有专门使用一个工具来收集日志,就是Flume.

13、Ambari(安装、部署、配置和管理工具)
Ambari位于整个生态图的最上面,Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等。

2.3 Apache大数据生态圈目录层次
最后一点,对于整个hadoop2.X的生态系统,我要搞懂它们在apache下的层次关系,像上面所指出的,有的是顶级项目,有的是次级项目,笔者将层次关系整理出图为:

该图为我们纠正两个易错点:
1、整个Apache大数据生态圈,Hadoop只是其中的一个顶级项目,初学者以为“大数据=Hadoop”,应该是“大数据>Hadoop”,对于整个Apache大数据生态圈来说,除了Hadoop,还有很多和Hadoop同级的项目,只是因为Hadoop是整个生态圈中的核心组件,知名度最高,所有才会给人“Hadoop=大数据”的错觉。
2、这个生态圈应该叫“Apache大数据生态圈/生态系统”才准确,“Hadoop2.X生态圈/生态系统”这个称呼不是很准确,因为Hadoop只是Apache里面的一个项目,并不能代表大数据整体,至于为什么叫“Hadoop2.X生态圈/生态系统”,因为这样叫的人多了,所以这样也就是正确的了......
2.3 大数据与云计算
大数据Big Data:数据量大Volume、数据多样Variety、数据处理高速Velocity、数据有价值Value;
云计算cloud computing:
附:Hadoop与云计算的关系
一般认为,云计算由三层构成:IAAS、PAAS、SAAS
IAAS:Infrastructure-as-a-service基础设施即服务,该层为云计算下层,将互联网基础设施(如网络、存储、服务器)作为一种服务,典型的实现有:OpenStack、CloudStack、RackSpace.
PAAS:Platform-as-a-service平台即服务,该层为云计算中间层,将软件开发平台和软件运营的云端环境作为一种服务,典型的实现有:Google AppEngine、Apache Hadoop
SAAS:Software-as-a-service软件即服务,该层为云计算上层,将开发完成的功能软件作为一种服务,典型的实现有:Google Apps
则Hadoop与云计算的关系是:Apache Hadoop是云计算中的第二层(PAAS平台即服务)。
三、HDFS(分布式文件系统)
HDFS,全称为HadoopDistributedFileSystem,直译Hadoop分布式文件系统,是Hadoop中最重要的一个组成之一,用于海量数据存储。
3.1 hdfs架构
HDFS架构如下:包括NameNode DataNode SecondaryNameNode,如图:

注意:这个图是hdfs架构图,其实这个图百度就都可以搜索到,这里主要讲解这个的含义:
dfsClient,英文全称DistributedFileSystem Client,分布式文件系统客户端,就是访问hdfs的客户端,理解为一般的客户端即可,可以对存储的文件块datanode(里面的数据及数据校验和)做读写操作。
rack表示机架,rack1和rack2分别表示机架1和机架2,这里作为示例之用,实际上可以有n个机架,每个物理机架可以认为是一个文件块集合,即datanode集合,这里将这种集合用datanodes表示。
datanode表示一个文件块,里面存放文件块数据及块数据的校验和,一个机架可以有n个这样的文件块,上图表示用datanode1-datanodeN表示出来。
metadata表示元数据,包括filename文件名,文件属性,文件目录结构,每个文件的块列表和块所在的datanode,上图用metadata方框表示的很清楚。
namenode是主节点,里面存放metadata元数据,上图用箭头表示了,其他的如dfsclient、secondarynamenode可以对namenode做元数据操作、同步元数据与日志等,上图也表示出来了,而namenode可以对文件块集合datanodes做blocks operation块操作,上图也表示出来了。
secondarynamenode也是管理层,是监控整个hdfs状态的辅助后台程序,所以上图中表示其对namenode同步元数据与日志。
整个hdfs中,分为namenode、Secondary namenode、Datanode:
namenode是主节点,属于管理层,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的datanode等。namenode是放在内存中的。
Secondary namenode 管理层,用来监控HDFS状态的辅助后台程序,每隔一段时间获取hdfs元数据快照。
Datanode 应用层 用于进行数据的存储,被namenode进行管理,要定时的想namenode工作汇报,执行namenode分配分发的任务,在本地文件系统存储文件块数据,以及块数据的检验和。
3.2 hdfs存储
hdfs上存储文件的特点是文件以块的形式存储,记住两句:
第一,一个文件多个块:表示存放在hdfs上的文件是以块的形式存储的,即hdfs的文件的存储方式以块来存储的,每个文件被分成多个块(这个文件具体被分为多成多少个块是可以设置,图中为r指示);
第二:一个块多个副本:每个块有多个副本存储在不同机器上,副本数在文件生成时指定(默认为3),每一个块的不同副本一定不会存放在同一个节点上。
如图:

让我们来解释一下上图,该图有两个文件:
第一个文件:/users/sameerp/data/part-0,r:2表示这个文件有两个块,分别是1和3,其副本数均为2,且每个块的副本都存在在不同的datanode结点上,嗯嗯,这是正确的。
第二个文件:/users/sameerp/data/part-1,r:3表示这个文件有三个块,分别是2、4和5,其副本数均为3,且每个块的副本都存在在不同的datanode结点上,嗯嗯,这是正确的。
四、MapReduce(分布式计算框架)
MapReduce(本来就是全称写法),是Hadoop另一个重要组成部分,包括map映射+reduce归约,简称为MR,是一个分布式计算模型框架,用于海量数据处理,其核心是对数据的排序优化。
4.1 Map+Reduce
MapReduce将整个并行计算过程抽象到两个函数,分别是
map()函数:对一些独立元素组成的列表每一个元素进行指定操作,可以高度并行
reduce()函数:对一个列表的元素进行合并。
对于程序员来说,一个简单的mapreduce程序只需要四个部分,即程序员只需做四件事,map()函数 reduce()函数 input输入 output 输出,其他的事情交给框架来完成。
4.2 MapReduce架构
MapReduce架构如下:包括Jobtracker tasktracker
Jobtracker 管理层,管理集群资源和对任务进行资源调度,监护人去执行,接收用户提交的作业,负责启动、跟踪任务执行。
tasktracker应用层,执行jobtracker分发的任务,并想jobtracker汇报工作,管理各个任务在每一个节点上的执行情况。
具体对比:
| Jobtracker | tasktrackers(tasktracker集合) |
| Master主节点 | Slave从节点 |
| 功能与用途: 1、作为管理层,管理所有作业; 2、将作业分解成一个锡类任务; 3、将任务指派给每个tasktracker 4、作业/任务监控、错误处理 | 功能与用途: 1、运行Map Task和Reduce Task 2、与Jobtracker交互,执行命令并汇报任务状态 |
mapreduce架构图如下:

解释一下MapReduce架构图,图中有client、heartbeat、Jobtracker、tasktrackers、tasktracker、maptask、reducetask:
client表示客户端,直接于主节点Jobtracker通信;
heartheat表示心跳,用于Jobtracker和每个tasktracker通信,确认对方是否存活;
mapreduce架构分为Jobtracker和tasktrackers,Jobtracker作为主节点Master,充当管理层,管理所有作业;
tasktrackers是tasktracker集合,包含n个tasktracker,每一个tasktracker两种任务,Map任务和Reduce任务,即maptask和
reducetask。
4.3 MapReduce数据处理
4.3.1 job与task
MapReduce数据处理,首先要区分好job和task两个概念:
job:表示客户端的每一个计算请求,称为一个作业
task:每一个作业,都需要拆分开来,交由多个服务器来完成,拆分出来的执行单位,就称为任务。
task分为maptask和reducetask两种,分别进行map操作和reduce操作,根据job设置map类和reduce类。
关于maptask和reducetask区别:
| Map task | Reduce task |
| Map引擎 | Reduce引擎 |
| 解析每一条数据,传递给用户编写的map() | 从Map task上远程读取输入数据,并对数据排序 |
| 将map()输出数据写入本地磁盘(如果是map-only作业,则直接写入HDFS) | 将数据按照分组传递给用户编写的reduce() |
4.3.2 MapReduce数据处理

对于上图的理解是:client提交job请求给Jobtracker,所以图上是单向箭头,Jobtracker将job切分成多个task,分配到不同的map和reduce任务到集群的每一个tasktracker上。这就是MapReduce整个数据处理过程的简单描述。
五、YARN(资源管理系统)
YRAN,全称为Yet Another Resource Negotiator,直译为另一种资源协调者,是一个资源管理系统,负责集群资源管理的统一和调度,是自Hadoop2开始的一个重要内容,Hadoop2.x和Hadoop3.x均有这个组件。
5.1 YARN架构
YARN架构图如下:

对于上图的理解:
1、 ResourceManager(RM)
YARN分层结构的本质是ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础NodeManager(YARN 的每节点代理)。ResourceManager还与 ApplicationMaster 一起分配资源,与NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
1)处理客户端请求;
2)启动或监控ApplicationMaster;
3)监控NodeManager;
4)资源的分配与调度。
2、 ApplicationMaster(AM)
ApplicationMaster 管理在YARN内运行的每个应用程序实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
总的来说,AM有以下作用
1)负责数据的切分
2)为应用程序申请资源并分配给内部的任务
3)任务的监控与容错
3、NodeManager(NM)
NodeManager管理一个YARN集群中的每个节点。NodeManager提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1通过插槽管理Map和Reduce任务的执行,而NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。YARN继续使用HDFS层。它的主要 NameNode用于元数据服务,而DataNode用于分散在一个集群中的复制存储服务。
1)单个节点上的资源管理;
2)处理来自ResourceManager上的命令;
3)处理来自ApplicationMaster上的命令。
4、Container
对任务运行环境进行抽象,封装CPU、内存等多维度的资源以及环境变量、启动命令等任务运行相关的信息。比如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
小结:要使用一个YARN集群,首先需要来自包含一个应用程序的客户的请求。ResourceManager 协商一个容器的必要资源,启动一个ApplicationMaster 来表示已提交的应用程序。通过使用一个资源请求协议,ApplicationMaster协商每个节点上供应用程序使用的资源容器。执行应用程序时,ApplicationMaster 监视容器直到完成。当应用程序完成时,ApplicationMaster 从 ResourceManager 注销其容器,执行周期就完成了。
六、手把手搭建Hadoop环境(Linux上)
Hadoop自诞生出就青睐于Linux环境,虽然从Hadoop2开始有了windows环境的版本,但是实际使用中我们还是在Linux上搭建,
附:Linux两种系列,基本区别如下:
| 包名 | 管理工具 | 管理单个软件包 | 装包例子 | 实例 | |
| Debian系列 | .deb | apt-get | dpkg | apt-get install xxx | Debian、Ubuntu |
| Redhat系列 | .rpm | yum | rpm | yum -y | Redhat Enterprise Linux、FedoraCore、CentOS |
windows exe 和 zip
Debian apt-get install xxx.deb 和 tar -zxvf xxx.tar.gz
redhat yum -y xxx.rpm 和 tar -zxvf xxx.tar.gz
常用的 ,centos是redhat,ubuntu是debian
这里笔者将在CentOS上搭建。Hadoop拥有三种搭建方式:单机模式Local Mode/本地模式Standalone Mode,伪分布式模式Pseudo-Distributed Mode,完全分布式模式Fully Distributed Mode.三者区别:
| 定义 | |
| 单机模式Local Mode/本地模式Standalone Mode | 需要0个守护进程,部署到一个机器上 |
| 伪分布式模式Pseudo-Distributed Mode | 需要5个守护进程(HDFS 3个+MapReduce 2个),所有的守护进程部署到一个机器上 |
| 完全分布式模式Fully Distributed Mode | 需要5个守护进程(HDFS 3个+MapReduce 2个),每一个守护进程部署到一个机器上 |
这里仅介绍单机模式安装,部署环境:vm15+Centos7.0+jdk7.0+hadoop2.10
这里因为csdn资源上传只能小于240MB,所有hadoop2.10的压缩包提交不出来,这个包373MB,所有上传不了,

读者可以到hadoop官网下载
6.1 安装jdk
将jdk解压到要任意位置,一般是/usr/local目录,笔者这里选择/opt/modules目录,如图:

然后vi /etc/profile 配置环境变量,如图:

然后 source /etc/profile使配置生效,输入java -version看到类似下图即安装成功。

6.2 安装hadoop
和jdk一样,也是压缩包安装,先hadoop解压到任意位置,笔者这里为/opt/modules目录,并使用vi /etc/profile配置环境变量,

然后 source /etc/profile 是配置生效,输入hadoop version看到类似内容说明安装成功。

但是现在还不能马上启动,还要完成几个相关的配置。
vi core-site.xml ,配置如下:ip为自己的ip,port默认

vi hadoop-env.sh 配置成你自己的jdk安装路径
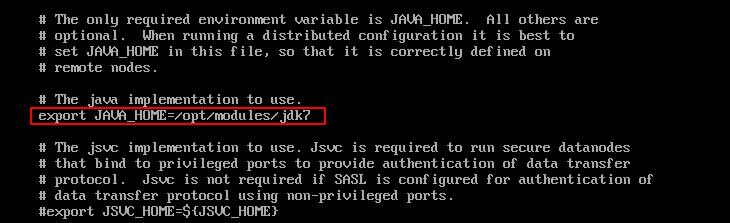
vi hdfs-site.xml

复制默认的cp mapred-site.xml.template ./mapred-site.xml 配置命名为mapred-site.xml
vi mapred-site.xml 添加如下配置

vi yarn-site.xml 添加如下配置

格式化,执行命令 hadoop namenode -format,成功之后启动
6.3 成功运行
hadoop安装目录下的sbin目录下,运行./start-all.sh


附:hadoop2.X与hadoop3.X的区别

附:hadoop2.X与hadoop3.X的区别
1.License
adoop 2.x - Apache 2.0,开源
Hadoop 3.x - Apache 2.0,开源
2.支持的最低Java版本
Hadoop 2.x - java的最低支持版本是java 7
Hadoop 3.x - java的最低支持版本是java 8
3.容错
Hadoop 2.x - 可以通过复制(浪费空间)来处理容错。
Hadoop 3.x - 可以通过Erasure编码处理容错。
4.数据平衡
Hadoop 2.x - 对于数据,平衡使用HDFS平衡器。
Hadoop 3.x - 对于数据,平衡使用Intra-data节点平衡器,该平衡器通过HDFS磁盘平衡器CLI调用。
5.存储Scheme
Hadoop 2.x - 使用3X副本Scheme
Hadoop 3.x - 支持HDFS中的擦除编码。
6.存储开销
Hadoop 2.x - HDFS在存储空间中有200%的开销。
Hadoop 3.x - 存储开销仅为50%。
7.存储开销示例
Hadoop 2.x - 如果有6个块,那么由于副本方案(Scheme),将有18个块占用空间。
Hadoop 3.x - 如果有6个块,那么将有9个块空间,6块block,3块用于奇偶校验。
8.YARN时间线服务
Hadoop 2.x - 使用具有可伸缩性问题的旧时间轴服务。
Hadoop 3.x - 改进时间线服务v2并提高时间线服务的可扩展性和可靠性。
9.默认端口范围
Hadoop 2.x - 在Hadoop 2.0中,一些默认端口是Linux临时端口范围。所以在启动时,他们将无法绑定。
Hadoop 3.x - 但是在Hadoop 3.0中,这些端口已经移出了短暂的范围。
10.工具
Hadoop 2.x - 使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具。
Hadoop 3.x - 可以使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具。
11.兼容的文件系统
Hadoop 2.x - HDFS(默认FS),FTP文件系统:它将所有数据存储在可远程访问的FTP服务器上。 Amazon S3(简单存储服务)文件系统Windows Azure存储Blob(WASB)文件系统。
Hadoop 3.x - 它支持所有前面以及Microsoft Azure Data Lake文件系统。
12.Datanode资源
Hadoop 2.x - Datanode资源不专用于MapReduce,我们可以将它用于其他应用程序。
Hadoop 3.x - 此处数据节点资源也可用于其他应用程序。
13.MR API兼容性
Hadoop 2.x - 与Hadoop 1.x程序兼容的MR API,可在Hadoop 2.X上执行
Hadoop 3.x - 此处,MR API与运行Hadoop 1.x程序兼容,以便在Hadoop 3.X上执行
14.支持Microsoft Windows
Hadoop 2.x - 它可以部署在Windows上。
Hadoop 3.x - 它也支持Microsoft Windows。
15.插槽/容器
Hadoop 2.x - Hadoop 1适用于插槽的概念,但Hadoop 2.X适用于容器的概念。通过容器,我们可以运行通用任务。
Hadoop 3.x - 它也适用于容器的概念。
16.单点故障
Hadoop 2.x - 具有SPOF的功能,因此只要Namenode失败,它就会自动恢复。
Hadoop 3.x - 具有SPOF的功能,因此只要Namenode失败,它就会自动恢复,无需人工干预就可以克服它。
17.HDFS联盟
Hadoop 2.x - 在Hadoop 1.0中,只有一个NameNode来管理所有Namespace,但在Hadoop 2.0中,多个NameNode用于多个Namespace。
Hadoop 3.x - Hadoop 3.x还有多个名称空间用于多个名称空间。
18.可扩展性
Hadoop 2.x - 我们可以扩展到每个群集10,000个节点。
Hadoop 3.x - 更好的可扩展性。 我们可以为每个群集扩展超过10,000个节点。
19.更快地访问数据
Hadoop 2.x - 由于数据节点缓存,我们可以快速访问数据。
Hadoop 3.x - 这里也通过Datanode缓存我们可以快速访问数据。
20.HDFS快照
Hadoop 2.x - Hadoop 2增加了对快照的支持。 它为用户错误提供灾难恢复和保护。
Hadoop 3.x - Hadoop 2也支持快照功能。
21.平台
Hadoop 2.x - 可以作为各种数据分析的平台,可以运行事件处理,流媒体和实时操作。
Hadoop 3.x - 这里也可以在YARN的顶部运行事件处理,流媒体和实时操作。
22.群集资源管理
Hadoop 2.x - 对于群集资源管理,它使用YARN。 它提高了可扩展性,高可用性,多租户。
Hadoop 3.x - 对于集群,资源管理使用具有所有功能的YARN。
七、尾声
本文第一部分引入Hadoop,然后中间分别介绍Hadoop生态、HDFS、MapReduce、YARN四个内容,最后搭建出Hadoop环境。
天天打码,天天进步!
以上是关于初识Hadoop,轻松应对海量数据存储与分析所带来的挑战的主要内容,如果未能解决你的问题,请参考以下文章