循环神经网络模型,seq2seq模型理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了循环神经网络模型,seq2seq模型理解相关的知识,希望对你有一定的参考价值。
参考技术A 循环神经网络与一般神经网络的区别:1、样本数据区别
循环神经网络的训练数据的基本单位是num_steps,num_steps个样本作为一组,num_steps个样本有先后顺序。
数据的shape: batch_size,num_step,num_features
训练数据的生成方式有:随机采样和相邻采样
2、网络结构的区别
在一个num_steps为一组的数据中,上一个样本的输出(历史信息),作为下一输入的一部分。
第一个的输入是历史信息是state,人工初始化
RNN与LSTM的区别 :
RNN之将上一个输出(H)作为下一个样本的输入信息,一个训练单元有两个输入Xt和Ht-1
LSTM在RNN的基础上增加了state变量(C),一个训练单元有三个输入Xt,Ct-1,Ht-1
RNN图示:
LSTM图示:
seq2seq模型理解:
seq2seq是encoder-decoder结构的实例
encoder的作用是从输入序列提取出context信息,也就是lstm网络的最后一个state(h,c)
decoder的作用是以encoder得到的context信息作为initial-state,以<start>作为X1,预测序列,直到输出<end>
transformer模型解读
最近在关注谷歌发布关于BERT模型,它是以Transformer的双向编码器表示。顺便回顾了《Attention is all you need》这篇文章主要讲解Transformer编码器。使用该模型在神经机器翻译及其他语言理解任务上的表现远远超越了现有算法。
在 Transformer 之前,多数基于神经网络的机器翻译方法依赖于循环神经网络(RNN),后者利用循环(即每一步的输出馈入下一步)进行顺序操作(例如,逐词地翻译句子)。尽管 RNN 在建模序列方面非常强大,但其序列性意味着该网络在训练时非常缓慢,因为长句需要的训练步骤更多,其循环结构也加大了训练难度。与基于 RNN 的方法相比,Transformer 不需要循环,而是并行处理序列中的所有单词或符号,同时利用自注意力机制将上下文与较远的单词结合起来。通过并行处理所有单词,并让每个单词在多个处理步骤中注意到句子中的其他单词,Transformer 的训练速度比 RNN 快很多,而且其翻译结果也比 RNN 好得多。
模型结构
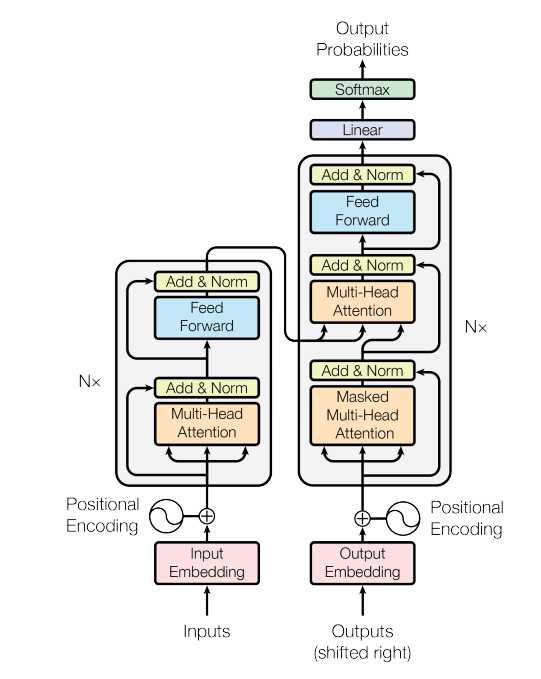
图一、The Transformer Architecture
如图一所示是谷歌提出的transformer 的架构。这其中左半部分是 encoder 右半部分是 decoder。
- Encoder: 由N=6个相同的layers组成, 每一层包含两个sub-layers. 第一个sub-layer 就是多头注意力层(multi-head attention layer)然后是一个简单的全连接层。 其中每个sub-layer都加了residual connection(残差连接)和normalisation(归一化)。
- Decoder: 由N=6个相同的Layer组成,但这里的layer和encoder不一样, 这里的layer包含了三个sub-layers, 其中有一个self-attention layer, encoder-decoder attention layer 最后是一个全连接层。前两个sub-layer 都是基于multi-head attention layer。这里有个特别点就是masking, masking 的作用就是防止在训练的时候 使用未来的输出的单词。比如训练时,第一个单词是不能参考第二个单词的生成结果的。Masking就会把这个信息变成0,用来保证预测位置 i 的信息只能基于比 i 小的输出。
Attention
-
Scaled dot-product attention
“Scaled dot-product attention”如下图二所示,其输入由维度为d的查询(Q)和键(K)以及维度为d的值(V)组成,所有键计算查询的点积,并应用softmax函数获得值的权重。
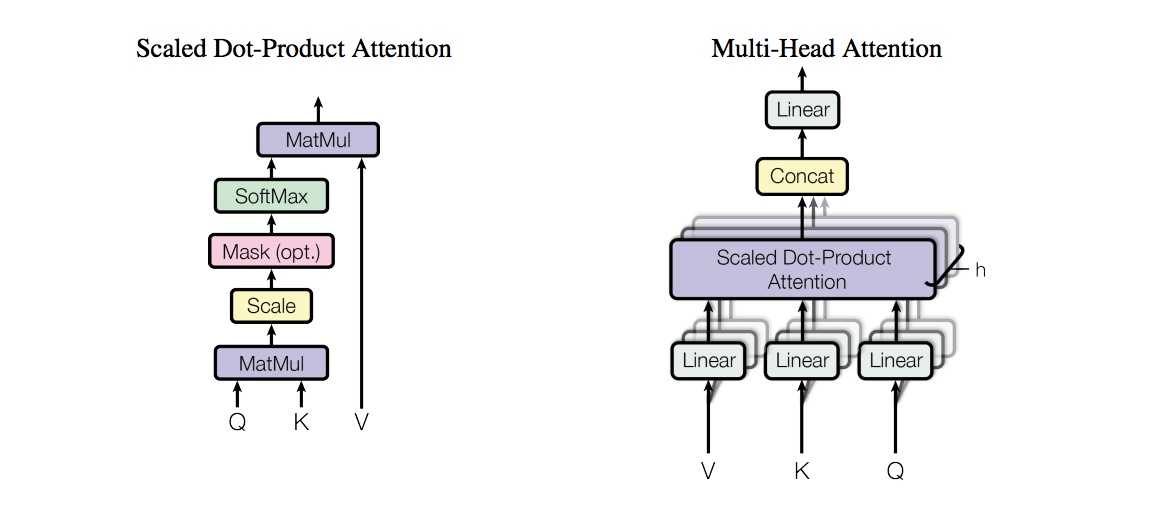
图二、两种Attention实现框图
“Scaled dot-product attention”具体的操作有三个步骤:
-
-
- 每个query-key 会做出一个点乘的运算过程,同时为了防止值过大除以维度的常数
- 最后会使用softmax 把他们归一化
- 再到最后会乘以V (values) 用来当做attention vector
-
数学公式表示如下:
在论文文里, 这个算法是通过queriies, keys and values 的形式描述的,非常抽象。这里用了一张CMU NLP课里的图来进一步解释, Q(queries), K (keys) and V(Values), 其中 Key and values 一般对应同样的 vector, K=V 而Query vecotor 是对应目标句子的 word vector。如下图三所示。
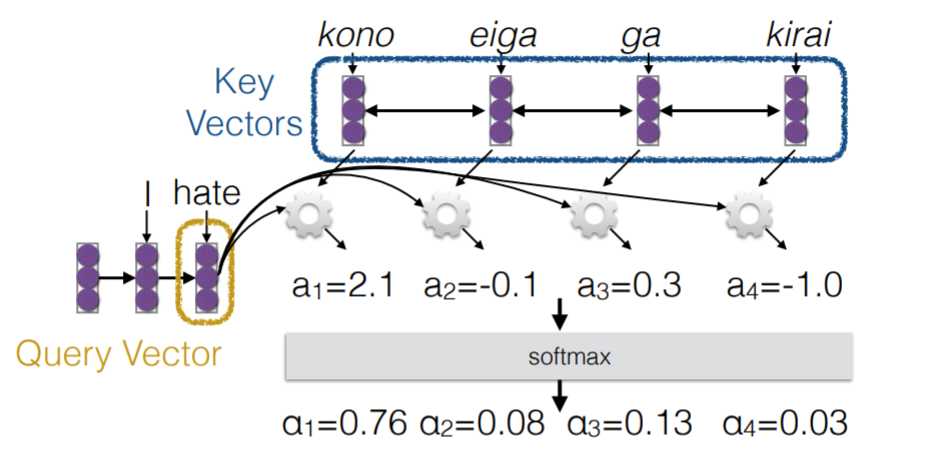
图三、Attention process (source:http://phontron.com/class/nn4nlp2017/assets/slides/nn4nlp-09-attention.pdf)
-
Multi-head attention
上面介绍的scaled dot-product attention, 看起来还有点简单,网络的表达能力还有一些简单所以提出了多头注意力机制(multi-head attention)。multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来,self-attention则是取Q,K,V相同。

![]()
论文中使用了8个平行的注意力层或者头部。因此用的维度dk=dv=dmodel/h=64。
Position-wise feed-forward networks
第二个sub-layer是个全连接层,之所以是position-wise是因为处理的attention输出是某一个位置i的attention输出。全连接层公式如下所示:
![]()
Positional Encoding
除了主要的Encoder和Decoder,还有数据预处理的部分。Transformer抛弃了RNN,而RNN最大的优点就是在时间序列上对数据的抽象,所以文章中作者提出两种Positional Encoding的方法,将encoding后的数据与embedding数据求和,加入了相对位置信息。
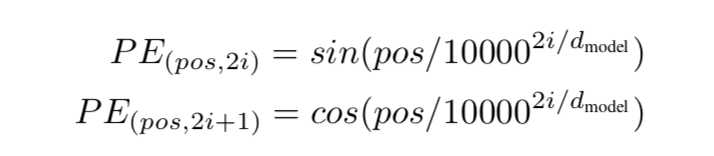
优点
作者主要讲了以下几点,复杂度分析图如下图四所示:
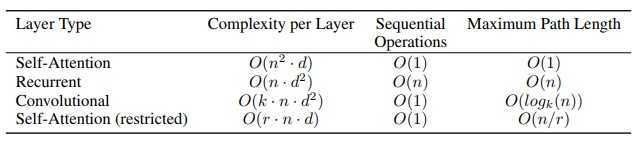
图四、Transformer模型与其他常用模型复杂度比较图
Transformer是第一个用纯attention搭建的模型,不仅计算速度更快,在翻译任务上也获得了更好的结果。该模型彻底抛弃了传统的神经网络单元,为我们今后的工作提供了全新的思路。
以上是关于循环神经网络模型,seq2seq模型理解的主要内容,如果未能解决你的问题,请参考以下文章
深入理解Seq2seq模型(Sequence2sequence)
深入理解Seq2seq模型(Sequence2sequence)
[翻译] 可视化神经网络机器翻译模型(Seq2Seq模型的注意力机制)