推荐系统之评估方法和评价指标PR、ROC、AUC
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统之评估方法和评价指标PR、ROC、AUC相关的知识,希望对你有一定的参考价值。
参考技术A推荐系统的评估相关的知识比重在整个推荐系统的知识框架中占比不大,但是其重要程度不言而喻,因为采用的评价指标直接影响到了推荐系统的优化方向是否正确。 评价指标主要用于评价推荐系统各方面的性能 ,按照应用场景可以分为离线评估和线上测试。其中离线评估的主要方法包括 Holdout检验、交叉检验、留一验证、自助法 等,评价指标主要包括 用户满意度、预测准确度、召回率、覆盖率、多样性、新颖性、流行度、均方根误差、对数损失、P-R曲线、AUC、ROC曲线 等等。线上测试的评估方法主要包括 A/B测试、Interleaving方法 等,评价指标主要包括 点击率、转化率、留存率、平均点击个数 等等。本文将着重介绍 离线评估相关方法和指标 ,尤其是 P-R曲线、AUC、ROC曲线 等,这些评价指标是最常用的也是最基本的,出现在各类推荐相关的论文中,因此需要重点掌握。
在推荐系统的评估过程中,离线评估往往被当做最常用也是最基本的评估方法。顾名思义,离线评估是指在将模型部署于线上环境之前,在离线环境中进行的评估。由于不用部署到生产环境,离线评估没有线上部署的工程风险,也无须浪费宝贵的线上流量资源,而且具有测试时间短,同时进行多组并行测试、能够利用丰富的线下计算资源等诸多优点。
Holdout检验的缺点也很明显,即在验证集上计算出来的评估指标与训练集合验证集的划分有直接关系,如果仅仅进行少量Holdout检验,则得到的结论存在较大的随机性。为了消除这种随机性,“交叉检验”的思想被提出。
结果:
精准率和召回率是矛盾统一的两个指标:为了提高精准率,分类器需要尽量在“更有把握时”才把样本预测为正样本,即降低了精准率计算公式中的分母部分。但往往会因为过于保守而漏掉很多“没有把握”的正样本,导致召回率过低。
以挑选西瓜为例,若希望将好瓜尽可能多地挑选出来,则可通过增加选瓜的数量来实现,如果将所有的西瓜都选上,那么所有的好瓜也必然都被选上了,这样就会导致Precision很低,但是Recall就会相对较高。若希望选出的瓜中好瓜比例尽可能高,则可只挑选最有把握的瓜,但这样就难免会漏掉不少好瓜,使得Recall较低。
为了综合反映Precision和Recall的结果,可以使用F1-score,F1-score是精准率和召回率调和平均值,定义如下:
用一张图总结一下:
然后,由此引出True Positive Rate(真阳率TPR)、False Positive Rate(伪阳率FPR)两个概念,计算方式如下:
仔细观察上面的两个式子,发现两个式子的分子其实对应了混淆矩阵的第二行,即预测类别为1的那一行。另外可以发现TPR就是用TP除以TP所在的列,FPR就是用FP除以FP所在的列。二者的含义如下:
表示的意义是:对于不论真实类别是0还是1的样本,模型预测样本为1的概率都是相等的。
换句话说,模型对正例和负例毫无区分能力,做决策和抛硬币没啥区别。因此,我们认为AUC的最小值为0.5(当然也存在预测相反这种极端的情况,AUC小于0.5,这种情况相当于分类器总是把对的说成错的,错的认为是对的,那么只要把预测类别取反,便得到了一个AUC大于0.5的分类器)。
其中,1代表正样本,0代表负样本。我们来计算下它们的Precision。如下表所示:
AP的计算只取正样本处的Precision进行平均,即AP = (1/1+2/4+3/5+4/6)/4=0.6917。如果推荐系统对测试集中每个用户都进行样本排序,那么每个用户都会计算出一个AP值,再对所有用户的AP值进行平均,就得到了mAP。也就是说,mAP是对精确度平均的平均。
值得注意的是,mAP的计算方法和P-R曲线、ROC曲线的计算方式完全不同,因为mAP需要对每个用户的样本进行分用户排序,而P-R曲线和ROC曲线均是对全量测试样本进行排序。
下面以一个经典的莺尾花分类的例子来展示各种指标的计算。
导入莺尾花数据,使用Holdout检验,将数据集随机划分成训练集和测试集:
创建一个线性SVM分类器,计算测试数据到决策平面的距离以及对测试数据进行预测:
计算准确率:
计算精准率:
计算召回率:
计算F1-Score:
计算精确率均值AP:
计算混淆矩阵:
绘制P-R曲线,并且计算AUC:
绘制ROC曲线并且计算AUC:
无论离线评估如何仿真线上环境,终究无法完全还原线上的所有变量。对几乎所有的互联网公司来说,线上A/B测试都是验证新模块、新功能、新产品是否有效的主要测试方法。
上图中用户被随机均分成两组,橘色和绿色代表被控制的变量,最右侧是转化率。通过这种方式可以看到,系统中单个变量对系统产生的整体影响。
相对离线评估而言,线上A/B测试无法被替代的原因主要有以下三点:
一般来讲,A/B测试都是模型上线前的最后一道测试,通过A/B测试检验的模型将直接服务于线上用户,完成公司的商业目标。因此,A/B测试的指标与线上业务的核心指标保持一致。
下表列出了电商类推荐模型、新闻类推荐模型、视频类推荐模型的线上A/B测试的主要评估指标:
线上A/B测试的指标与离线评估指标有较大差异。离线评估不具备直接计算业务核心指标的条件,因此退而求其次,选择了偏向于技术评估的模型相关指标。但在公司层面,更关心能够驱动业务发展的核心指标。因此,在具备线上测试环境时,利用A/B测试验证模型对业务核心指标的提升效果是有必要的。从这个意义上讲,线上A/B测试的作用是离线评估无法替代的。
评估指标:ROC,AUC,PrecisionRecallF1-score
一、ROC,AUC
ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣 。

ROC曲线一般的横轴是FPR,纵轴是FPR。AUC为曲线下面的面积,作为评估指标,AUC值越大,说明模型越好。如下图:
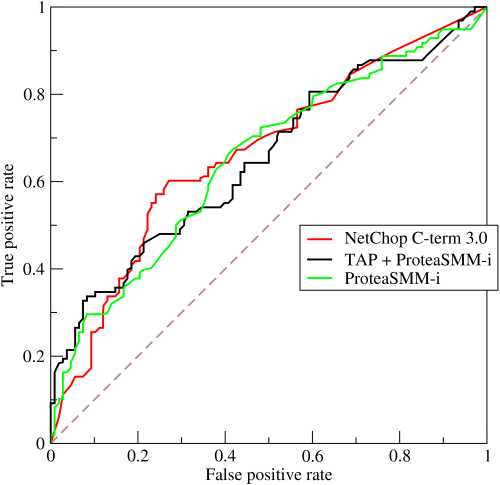
二、Precision、Recall、F1-score
Informedness = Sensitivity + Specificity - 1 |
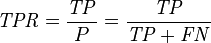

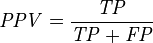

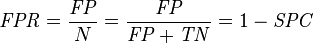
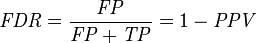
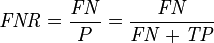


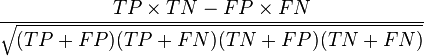
中文解释



以上是关于推荐系统之评估方法和评价指标PR、ROC、AUC的主要内容,如果未能解决你的问题,请参考以下文章
常用的评价指标:accuracy、precision、recall、f1-score、ROC-AUC、PR-AUC
评估指标:ROC,AUC,PrecisionRecallF1-score
查全率(Recall),查准率(Precision),灵敏性(Sensitivity),特异性(Specificity),F1,PR曲线,ROC,AUC的应用场景