K-means聚类分析案例---电信客户细分
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K-means聚类分析案例---电信客户细分相关的知识,希望对你有一定的参考价值。
参考技术A相关精彩专题链接: 数据成就更好的你
1.分析流程
2.目的
3.分析方法
1.描述统计
2.变量相关性分析
3.数据标准化
1.K-means算法中K值的确定
2.观察手肘法的输出结果
3.模型建立
R语言使用K-Means聚类可视化WiFi访问
原文链接:http://tecdat.cn/?p=6715
可视化已成为数据科学在电信行业中的关键应用。具体而言,电信分析高度依赖于地理空间数据的使用。
这是因为电信网络本身在地理上是分散的,并且对这种分散的分析可以产生关于网络结构,消费者需求和可用性的有价值的见解。
数据
为了说明这一点,使用k均值聚类算法来分析免费公共WiFi的地理数据。
具体地,k均值聚类算法用于基于与特定提供商相关联的纬度和经度数据来形成WiFi使用的集群。
从数据集本身,使用R提取纬度和经度数据:
#1
newyorkdf <-data.frame(纽约$ LAT,纽约$ LON)
这是一个数据片段:
确定群集的数量
现在,需要使用scree图确定簇的数量。
#2。确定群集的数量
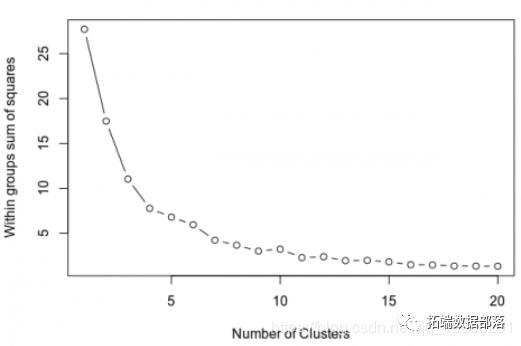
从上面可以看出,曲线在大约11个星团处平稳。因此,这是将在k-means模型中使用的聚类数。
K均值分析
K-Means分析本身是:
ggplot(newyorkdf,aes(x = newyork.LON,y = newyork.LAT,color = newyorkdf $ fit.cluster))+ geom_point()
在数据框newyorkdf中,显示纬度和经度数据以及群集标签:
> newyorkdfnewyork.LAT newyork.LON fit.cluster1 40.75573 -73.94458 12 40.75533 -73.94413 13 40.75575 -73.94517 14 40.75575 -73.94517 15 40.75575 -73.94517 16 40.75575 -73.94517 1.....80 40.84832 -73.82075 1181 40.84923 -73.82105 1182 40.84920 -73.82106 1183 40.85021 -73.82175 1184 40.85023 -73.82178 1185 40.86444 -73.89455 11
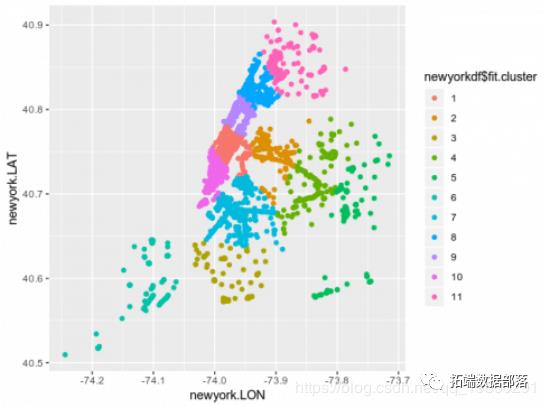
这个例子很有用,但理想的情况是将这些集群附加到纽约市本身的地图上。
地图可视化
为了生成纽约市的地图 ,如下所示。
gg += newyorkdf,aes(x = newyork.LON,y = newyork.LAT),color = newyorkdf $ fit.cluster,alpha = .5)+ ggtitle(“纽约公共WiFi”)
运行上述内容后,将生成NYC地图以及相关群集:
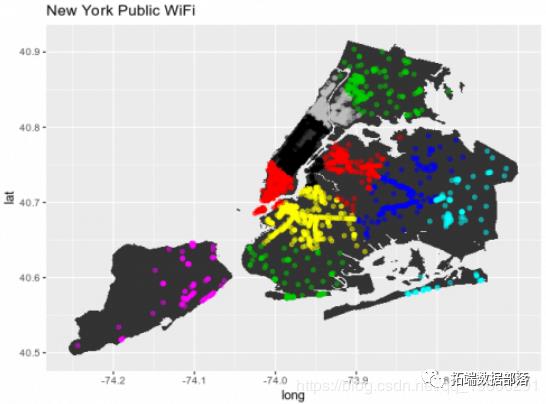
这种类型的聚类可以深入了解城市中WiFi网络的结构。例如,群集1中有650个单独的点,而群集6中存在100个点。
这表明由集群1标记的地理区域显示了大量的WiFi流量。另一方面,群集6中较低数量的连接指示低WiFi流量。
K-Means聚类本身并不能告诉我们为什么特定集群的流量高或低。但是,此聚类算法为进一步分析提供了一个很好的起点,并且可以更轻松地收集其他信息,以确定一个地理集群的流量密度可能高于另一个地理集群的原因。
结论
此示例演示了k-means聚类如何与地理数据一起使用,以便可视化整个WiFi接入点。此外,我们还看到了k-means聚类如何指示用于WiFi接入的高密度区域和低密度区域,以及可以从中提取关于人口,WiFi速度以及其他因素的潜在见解。
非常感谢您阅读本文,有任何问题请在下面留言!
点击标题查阅往期内容
更多内容,请点击左下角“阅读原文”查看


![]()
案例精选、技术干货 第一时间与您分享
长按二维码加关注
更多内容,请点击左下角“阅读原文”查看
以上是关于K-means聚类分析案例---电信客户细分的主要内容,如果未能解决你的问题,请参考以下文章