邮政研究基于K-means聚类算法的邮政金融客户细分(节选)
Posted 邮政研究
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了邮政研究基于K-means聚类算法的邮政金融客户细分(节选)相关的知识,希望对你有一定的参考价值。
当前邮政金融客户中,3.6%的客户占用80.5%的资产,7.6%的客户占用17%的资产,88.8%的客户占用2.5%的总资产。如果忽略不同资产类型带来的不同收益率,3.6%的客户为邮政代理金融贡献收入的80.5%.针对这80.5%的客户只有两个细分群体,即金卡客户和钻石客户,且该细分群体除资产级别之外,不带有任何关于客户个人喜好、行为等属性的分群,显然不利于维护客户关系。
广东邮政金融数据中心基于K-means聚类算法,按照客户的基础信息以及客户金融产品购买情况进行聚类,使同一个群内的客户具有最大相似性,以网点为单位输出当前网点的营销客户列表,并附有客户偏好的属性标签,营销人员可根据客户营销列表进行专业、定向的营销。
1 算法框架
根据当前的业务需求以及客户细分的过程,本文提出一个比较完整的适合广东邮政代理金融客户群体的细分模型,如图1所示。
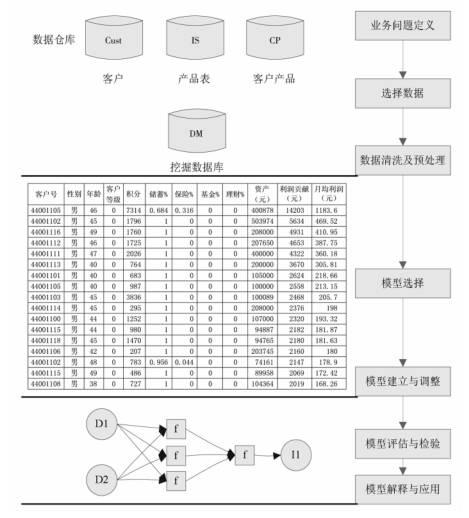
图1 邮政代理金融客户细分模型
客户群体细分过程主要包括:问题定义、数据选择、数据清洗及预处理、模型选择、模型建立及调整、模型评估与检验以及模型解释与应用。
2 数据预处理
本文以广州邮政某金融网点数据为例,涉及3张数据表:客户基础表、产品表以及客户产品关联表。客户基础表包含客户姓名、客户号、身份证号、年龄、性别、籍贯、应业状态、月收入、行业岗位、学历、单位性质、客户等级、客户分类、累计积分;产品表包含种类(储蓄、理财、基金、保险)、产品名称、明细、客户收益、企业收益;客户产品数据表包含月份、客户号、客户姓名、产品类型、产品名称、月末余额、月均余额。
针对以上3张基础数据表进行数据预处理,主要根据聚类的目标进行对应的数据处理工作,每个客户每月合并为一条数据,处理结果形成数据预处理表,包含月份、客户号、性别、年龄、客户等级、积分、储蓄资产百分比、基金资产百分比、保险资产百分比、理财资产百分比、客户总资产、利润贡献。
3 聚类算法的实现
根据抽取的特征利用数据聚类算法(K-means)对数据进行分析,计算每个客户之间的相似情况(距离),根据距离的大小将特征属性相近的客户划分为一个群体,将特征属性相差较大的客户划分为不同的群体,从而得到不同目标客户群。这些目标客户群(簇)具有共同的特征属性,通过客户群的划分,再结合客户群的共性特征进行数据分析,得到相应客户群体共性特征的数字化描述。
K-means算法是一种典型的分割聚类算法,由于算法的简单性以及实现的简便性,在数据挖掘中应用最为广泛。K-means算法首先随机或按照某种先验知识选择K个对象,每个对象初始地代表一个簇的平均值或中心。对于剩余的每个对象,根据它到各个簇中心的距离将其赋给最近的簇。然后重新计算每个簇的中心。这个过程不断重复,直至收敛。
本文采用聚类算法对上述经过预处理的客户数据进行聚类分析,主要是针对客户按照选定的聚类属性进行聚类,旨在将具有相似理财偏好的客户进行聚类分析。聚类算法的实现过程如下。
第一,选取K的取值(本文取值:12);
第二,选取初始质心点,作为聚类的簇心;
第三,读取每条记录,计算第二条记录到簇心的距离,并将其归于距离质心最近的簇,然后再重新更新簇心;
第四,重复步骤2,直至质心不再变化。
4 聚类结果
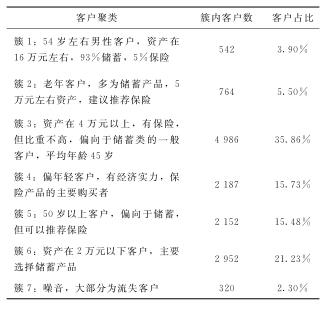
将该网点的客户数据进行聚类,最终收敛于以下结果,见表1。最终聚类生成12个簇,每个簇代表一类具有相似属性的客户,其质心代表这类客户的主要特征。分析聚类后的客户分类,将具有相似属性的簇进行合并,最终归并为7个簇,结果如表2所示。
表1 聚类结果表
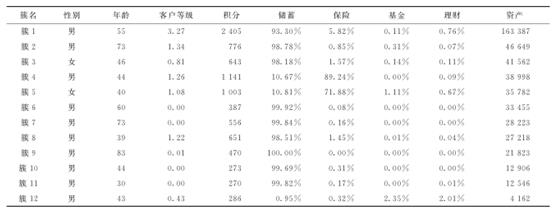
表2 聚类客户表
年龄是一个客户群体的首要特征,不同年龄阶段的客户理财偏好不同,从以上结果可以看出,一般55岁以上的客户选择定期理财,而40~55岁之间的客户,会选择保险和定期结合的方式。同时,资产是客户群体的第二个显著属性,资产在2万元以下的客户基本都选择活期产品,资产在5万元以上的客户会考虑定期、理财或保险产品。
针对簇1的客户,营销人员可以重点销售保险、理财产品,这部分属于高端客户,且年龄在54岁左右,注重自身的保障且具有一定的理财意识,是当前该网点基金理财产品的购买主力。
簇2属于老龄客户,相对于其他老龄客户来说,这部分属于高端老龄客户。他们的资产相对较多,若引导他们购买理财产品,分红型保险是最佳选择。
簇3属于理性的高端客户,可以引导其购买一些理财和保险产品,但营销难度相对较大。
簇4客户属于当前该网点保险产品的主要购买力,但从数据上分析,购买保险具有一定随机性,且从年龄结构上看偏年轻,主要分布在40~44岁。
簇5属于50岁以上老人群体,主要偏向于储蓄,但可以适当推荐保险。
簇6客户资产在2万元以下,主要集中在储蓄产品,可引导其投资理财,如基金定投。
簇7主要是流失客户。
针对以上七类客户,本文统计其客户区间分布(如图2所示),88.3%的客户主要分布在簇3~6,高端客户较少(簇1、2)。对网点日常营销来说,建议网点针对簇3~6推出特定的营销策略。在注重高端客户的同时,重点开展对网点主力客户的针对性营销。
图2 聚类客户分布图
5 聚类后客户维护方式
根据高贡献、高服务的客户贡献原则,将客户贡献的价值根据客户当月代理金融产品金额、种类与收益率相关联,计算出本月每位客户的贡献价值。本文选取簇6的部分客户进行结果输出,簇6的客户大多为老年客户,大部分资产都用来储蓄,营销人员可以有针对性地为这类客户推荐分红型保险,同时根据当前客户的利润贡献进行差异化营销,适度为利润贡献较大的客户提供更加全面的服务。
6 结论
本文针对广州市邮政某金融网点的客户进行分析,由于其数据具有分类不确定性,所以采用聚类算法,使一个类中的客户具有最大相似性,然后提取各类的属性,用于客户细分。本文针对客户购买的代理金融产品进行数据预处理,然后采用Kmeans聚类算法对客户进行分群,根据每个群中客户利润贡献额进行排序,给出每个群内的客户维护列表,并以利润贡献标记维护次序。
(中国邮政集团公司广东省信息技术局 滕毅 房戈)
以上是关于邮政研究基于K-means聚类算法的邮政金融客户细分(节选)的主要内容,如果未能解决你的问题,请参考以下文章