计算机视觉中的注意力机制研究
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉中的注意力机制研究相关的知识,希望对你有一定的参考价值。
参考技术A 写在前面的话:本文来自于本人的一次课程作业综述,当时还是写了很久的,不想交上去就完了,所以发上来留个纪念。将注意力机制用在计算机视觉任务上,可以有效捕捉图片中有用的区域,从而提升整体网络性能。计算机视觉领域的注意力机制主要分为两类:(1) self-attention;(2) scale attention。这两类注意力从不同的角度进行图片内容理。本文将分别就这两种注意力机制进行说明,并列举相关的文献。
注意力是人类大脑固有的一种信号处理机制。人类大脑通过快速从视觉信号中选择出需要重点关注的区域,也就是通常所说的注意力焦点,然后重点处理这些区域的细节信息。通过注意力机制可以利用有限的大脑资源从大量的信息中筛选出有价值的信息。注意力机制最初被用在深度学习任务上是在机器语言翻译领域,将源语言翻译成目标语言,目标语言中的词并非与源语言的所有词都同等相关,而是仅与特定的几个词有相关性。因此,注意力机制可以将这个词的注意力分配到这些最相关的词上。之后,[1]中提出自注意力机制 (self-attention),并将其用于Transformer模块中,极大提升了翻译模型的精度和并行性。与传统的注意力机制不同,self-attention的查询(query)和键(key)属于同一个域,计算的是同一条语句(或同一张图片)中不同位置之间的注意力分配,从而提取该语句(或图片)的特征。
[2]首先将self-attention用于视觉任务中,提出了non-local network,来捕获图片(或视频)中的长程依赖(long-range dependency)。Self-attention机制在视觉任务,如语义分割[3],生成对抗网络[4]中取得了巨大的成功。它解决了卷积神经网络的局部视野域问题,使得每个位置都可以获得全局的视野域。不过,由于在视觉任务中,像素数极多,利用所有位置来计算每个位置的attention会导致巨大的计算和显存开销;另一方面,由于self-attention简单将图像当成一个序列进行处理,没有考虑不同位置之间的相对位置关系,使得所得到的attention丧失了图像的结构信息。之后对于self-attention的一个改进方向就是,在self-attention中加入相对位置信息或绝对位置信息编码。
除了self-attention,视觉任务中另一类注意力机制为scale attention。与self-attention不同,scale attention基于每个位置本身的响应。就分类任务而言,每个位置的响应越大,则其对于最终的分类结果影响越大,那么这个位置本身的重要性就越强。根据响应大小有选择地对特征图进行强化或抑制,就可以在空间(或其他维度)上达到分配attention的目的。[5]所提出的SENet,就相当于channel-wise的attention。类似的还有GENet[6],CBAM[7]等,GENet将SENet中的channel-wise attention扩展到了spatial上,CBAM设计了串行的两个模块,分别进行channel-wise attention和spatial-wise attention的计算。另一篇工作residual attention network[8]也属于这一类attention,与SENet系列不同之处在于,本文采用bottom-up top-down形式得到spatial attention,再将其以残差的形式作用回原来的特征。这一类注意力机制仅仅基于图像中每个位置本身,对显著区域进行增强,非显著区域进行抑制,比self-attention机制更接近与人类视觉系统的注意力机制。
普通卷积将特征图的每个位置作为中心点,对该位置及其周围的位置进行加权求和,得到新的特征图上该位置对应的滤波结果,对于边缘,必要时可以用0进行填充。这一操作可以有效提取图片的局部信息。随着网络加深,卷积层不断堆叠,每个位置的视野域也越来越大,网络提取到的特征也逐渐由一些low-level的特征,如颜色、纹理,转变到一些high-level的结构信息。但是,简单通过加深网络来获取全局视野域,所带来的计算开销是很大的,并且,更深的网络会带来更大的优化难度。
Self-attention操作[2]可以有效地捕获不同位置之间的long-range dependency,每个位置的特征都由所有位置的加权求和得到,这里的权重就是attention weight。由此,每个位置都可以获取全局的视野域,并且不会造成特征图的退化(分辨率降低),这对于一些密集的预测任务,如语义分割、目标检测等,具有很大的优势。
图1展示了self-attention的网络结构。给定输入X,将两个1x1卷积分别作用于X上,得到的两个特征利用f(⋅)得到相关性矩阵,图中展示的f(⋅)为矩阵乘法。最后将相关性矩阵作用在原特征经过1x1卷积变换后的特征上。
公式(1)展示了第i个位置的相应的计算方法,其中f(⋅)为相关性函数,g(⋅)为变换函数,x_i为输入第i个位置的特征,y_i为第i个位置的输出特征,C(x)为归一化因子,一般采用总位置的个数。
由于self-attention可以有效捕获图片(或视频)中的长距离依赖,从而在不影响特征分辨率的同时获取全局的视野域,在视觉任务上引入self-attention,可以带来较大的性能提升。
论文[2]将self-attention用在视频动作识别任务上,如图2,对于视频中动作的识别,可能会跨越多帧,需要建立多帧视频之间的联系,self-attention的这种长距离依赖的特征就能有效建立多帧不同位置之间的联系。
论文[2]将self-attention用在分割任务上。由于孤立预测每个位置的类别很容易导致分错,分割任务需要结合每个位置的上下文对该位置进行分类。文章定义了所谓物体上下文(object context),即每个位置所属于的类别构成的集合,即为这个位置所属于的object context。 Object context是由不同位置的特征相似度来定义的,也就是self-attention过程中的相似度矩阵,将相似度矩阵与原特征进行相乘,即可将object context作用于该特征图。由此,文章提出了Object Context Network(OCNet),如图3。其中,base-OC为基本的self-attention模块,pyramid-OC和ASP-OC分别将self-attention与PSP模块和ASPP模块结合,在提取object context的同时,利用不同倍率的pooling操作或不同ratio的dilated convolution获取多尺度的特征,最大程度的利用context信息对原图进行分割。不过,本文虽然提出object context为每个像素及所有其他与其属于同一类的像素构成的集合,在实际操作的时候却并不是这样计算每个位置的object context的,特征上的相似性并不一定代表属于同一位置。因此,用object context来给self-attention新的解释,在说服力上还是存在一定问题的。
Scale attention是另一种注意力机制,与self-attention不同,scale attention是只基于key context的,对图像中的显著性区域进行增强,其他区域相应的进行抑制,从而使得输出的特征具有更强的区分性。这一类注意力机制的代表工作包括,residual attention network[8],squeeze-and-excite network[5],gather-and-excite network[6]以及CBAM[7]。
[8]提出,在分类网络中,网络深层比浅层更关注于被分类的物体,也就是图片的主体内容,这是因为,深层网络具有更大的视野域,可以看到更广的范围;而浅层网络只能看到每个位置及其邻域。因此,如果将网络较深层的信息作为一种mask,作用在较浅层的特征上,就能更好的增强浅层特征中对于最终分类结果有帮助的特征,抑制不相关的特征。如图5所示,将attention作为mask作用在原来特征上,得到的输出就会更加集中在对分类有帮助的区域上。
因此,文章提出一种bottom-up top-down的前向传播方法来得到图片的attention map,并且将其作用在原来的特征上,使得输出的特征有更强的区分度。图6展示了这种attention的计算方式。由于更大的视野域可以看到更多的内容,从而获得更多的attention信息,因此,作者设计了一条支路,通过快速下采样和上采样来提前获得更大的视野域,将输出的特征进行归一化后作用在原有的特征上,将作用后的特征以残差的形式加到原来的特征上,就完成了一次对原有特征的注意力增强。文章还提出了一个堆叠的网络结构,即residual attention network,中间多次采用这种attention模块进行快速下采样和上采样。
这篇文章在视觉领域开前向传播的注意力机制的先河,之后的注意力机制都是采用这种前向传播过程中得到的attention进行增强,并且一般为了优化方便,都会以残差的方式进行。
Squeeze-and-excite是另一类scale attention。与residual attention不同,squeeze-and-excite通过global pooling来获得全局的视野域,并将其作为一种指导的信息,也就是attention信息,作用到原来的特征上。
[5]提出了squeeze-and-excite network(SENet),提出了channel-wise的scale attention。特征图的每个通道对应一种滤波器的滤波结果,即图片的某种特定模式的特征。对于最终的分类结果,这些模式的重要性是不同的,有些模式更重要,因此其全局的响应更大;有些模式不相关,其全局的响应较小。通过对不同通道的特征根据其全局响应值,进行响应的增强或抑制,就可以起到在channel上进行注意力分配的作用。其网络结构如图7所示,首先对输入特征进行global pooling,即为squeeze阶段,对得到的特征进行线性变换,即为excite阶段,最后将变换后的向量通过广播,乘到原来的特征图上,就完成了对不同通道的增强或抑制。SENet在2017年的ImageNet2017的分类比赛上获得了冠军,比之前的工作有了较大的性能提升。
[6]进一步探索了squeeze-and-excite在更细的粒度上的表现,提出了gather-excite操作。SENet将每个通道的特征图通过global pooling得到一个值,本文采用了不同步长的pooling(2x,4x,8x,global),然后利用上采样将pooling后的特征插值恢复到原来大小,最后作用在原来特征图上,具体操作如图8所示。不过,实验结果显示,global pooling的性能最好,将特征区间划分得更细致虽然增加了参数,但是反而会带来性能的下降。
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[2] Wang X, Girshick R, Gupta A, et al. Non-local neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7794-7803.
[3] Yuan Y, Wang J. Ocnet: Object context network for scene parsing[J]. arXiv preprint arXiv:1809.00916, 2018.
[4] Zhang H, Goodfellow I, Metaxas D, et al. Self-attention generative adversarial networks[J]. arXiv preprint arXiv:1805.08318, 2018.
[5] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[6] Hu J, Shen L, Albanie S, et al. Gather-Excite: Exploiting feature context in convolutional neural networks[C]//Advances in Neural Information Processing Systems. 2018: 9401-9411.
[7] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
[8] Wang F, Jiang M, Qian C, et al. Residual attention network for image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3156-3164.
清华&南开出品最新视觉注意力机制Attention综述
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :量子位
清华大学计图团队和南开大学程明明教授团队、卡迪夫大学Ralph R. Martin教授合作,在ArXiv上发布关于计算机视觉中的注意力机制的综述文章。该综述系统地介绍了注意力机制在计算机视觉领域中相关工作
清华计图胡事民团队的这篇注意力机制的综述火了!
在上周的arXiv上,这是最热的一篇论文:
推特以及GitHub上也有不低的热度:
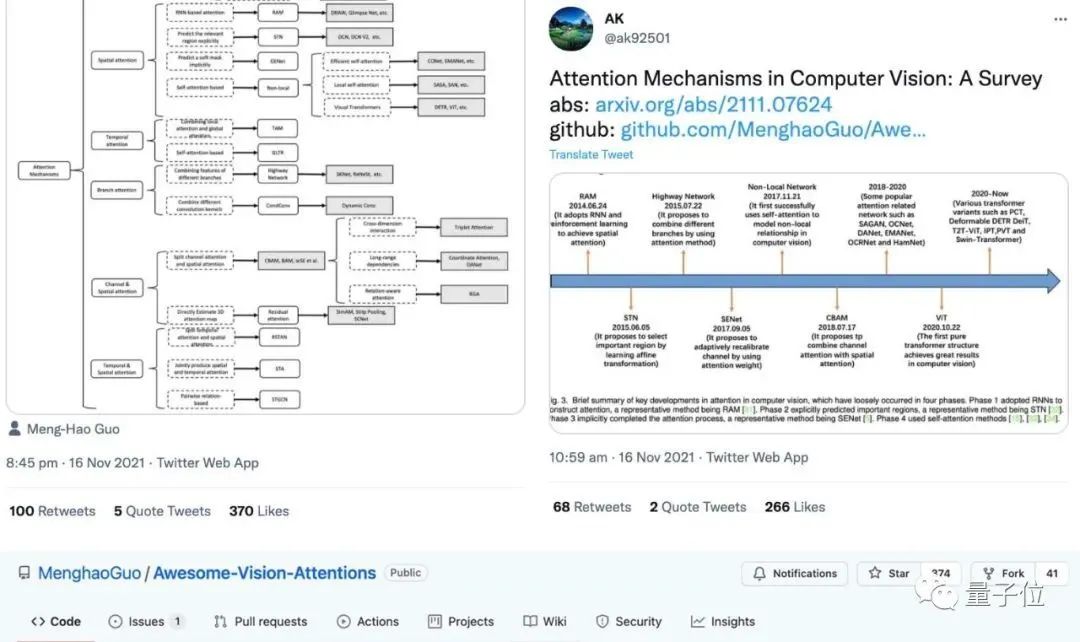
而这篇论文引用近200篇内容,对计算机视觉领域中的各种注意力机制进行了全面回顾。
在大量调查之后,论文将注意力机制分为多个类别,GitHub还给出了各类别下提到内容的PDF下载文件:

现在,就来一起看看这篇论文。
文章主要内容
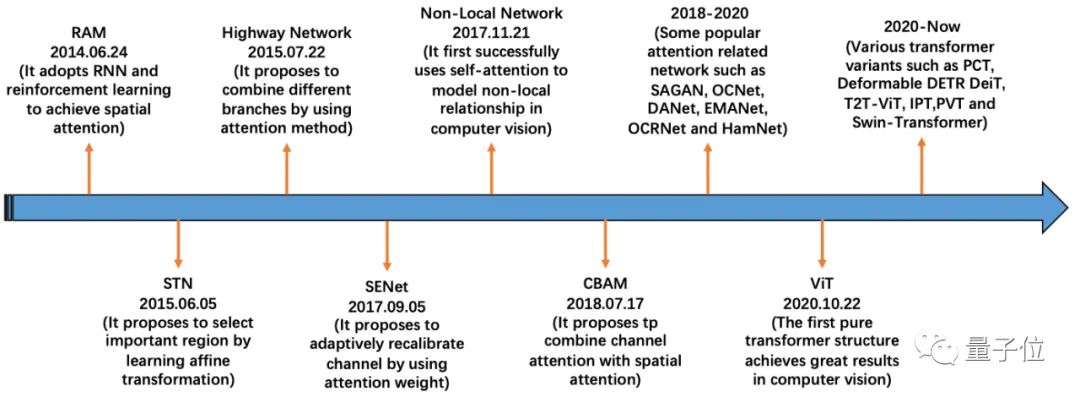
论文首先将基于注意力的模型在计算机视觉领域中的发展历程大致归为了四个阶段:
将深度神经网络与注意力机制相结合,代表性方法为RAM
明确预测判别性输入特征,代表性方法为STN
隐性且自适应地预测潜在的关键特征,代表方法为SENet
自注意力机制
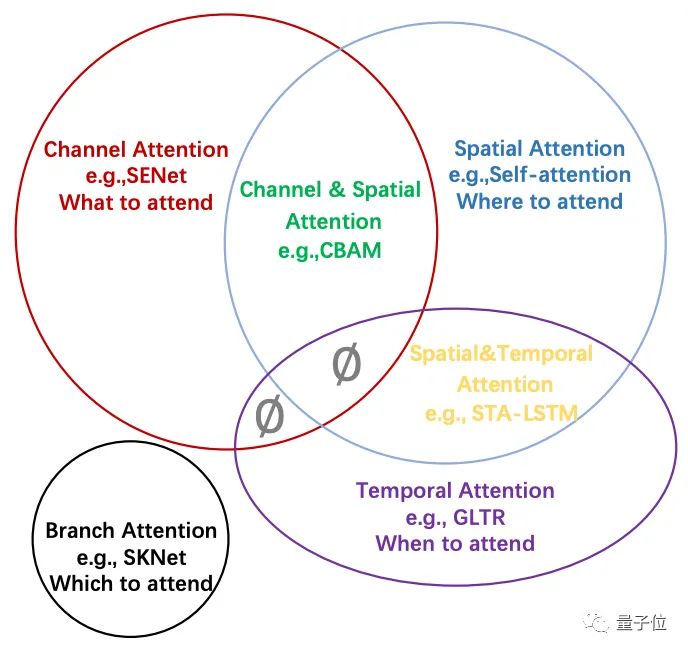
同时,注意力机制也被分为了通道注意、空间注意、时间注意、分支注意,以及两个混合类别:
针对不同类别,研究团队给出了其代表性方法和发展背景:
通道注意力(Channel Attention)
在深度神经网络中,不同特征图的不同通道常代表不同对象。
而通道注意力作为一个对象选择过程,可以自适应地重新校准每个通道的权重,从而决定关注什么。
因此,按照类别和出版日期将代表性通道关注机制进行分类,应用范围有分类(Cls)、语义分割(SSeg)、实例分割(ISeg)、风格转换(ST)、动作识别(Action)。
其中,(A)代表Channel-wise product,(I)强调重要通道,(II)捕捉全局信息。
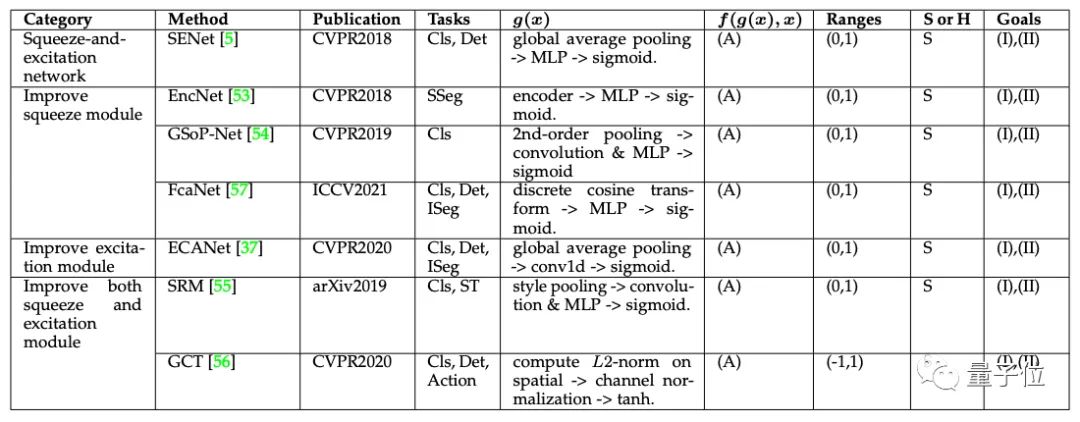
空间注意力(Spatial Attention)
空间注意力可以被看作是一种自适应的空间区域选择机制。
其应用范围比通道注意力多出了精细分类(FGCls)和图像字幕(ICap)。
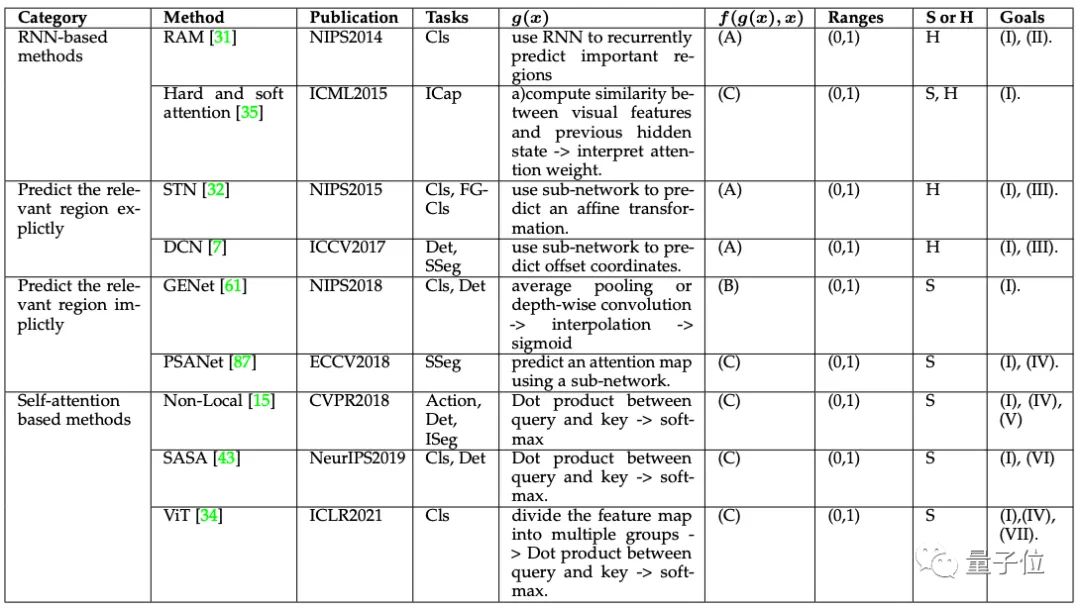
时间注意力(Temporal Attention)
时间注意力可以被看作是一种动态的时间选择机制,决定了何时进行注意,因此通常用于视频处理。

分支注意力(Branch Attention)
分支注意可以被看作是一种动态的分支选择机制,通过多分支结构决定去注意什么。

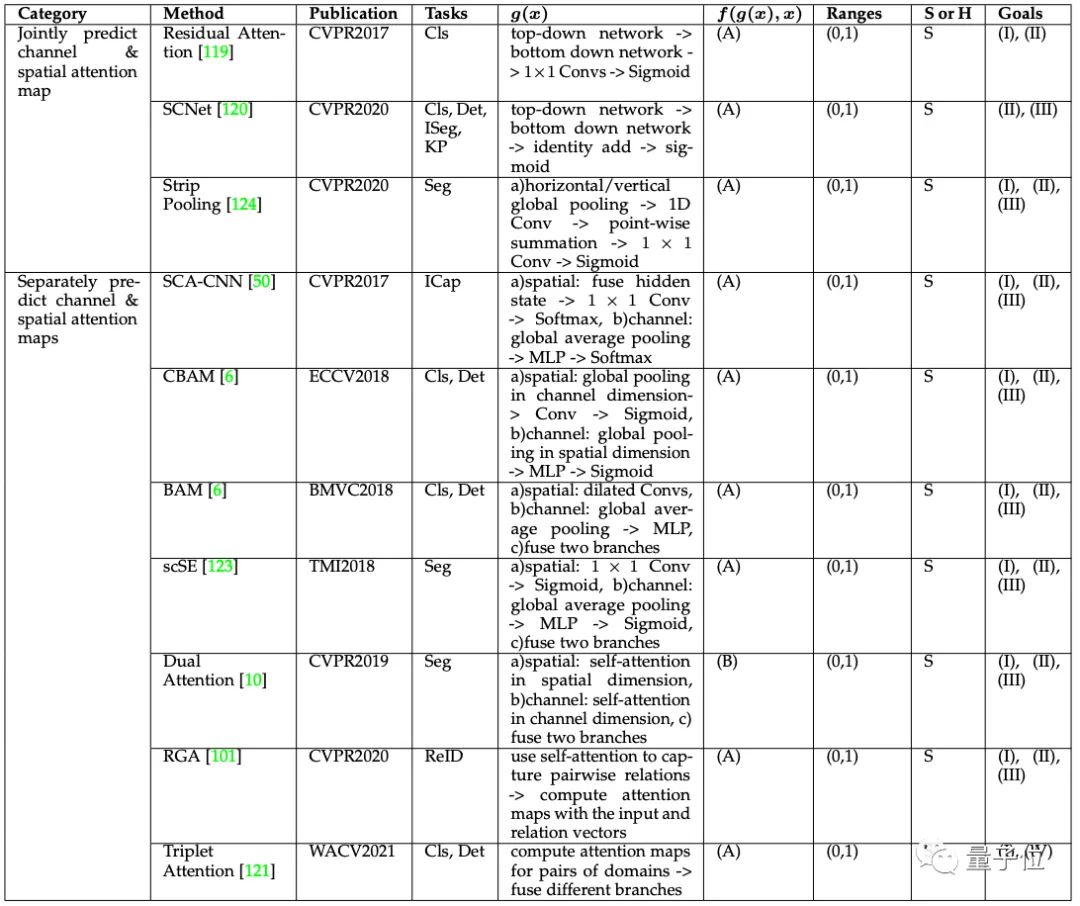
通道空间注意力(Channel & Spatial Attention)
通道和空间结合的注意力机制可以自适应地选择重要的对象和区域,由残差注意力(Residual Attention)网络开创了这一内容。
在残差注意力之后,为了有效利用全局信息,后来的工作又相继引入全局平均池化(Global Average Pooling),引入自注意力机制等内容。
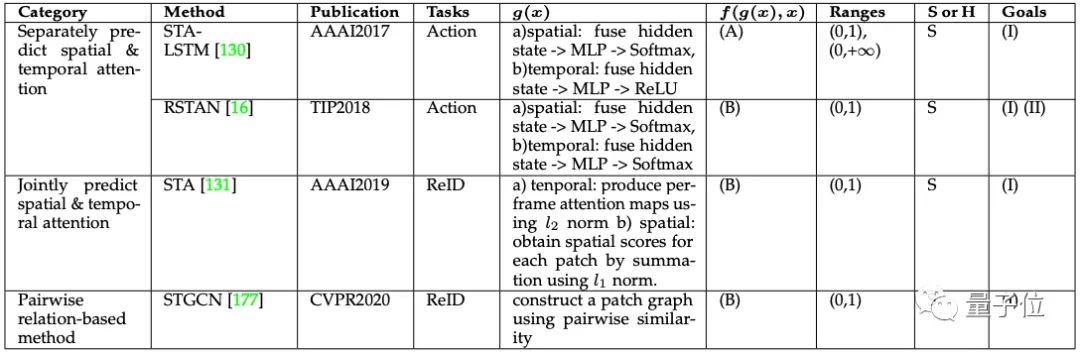
时空注意力(Spatial & Temporal Attention)
时空注意力机制可以自适应地选择重要区域和关键帧。
最后,作者也提出了注意力机制在未来的一些研究方向:
探索注意力机制的必要和充分条件
是否可以有一个通用的注意块,可以根据具体的任务在各类注意力机制之间进行选择
开发可定性和可解释的注意力模型
注意力机制可以产生稀疏的激活,这促使我们去探索哪种架构可以更好地模拟人类的视觉系统
进一步探索基于注意力的预训练模型
为注意力模型研究新的优化方法
找到简单、高效、有效的基于注意力的模型,使其可以广泛部署
关于作者
这篇论文来自清华大学计算机系胡事民团队。
胡事民为清华大学计算机系教授,教育部长江学者特聘教授,曾经和现任IEEE、Elsevier、Springer等多个期刊的主编、副主编和编委。同时,他也是清华“计图”框架团队的负责人,这是首个由中国高校开源的深度学习框架。

文章一作为胡事民教授的博士生国孟昊,现就读于清华大学计算机系,也是清华计图团队的一员。

各类资源汇总链接:
https://github.com/MenghaoGuo/Awesome-Vision-Attentions
论文地址:
https://arXiv.org/abs/2111.07624
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于计算机视觉中的注意力机制研究的主要内容,如果未能解决你的问题,请参考以下文章