四十二:数据库之SQLAlchemy之数据查询懒加载技术
Posted 向前走。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了四十二:数据库之SQLAlchemy之数据查询懒加载技术相关的知识,希望对你有一定的参考价值。
懒加载
在一对多,或者多对多的时候,如果要获取多的这一部分的数据的时候,通过一个relationship定义好对应关系就可以全部获取,此时获取到的数据是list,但是有时候不想获取全部数据,如果要进行数据筛选就需要遍历筛选,就比较麻烦,可以从查询返回值里面入手,比如在获取到的数据里面还要加个过滤条件,则需要在relationship中加一个参数:lazy=\'dynamic\',以后通过relationship定义的对应关系获取到的就不是一个列表,而是一个AppenderQuery对象,这种对象既可以添加新数据,也可以跟Query对象一样对数据进行二次过滤
准备工作
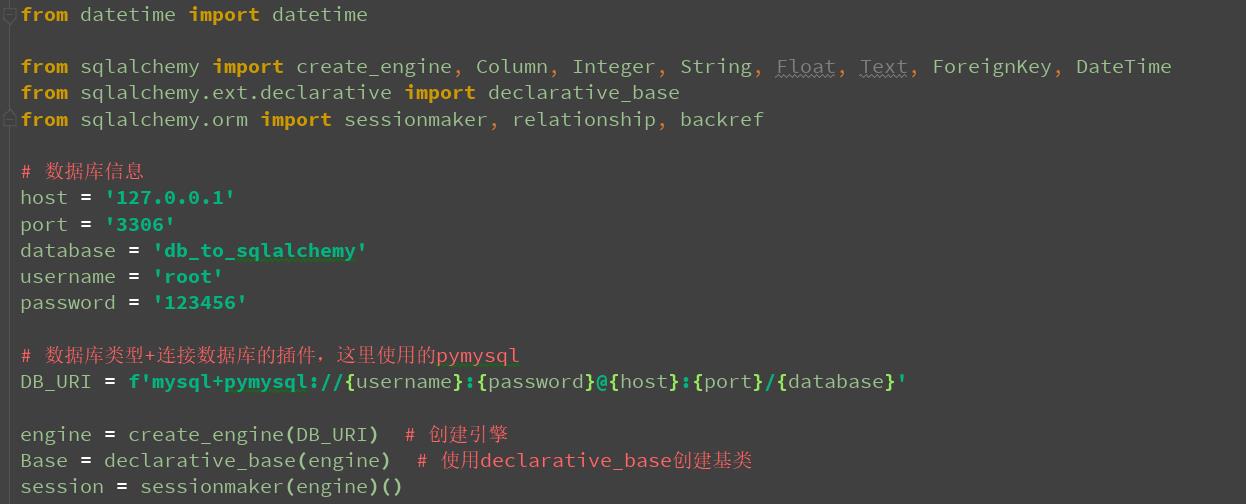

from datetime import datetime
from sqlalchemy import create_engine, Column, Integer, String, Float, Text, ForeignKey, DateTime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship, backref
# 数据库信息
host = \'127.0.0.1\'
port = \'3306\'
database = \'db_to_sqlalchemy\'
username = \'root\'
password = \'123456\'
# 数据库类型+连接数据库的插件,这里使用的pymysql
DB_URI = f\'mysql+pymysql://{username}:{password}@{host}:{port}/{database}\'
engine = create_engine(DB_URI) # 创建引擎
Base = declarative_base(engine) # 使用declarative_base创建基类
session = sessionmaker(engine)()
class User(Base):
__tablename__ = \'user\'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
class Article(Base):
__tablename__ = \'article\'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
create_time = Column(DateTime, nullable=False, default=datetime.now)
uid = Column(Integer, ForeignKey(\'user.id\'))
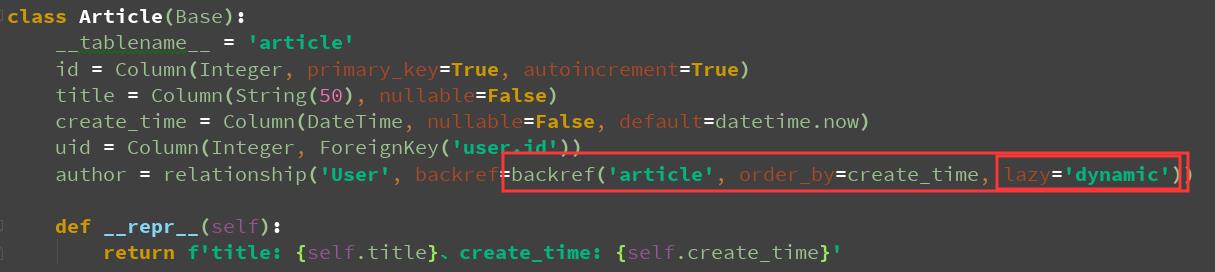
author = relationship(\'User\', backref=backref(\'article\', order_by=create_time))
def __repr__(self):
return f\'title: {self.title}、create_time: {self.create_time}\'
Base.metadata.drop_all() # 删除所有表
Base.metadata.create_all() # 创建表
user = User(username=\'aaa\')
for x in range(100):
article = Article(title=f\'title{x}\')
article.author = user
session.add(article)
session.commit()

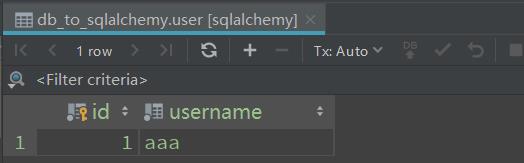
默认返回的是list对象
指定懒加载属性lazy=\'dynamic\'
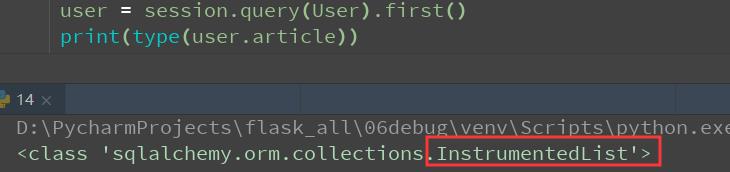
返回的是AppendQuery对象

导入看源码


以上可以看出,返回的对象会有AppendQuery和Query的全部特性,即可以使用Query的方法进行数据二次过滤
如,查user表第一条数据对应在article表里面所有数据的id大于95的数据

有AppendQuery特性,也就是说可以添加数据

lazy支持的参数
首先,默认的是select

支持的参数
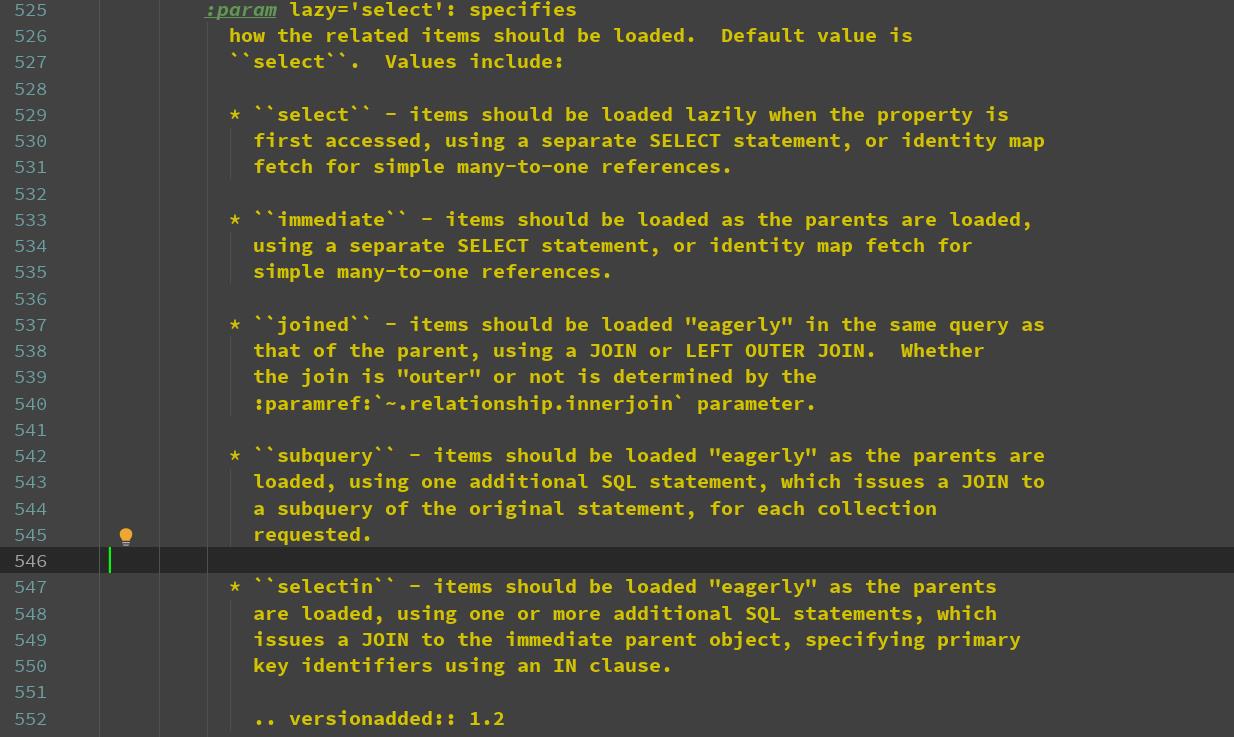
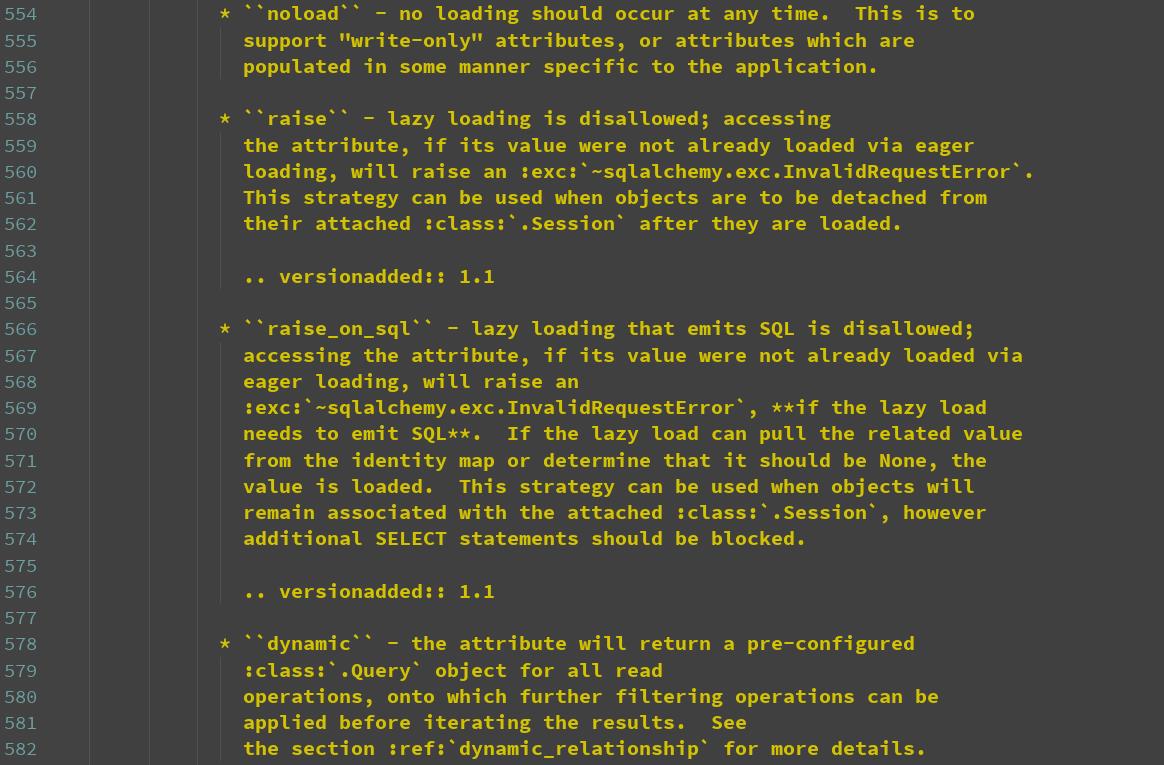

select:如果没有调relationship对应的字段,则不会获取多的这一边的数据,一旦调用此属性,则获取所有对应的数据,返回列表
immediate:不管是否调用relationship对应的字段,都会则获取所有对应的数据,返回列表
joined:将relationship对应的字段查找回来的数据,通过join的方式加到主表数据中
subquery:子查询的方式
以上是关于四十二:数据库之SQLAlchemy之数据查询懒加载技术的主要内容,如果未能解决你的问题,请参考以下文章
四十九:数据库之Flask-SQLAlchemy下alembic的配置
四十三:数据库之SQLAlchemy之group_by和having子句