HDFS简介:不用HDFS我们如何存储大规模数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS简介:不用HDFS我们如何存储大规模数据相关的知识,希望对你有一定的参考价值。
参考技术A 大数据技术主要是要解决大规模数据的计算处理问题,但是我们要想对数据进行计算,首先要解决的其实是大规模数据的存储问题。如果一个文件的大小超过了一张磁盘的大小,你该如何存储? 单机时代,主要的解决方案是 RAID ;分布式时代,主要解决方案是 分布式文件系统 。
其实不论是在 RAID 还是 分布式文件系统 ,大规模数据存储都需要解决几个核心问题,这些问题都是什么呢?总结一下,主要有以下三个方面。
1. 数据存储容量的问题。 既然大数据要解决的是数以 PB 计的数据计算问题,而一般的服务器磁盘容量通常 1~2TB,那么如何存储这么大规模的数据呢?
2. 数据读写速度的问题。 一般磁盘的连续读写速度为几十 MB,以这样的速度,几十 PB 的数据恐怕要读写到天荒地老。
3. 数据可靠性的问题。 磁盘大约是计算机设备中最易损坏的硬件了,通常情况一块磁盘使用寿命大概是一年,如果磁盘损坏了,数据怎么办?
RAID(独立磁盘冗余阵列)技术是将多块普通磁盘组成一个阵列,共同对外提供服务。主要是为了改善磁盘的存储容量、读写速度,增强磁盘的可用性和容错能力。目前服务器级别的计算机都支持插入多块磁盘,通过使用 RAID 技术,实现数据在多块磁盘上的并发读写和数据备份。
常用 RAID 技术有图中下面这几种,RAID0,RAID1,RAID10,RAID5, RAID6。
首先,我们先假设服务器有 N 块磁盘。
RAID 0 是数据在从内存缓冲区写入磁盘时,根据磁盘数量将数据分成 N 份,这些数据同时并发写入 N 块磁盘,使得数据整体写入速度是一块磁盘的 N 倍;读取的时候也一样,因此 RAID 0 具有极快的数据读写速度。但是 RAID 0 不做数据备份,N 块磁盘中只要有一块损坏,数据完整性就被破坏,其他磁盘的数据也都无法使用了。
RAID 1 是数据在写入磁盘时,将一份数据同时写入两块磁盘,这样任何一块磁盘损坏都不会导致数据丢失,插入一块新磁盘就可以通过复制数据的方式自动修复,具有极高的可靠性。
结合 RAID 0 和 RAID 1 两种方案构成了 RAID 10 ,它是将所有磁盘 N 平均分成两份,数据同时在两份磁盘写入,相当于 RAID 1;但是平分成两份,在每一份磁盘(也就是 N/2 块磁盘)里面,利用 RAID 0 技术并发读写,这样既提高可靠性又改善性能。不过 RAID 10 的磁盘利用率较低,有一半的磁盘用来写备份数据。
一般情况下,一台服务器上很少出现同时损坏两块磁盘的情况,在只损坏一块磁盘的情况下,如果能利用其他磁盘的数据恢复损坏磁盘的数据,这样在保证可靠性和性能的同时,磁盘利用率也得到大幅提升。
顺着这个思路, RAID 3 可以在数据写入磁盘的时候,将数据分成 N-1 份,并发写入 N-1 块磁盘,并在第 N 块磁盘记录校验数据,这样任何一块磁盘损坏(包括校验数据磁盘),都可以利用其他 N-1 块磁盘的数据修复。但是在数据修改较多的场景中,任何磁盘数据的修改,都会导致第 N 块磁盘重写校验数据。频繁写入的后果是第 N 块磁盘比其他磁盘更容易损坏,需要频繁更换,所以 RAID 3 很少在实践中使用,因此在上面图中也就没有单独列出。
相比 RAID 3, RAID 5 是使用更多的方案。RAID 5 和 RAID 3 很相似,但是校验数据不是写入第 N 块磁盘,而是螺旋式地写入所有磁盘中。这样校验数据的修改也被平均到所有磁盘上,避免 RAID 3 频繁写坏一块磁盘的情况。
如果数据需要很高的可靠性,在出现同时损坏两块磁盘的情况下,仍然需要修复数据,这时候可以使用 RAID 6。
RAID 6 和 RAID 5 类似 , 但是数据只写入 N-2 块磁盘,并螺旋式地在两块磁盘中写入校验信息(使用不同算法生成)。
从下面表格中你可以看到在相同磁盘数目(N)的情况下,各种 RAID 技术的比较。
现在我来总结一下,看看 RAID 是如何解决我一开始提出的,关于存储的三个关键问题。
1. 数据存储容量的问题。 RAID 使用了 N 块磁盘构成一个存储阵列,如果使用 RAID 5,数据就可以存储在 N-1 块磁盘上,这样将存储空间扩大了 N-1 倍。
2. 数据读写速度的问题。 RAID 根据可以使用的磁盘数量,将待写入的数据分成多片,并发同时向多块磁盘进行写入,显然写入的速度可以得到明显提高;同理,读取速度也可以得到明显提高。不过,需要注意的是,由于传统机械磁盘的访问延迟主要来自于寻址时间,数据真正进行读写的时间可能只占据整个数据访问时间的一小部分,所以数据分片后对 N 块磁盘进行并发读写操作并不能将访问速度提高 N 倍。
3. 数据可靠性的问题。 使用 RAID 10、RAID 5 或者 RAID 6 方案的时候,由于数据有冗余存储,或者存储校验信息,所以当某块磁盘损坏的时候,可以通过其他磁盘上的数据和校验数据将丢失磁盘上的数据还原。
RAID 可以看作是一种垂直伸缩,一台计算机集成更多的磁盘实现数据更大规模、更安全可靠的存储以及更快的访问速度。而 HDFS 则是水平伸缩,通过添加更多的服务器实现数据更大、更快、更安全存储与访问。
RAID 技术只是在单台服务器的多块磁盘上组成阵列,大数据需要更大规模的存储空间和更快的访问速度。将 RAID 思想原理应用到分布式服务器集群上,就形成了 Hadoop 分布式文件系统 HDFS 的架构思想。
HDFS跨外部存储系统的多层级存储
前言
目前大数据和云计算是当下讨论非常火热的2个词,笔者也非常相信在未来的时间内,以Hadoop系统生态圈为代表的大数据工具,将会被更多的企业所使用。在一些更大规模的公司,已经将大数据与云联系在了一起了,举个例子,我们将数据存储在HDFS内,然后在定期同步到云上,相当于云端存储的数据是一个back store。这样做的一个好处是防止本地集群的数据遭到意外的破坏或丢失,至少在云端我们还有备份。或者有另外的一些做法是,我们通过一层适配操作,将用户写入集群的数据直接就写到了远端的云上,但是对于用户而言它是无感知的。目前Hadoop系统中有这个方面的工程,比如hadoop-tools父工程下的hadoop-aws和hadoop-aliyun,分别针对的云服务就是亚马逊的S3和阿里云的OSS服务。面对此类的使用场景,社区在HDFS-9806提出了跨外部存储系统的多层级存储设计。本文笔者就来简单聊聊此话题。如果我们想在HDFS内部支持外部存储介质的读写,我们可以怎么实现呢?
HDFS跨外部存储系统的结构概述
如果HDFS支持了跨外部系统的存储,也就是说,我们能够通过HDFS提供的API将数据写到外部的存储系统中,它可能是一个云上的存储服务,又或者说是一个简单的k-v存储系统。但是不管目标存储系统的存储形如何,它在HDFS内部的命名空间一定是全局一致的,用户还是通过在某个路径下去读写文件。只是这些文件到底是HDFS集群内的数据还是说是外部存储系统内的。所以这里会有一个映射的概念,这点非常类似于笔者之前提过的Hadoop的ViewFS特性。这相当于在HDFS全局的命名空间树内,绝大部分是系统自身路径,而个别目录是挂载到外部的路径上的。如图所示。

HDFS跨外部存储系统命名空间映射关系
这就好比在一台机器上,绝大部分目录都是DISK磁盘类型的,但我们可以挂载一些目录到SSD盘上。当我们想将数据存储到SSD类型的盘上时,我们直接将数据写入与之对应的目录下即可。
HDFS跨文件系统存储的数据通信
基于前面部分的种种假设,我们能够以何种的方式去实现数据跨外部存储系统的读写呢?数据的整体过程与原来的方式大体相同,但是DataNode需要额外执行与远端存储系统进行数据读写的操作。因为很显然,外部存储系统的数据当然不会存在DataNode本地节点上。但是在逻辑上,这些外部存储的数据是属于此节点的。当用户想要从远端的存储系统上读数据时,NameNode还是会寻找这样一批在“逻辑上”拥有此数据的DataNode。下图是HDFS内部跨存储系统通信的整体架构设计。
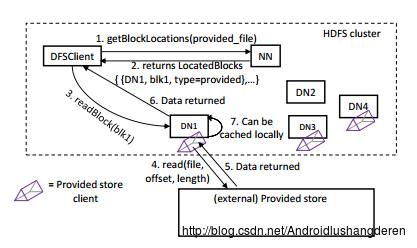
HDFS跨外部存储系统通信流程图
HDFS跨文件系统存储的细节设计
前面两小节笔者主要阐述了HDFS跨文件系认存储的比较宏观上的设计,下面来聊聊几个比较细的点,有哪些细节需要我们马上需要考虑的呢?
文件块的映射
外部存储系统有着各自维护的文件信息结构,这个本身与HDFS自身内部的一定有所不同,所以这里我们需要对HDFS文件块到外部存储文件做一个映射。而且这个映射图还要能够更新,因为外部存储的文件信息是会可能发生变化的。
DataNode新StorageType的引入
之前笔者也已经提到过,我们要让DataNode”逻辑上”拥有此块,但是其本身是不存储其物理数据的,而目前DataNode现有的目录StorageType都是完全物理存储在节点本地的,所以我们需要定义一个新的StorageType,比如说PROVIDED,来表明此标签路径下的数据为远端的存储路径。而一旦引入这个新的StorageType的话,现有的FSVolume等类必须做一定的调整,最好的方式是定义一个专门继承类来实现基础的接口。
安全问题
在大多数情况下,安全问题都是需要引起大家重视的问题,更何况是现在涉及到外部存储通信的情况。针对这点,在HDFS社区的设计文档中,提出了以下2大方向:
- 基于授权的认证方式。DataNode在于外部存储服务通信的时候,需要提供凭证(比如说token),然后才能允许通信。
- 利用Proxy代理关系来实现通信操作。
归纳地来说,不管使用上述的哪种方式,我们最终要确保的一点是HDFS自身能够有足够的权限来读写外部的存储系统,可以是HDFS内部统一维护的一个身份。
如果HDFS最后真的实现了支持跨文件系统的多层级存储,那么对于用户而言,无疑是多了更多的存储策略的选择。比如说,我们完全可以用更高密度的外部存储方式来存储集群中的冷数据。尽管说目前HDFS已经定义了ARCHIVE的StorageType来针对此类数据的存储,但是这类数据还是会保留在NameNode的命名空间内并被NameNode所管理。如果说我们可以完全将此数据移到外部的存储中,那无疑将会是更优的选择。
参考资料
[1].Allow HDFS block replicas to be provided by an external storage system, https://issues.apache.org/jira/browse/HDFS-9806.
以上是关于HDFS简介:不用HDFS我们如何存储大规模数据的主要内容,如果未能解决你的问题,请参考以下文章