HDFS知识点
Posted 对方向你抛出一堆BUG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS知识点相关的知识,希望对你有一定的参考价值。
1. HDFS
1.1 简介
HDFS是一个分布式文件系统,用于存储大且多的文件。适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析。
1.2 优点
高容错:数据会自动拷贝副本,当某一个副本丢失,它也可以自动恢复
适合处理大数据:数据规模可以支持GB,TB,甚至PB级别数据。
可构建在廉价的机器上,成本低。
1.3 缺点
不支持低延迟数据访问
无法高效的存储小文件:会占用NameNode大量内存来存储文件目录和块信息,而NameNode的内存是有限的
不支持并发写入文件,且文件不能修改只能追加内容
1.4 组成
1.4.1 块(block)
块是指一个大型文件在上传时,并不是直接存储这个文件,而是将这个大文件分为若干个指定大小的块进行存储,块的大小默认为128M,并且将这些块分别存储在不同的DataNode中
默认值为128M的原因
hadoop默认使用hadoop的集群的机器都采用普通的机器磁盘!基于最佳传输消耗理论,一次传输中寻址时间为总传输时间的1%为最佳状态!
目前机器磁盘的寻址时间普遍为10ms, 10ms / 1% * 磁盘的写入速度(100M/S)=100M 。如果公司的磁盘写入速度为300M/S,可以将dfs.blocksize=256M。如果公司的磁盘写入速度为500M/S,可以将dfs.blocksize=512M。
块大小不能太小: 如果块太小,会造成降低NN的服务能力!在读取和上传一个大的文件时带来额外的寻址时间消耗。
举例:当前运行NN的机器,有64G内存,除去系统开销,分配给NN50G内存!
文件a (大小1k), 存储到HDFS上,需要将a文件的元数据保存到NN,加载到内存,假设该文件的元数据大小为150B,那么最多存储50G/150B个文件a,总文件可以最大存储50G/150B * 1k
文件b (128M), 存储到HDFS上,需要将b文件的元数据保存到NN,加载到内存,假设该文件的元数据大小同样为150B,它最多存储50G/150B个文件b,但是总文件可以存储50G/150B * 128M
块大小不能太大:如果块太大,在一次上传时,如果发生异常,需要重新传输,造成网络IO资源的浪费!且在随机读取某部分内容时,不够灵活!
块大小
默认块大小为128M,128M指的是块的最大大小!每个块最多存储128M的数据,如果当前块存储的数据不满128M, 存了多少数据,就占用多少的磁盘空间!
说明
一个块只属于一个文件!!!
举例:这个块本来设置的128M,结果上一次上传129M文件时,这个块只用了1M,那么这个块就不能用来存储其他文件了
1.4.2 NameNode
作用:
NN保存HDFS上所有文件的元数据
NN负责接受客户端的请求
NN负责接受DN上报的信息,给DN分配任务(维护副本数)
元数据的存储:
元数据存储在fsiamge文件和edits文件中。fsimage是元数据的快照文件,edits是记录所有写操作的文件。
NN的元数据分两部分:①inodes(记录文件的属性和文件由哪些块组成): 记录在fsimage文件中或edits文件中。
②块的位置信息(每次DN在启动后,自动上报的,由NameNode动态生成)
fsimage文件:
①第一次格式化NN时,此时会创建NN工作的目录,其次在目录中生成一个fsimage_000000000000文件
②当NN在启动时,NN会将所有的edits文件和fsiamge文件加载到内存合并得到最新的元数据,并将元数据持久化到磁盘生成新的fsimage文件,例如fsimage_000000000001。而在合并了元数据后需要达到条件才能进行持久化:
需要满足checkpoint的条件:①默认1h ②两次checkpoint期间已经额外产生了100w txid的数据
③如果启用了2nn(SecondNameNode),2nn也会辅助NN合并元数据,会将合并后的元数据发送到NN
edits文件:
NN在启动之后,每次接受的写操作请求,都会将写命令记录到edits文件中,edits文件每间隔一定的时间或edits到达指定大小后就会重新生成一个新的edits文件继续记录写命令
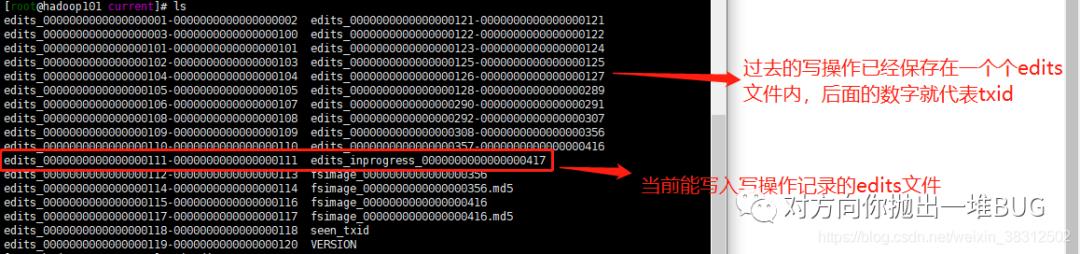
txid:每次写操作命令,分解为若干步,每一步都会有一个id,这个id称为txid。例如当前txid是1,当我上传一个文件,会被hdfs分成7步,每一步都会产生一个txid,那么上传完一个文件后,txid就会从1加到7
查看fsimage文件内容
hdfs oiv -p XML -i fsimage_0000000000000000356 -o /fsimage.xml由于fsimage文件一般方式是看不了的,所以使用上面hadoop自带的命令将内容输出为xml文件。-o 参数就是将fsimage文件输出到的位置
NN启动过程:
①先加载fsimage_000000xx文件,指最新的fsimage文件。即上一次已经合并过edits的最新的fsimage文件
②将fsimage_000000xx之后的edits文件进行加载
③合并生成最新的元数据,记录checkpoint,如果满足要求,执行saveNamespace操作,不满足等满足后执行。saveNamespace操作必须在安全模式执行
④自动进入安全模式(只能有限读,不能写),等待DN上报块:DN上报的块的最小副本数总和 / 块的总数 > 0.999,自动在30s离开安全模式!
注意:
由于NN在启动时已加载了fsimage和edits文件,所以NameNode最新的元数据始终在内存中。而块的总数是指fsimage和edits文件中记录的块的总数即之前成功上传过的文件的块的数量。
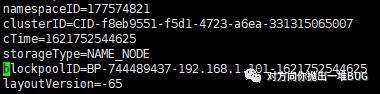
集群中的NameNode
每次格式化NN,会产生一个VERSION文件, VERSION记录的是NN的集群的信息 ,每次格式化NN时,重新生成clusterID和blockpoolID(会被DN领取,生成一个同名的目录,每次DN启动时,会将这个同名目录中的块上报NN)
DN在第一次启动时,如果没有VERSION信息,会向配置文件中配置的NN发起请求,生成VERSION,加入到集群!
NameNode中的VERSION文件:
DataNode自动生成的目录及VERSION文件内容:
![]()
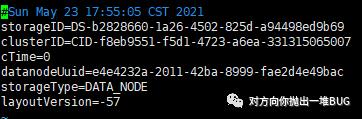
1.4.3 DataNode
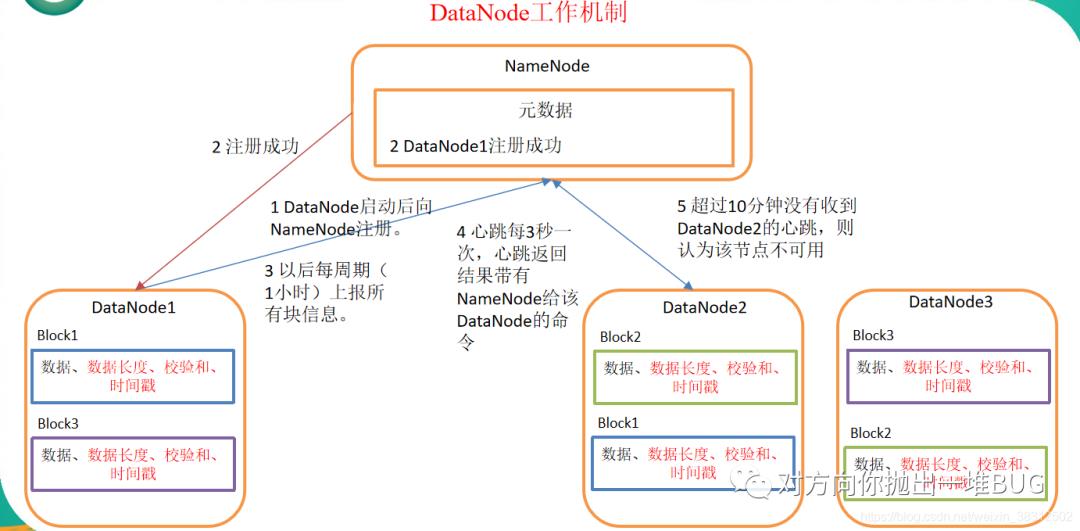
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
数据完整性:
当DataNode读取Block的时候,它会计算CheckSum。如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。Client读取其他DataNode上的Block。DataNode在其文件创建后周期验证CheckSum
1.5 流程
1.5.1 写流程
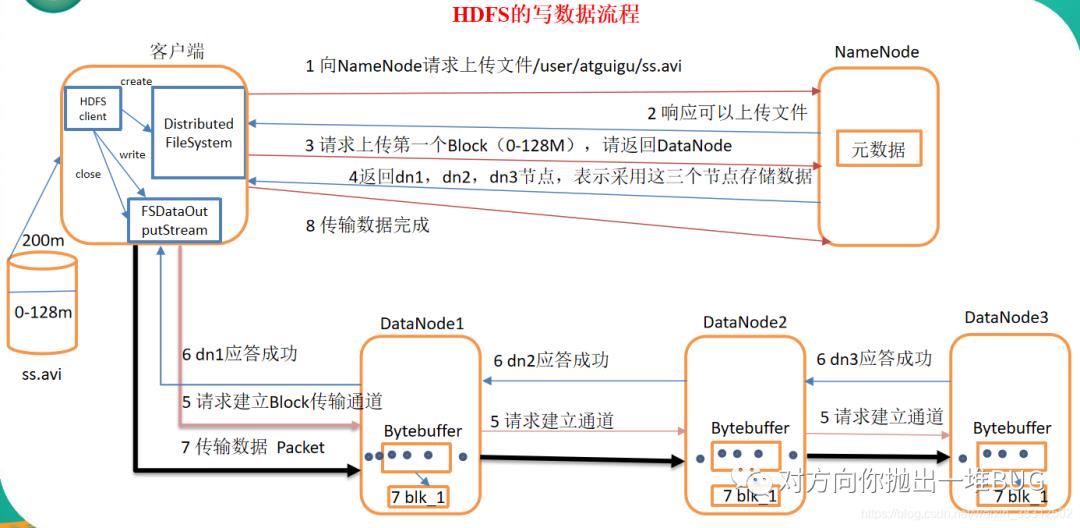
①服务端启动HDFS中的NN和DN进程,客户端创建一个分布式文件系统客户端,由客户端向NN发送请求,请求上传文件
②NN处理请求,检查客户端是否有权限上传,路径是否合法等,检查通过,NN响应客户端可以上传
③客户端请求第一个 Block上传到哪几个DataNode服务器上
④NN根据客户端上传文件的副本数(默认为3),根据机架感知策略选取指定数量的DN节点返回
⑤客户端根据返回的DN节点,请求建立传输通道,客户端向最近(网络距离最近)的DN节点发起通道建立请求,由这个DN节点依次向通道中的(距离当前DN距离最近),下一个节点发送建立通道请求。
⑥各个节点发送响应 ,通道建立成功
⑦客户端每读取64K的数据,封装为一个packet(数据包,传输的基本单位),将packet发送到通道的下一个节点。通道中的节点收到packet之后,落盘(检验)存储,将packet发送到通道的下一个节点!每个节点在收到packet后,向客户端发送ack确认消息!
⑧一个块的数据传输完成之后,通道关闭,DN向NN上报消息,已经收到某个块
⑨第一个块传输完成,第二块开始传输,依次重复⑤-⑧,直到最后一个块传输完成,NN向客户端响应传输完成! 客户端关闭输出流
异常写流程
①-⑥见上
⑦客户端每读取64K的数据,封装为一个packet,封装成功的packet,放入到一个队列中,这个队列称为dataQuene(待发送数据包),在发送时,先将dataQuene中的packet按顺序发送,发送后再移入到ackquene(正在发送的队列)。
每个节点在收到packet后,向客户端发送ack确认消息! 如果一个packet在发送后,已经收到了所有DN返回的ack确认消息,这个packet会在ackquene中删除!假如一个packet在发送后,在收到DN返回的ack确认消息时超时,传输中止,ackquene中的packet会回滚到dataQuene。重新建立通道,剔除坏的DN节点。建立完成之后,继续传输!只要有一个DN节点收到了数据,DN上报NN已经收完此块,NN就认为当前块已经传输成功!副本数如果暂时不满足条件,之后NN会自动检查,维护副本数!
1.5.2 读流程
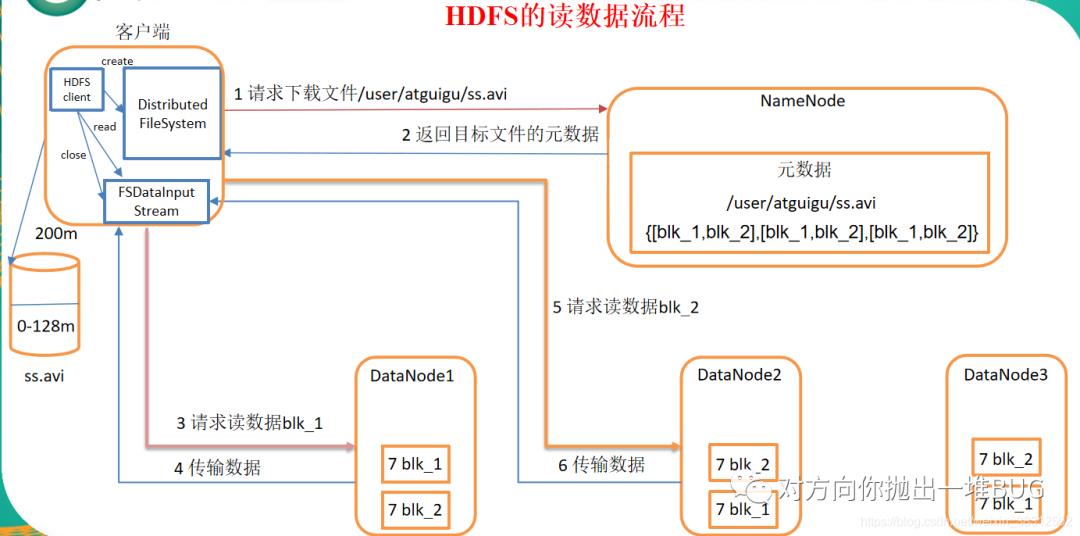
①启动服务端NN,DN进程,提供一个分布式文件系统客户端,由客户端向NN发送请求,请求下载一个文件
②NN对请求进行合法性检查(权限,路径是否合法),如果合法,NN响应客户端允许下载,同时返回当前下载文件的所有元数据信息(块的映射信息)
③客户端根据返回的元数据信息,去每个对应的DN节点按照顺序依次下载每个块
1.6 机架感知
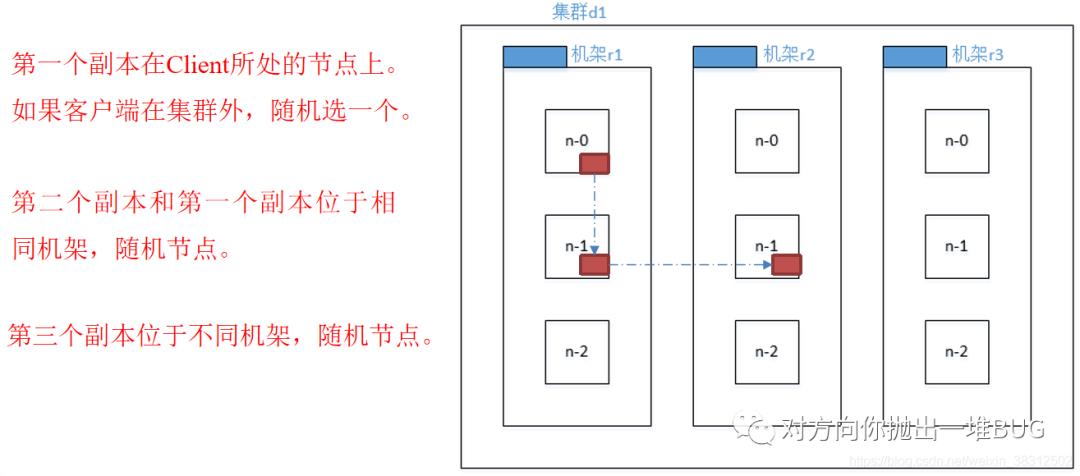
默认的策略:第一个副本放在本地机架的一个DN节点(速度最快)。
第二个副本放在本地机架的另一个DN节点(速度也很快!)
第三个副本为了安全性放在其他机架的一个DN节点
1.7 使用java客户端操作HDFS
1.7.1 引入POM
<dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.2.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.2.2</version></dependency>
1.7.2 java客户端操作windows本地文件系统
public void test () throws IOException {// 加载配置,最终所有配置文件中的配置都会以map结构加载到内存中Configuration conf = new Configuration();// 创建一个文件系统,至于是本地文件系统还是分布式文件系统,需要看你fs.defaultFS是怎么配置的,默认是file:///,即本地文件系统FileSystem fs = FileSystem.get(conf);// 创建文件夹fs.mkdirs(new Path("D:/a"));if (fs !=null) {fs.close();}}
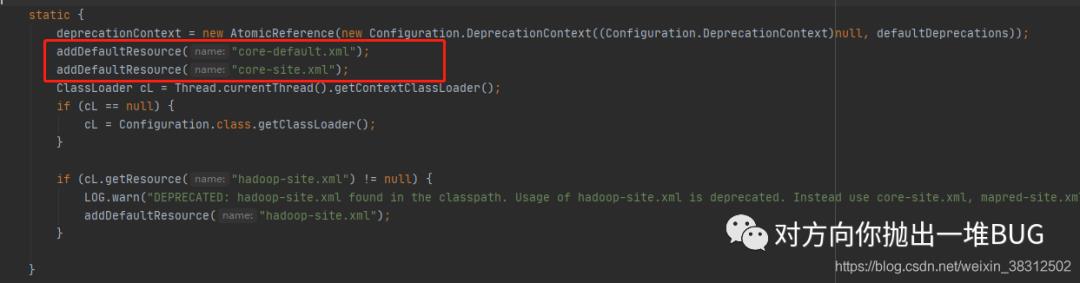
Configuration:这个类是用来加载配置文件中的配置的,默认读取hadoop-common中的core-site.xml配置文件,如果想要修改默认配置,有两种方式:1. 自己指定配置文件。可见Conconfiguration类下的静态代码块如下,该段代码表示会加载resource目录下的配置文件,可覆盖默认配置。
2. 使用Conconfiguration类的对象直接set配置项,或者使用FileSystem.get的方法,如下所示:
Configuration conf = new Configuration();// 第一种conf.set("fs.defaultFS", "hdfs://hadoop101:9000");// 第二种FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"), conf);
运行结果
1.7.3 java客户端操作远程分布式文件系统
public void test () throws IOException, URISyntaxException {// 加载配置,最终所有配置文件中的配置都会以map结构加载到内存中Configuration conf = new Configuration();// 创建一个文件系统,至于是本地文件系统还是分布式文件系统,需要看你fs.defaultFS是怎么配置的,默认是file:///,即本地文件系统FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"), conf);// 创建文件夹fs.mkdirs(new Path("/test"));if (fs !=null) {fs.close();}}
报错如下:当前操作的用户没有对hadoop进行写的权限
解决方式:
使用有写权限的root用户操作,FileSystem类提供了这样的方法:
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"), conf, "root");再次创建目录,成功
@Testpublic void test () throws IOException, URISyntaxException, InterruptedException {// 加载配置,最终所有配置文件中的配置都会以map结构加载到内存中Configuration conf = new Configuration();// 创建一个文件系统,至于是本地文件系统还是分布式文件系统,需要看你fs.defaultFS是怎么配置的,默认是file:///,即本地文件系统FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"), conf, "root");// 创建文件夹fs.mkdirs(new Path("/test"));// 上传文件fs.copyFromLocalFile(false, true, new Path("d:/b.txt"), new Path("/test/b.txt"));// 下载文件(失败) hadoop fs -get hdfs 本地路径fs.copyToLocalFile(false, new Path("/test/b.txt"), new Path("d:/c.txt"));// 删除文件 hadoop fs -rm -r -f 路径fs.delete(new Path("/test/b.txt"), true);// 重命名fs.rename(new Path("/test"), new Path("/test1"));// 判断当前路径是否存在System.out.println(fs.exists(new Path("/test2")));// 关闭流if (fs !=null) {fs.close();}}}
下载文件失败的原因:我没有在windows上成功启动hadoop的服务端,而下载文件是将文件下载到windows本地的,而FileSystem对象并不能获取到windows本地的hadoop文件系统。
1.8 高可用HA
高可用,意味着必须有容错机制,不能因为集群故障导致不可用
HA分析:
① 启动多个NN进程,一旦当前正在提供服务的NN故障了,让其他的备用的NN继续顶上。
② 当启动了多个NN时,不允许多个NN同时对外提供服务,最多只能有一个NN作为主节点,对外提供服务,其余的NN作为备用节点。(使用active状态来标记主节点,使用standby状态标记备用节点)因为如果多个NN同时对外提供服务,那么在同步元数据时,非常消耗性能,而且容易出错!
③ 主NameNode负责接受客户端的请求,在接收客户端的写请求时,主节点还负责记录用户上传文件的元数据,那么实现HA就必须保证 主节点必须和备用节点之中的元数据是一致的!
NameNode元数据的同步:
在active的NameNode格式化后,将空白的fsimage文件拷贝到所有的NameNode的机器上
active的NameNode在启动后,由于Edits日志只有Active状态的NameNode节点可以做写操作,所以由主节点将edits文件中的内容发送给Journalnode进程,standby状态的NameNode主动从Journalnode进程拷贝数据,保证元数据的同步。这样在集群中既保证了主节点不会有大量standby节点来拷贝数据的压力,也保证了NameNode主从节点间数据的一致性。
Journalnode在设计时,采用paxos协议, Journalnode适合在奇数台机器上启动! 在hadoop中,要求至少需要3个Journalnode进程。
如果开启了hdfs的ha,不能再启动2nn。
以上是关于HDFS知识点的主要内容,如果未能解决你的问题,请参考以下文章