Hive 介绍
什么是Hive?
Hive 是基于 Hadoop 的一个数据仓库工具,由 Facebook 开源,用于解决海量结构化日志的数据统计。它可以将结构化的数据映射为类似数据库中的一张表,并提供 类SQL 查询功能,本质是将 HQL(Hive SQL) 转化为MapReduce程序。
在介绍 Hadoop 的时候我们说过,使用 MapReduce 编程会很麻烦。但是程序员很熟悉 SQL,于是 Hive 就出现了,它可以让我们像写SQL一样来进行编程。会自动将我们写的 SQL 进行转化,翻译成 MapReduce。所以从这里我们可以看出,Hive 是不是就相当于一个翻译官啊,可以让我们不用直接面对 MapReduce,我们只需要写SQL即可,至于SQL语句怎么对应成 MapReduce,那么是 Hive 做的事情,我们不需要关心。
当然我们这里说的 SQL,更准确的说应该是 HQL,它和 SQL 非常类似,可以说你只要会 MySQL、PostgreSQL等关系型数据库,那么使用 Hive 没有任何障碍。

在介绍 Hadoop 的时候,我们说过 Hive 处理的数据存储在 HDFS 上;底层分析数据采用的依旧是 MapReduce,但是将 类SQL语言 和 MapReduce 做了一层映射,可以帮我们把 SQL语句 翻译成 MapReduce;执行程序运行在 YARN 上,这是显而易见的,因为实际计算的仍是 MapReduce嘛。
但是 HDFS 上的数据并没有所谓的表结构、字段信息,所以除了 HDFS 之外,Hive还依赖关系型数据库,比如:MySQL。在将 HDFS 上的数据抽象成一张表时,这些表信息都存在关系型数据库中,而这些表信息也叫作元信息、或者元数据,它是存储在关系型数据库中的,而实际数据则存在 HDFS 上。
hive的优点
操作接口采用类SQL的语法,提供快速开发的能力(简单、容易上手)避免了去写MapReduce,减少开发人员的学习成本Hive的执行延迟比较高,因此Hive擅长于数据分析、对实时性要求不高的场合还是因为Hive的延迟比较高,使得Hive的优势在于处理大数据,对于处理小数据没有优势Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
hive的缺点
Hive的HQL表达能力比较有限,比如:迭代式算法无法表达、数据挖掘方面不擅长Hive的效率比较低,虽然Hive能自动地生成MapReduce作业,但是通常情况下不够智能化;以及Hive调优比较困难,粒度较粗
hive的架构

1. 用户接口:Client
CLI(hive shell),pyhive(Python访问hive),WebUi(浏览器访问hive)
2. 元数据存储:MetaStore
负责存储元数据,元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等等
3. 实际数据存储:HDFS
使用HDFS进行存储,使用MapReduce进行计算
4. 驱动器:Driver
1.解析器(sql parser):将SQL字符串转成抽象语法树(ast),这一步一般都用于第三方工具完成,比如antlr,然后对ast进行语法分析,比如表是否存在、字段是否存在、逻辑是否有误等等
2.编译器(physical plan):将ast编译生成逻辑执行计划
3.优化器(query optimizer):对逻辑执行计划进行优化
4.执行器(execution):把逻辑执行计划转化为可以运行的物理计划
hive和数据库的比较
由于Hive采用了类似于SQL的查询语言HQL(hive query language),因此很容易将Hive理解为数据库。其实从结构上看,Hive除了和数据库拥有类似的查询语言,再无相似之处,下面我们来看看两者的差异。
1. 查询语言
由于SQL被广泛的运用在数据仓库中,因此,专门针对Hive的特性设计类SQL的查询语言HQL,熟悉SQL开发的开发者可以很方便的使用Hive进行开发
2. 数据的存储位置
Hive是建立在Hadoop之上的,实际数据是存储在HDFS中的,而数据库则是可以将数据保存在块设备或本地文件系统中的。
3. 数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此Hive不建议对数据进行改写,所有的数据都是在加载的时候确定好的,而数据库中的数据通常是需要进行修改的。
4. 索引
Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。而由于MapReduce的引入,Hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive仍可以体现出优势。数据库中,通常会针对一个或几个列建立索引,因此对于少量的具有特定条件的数据访问,数据库可以有很高的效率,较低的延迟。所以由于Hive访问数据的延迟较高,决定了它不适合在线数据查询。
5. 执行引擎
Hive中大多数查询的执行是通过Hadoop提供的MapReduce实现的,而数据库通常有自己的执行引擎
6. 执行延迟
Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延时较高。另外一个导致Hive执行延迟高的因素是MapReduce框架,由于MapReduce本身具有较高的延迟,因此在利用MapReduce执行Hive查询时,也会有较高的延迟。相对的,数据的执行延迟较低,当然这个低是有条件的,即数据的规模较小。当数据的规模大到超过了数据库的处理能力的时候,Hive的并行计算显然能够体现出其优势。
7. 可扩展性
由于Hive是建立在Hadoop之上的,所以Hive的可扩展性和Hadoop是一样的(世界上最大的hadoop集群在Yahoo!,2009年的规模在4000台节点左右)。而数据库由于ACID语义的严格限制,扩展性非常有限。目前最先进的并行数据库Oracle在理论上的扩展能力也只有100台左右。
8. 数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据。对应的,数据库支持的数据规模较小。
Hive 安装
下面我们来安装 Hive,由于它是 Apache 的顶级项目,所以它的官网是 hive.apache.org。但是这里我们不采用官方的社区版本,而是采用Cloudera公司的CDH版本。下载地址是:http://archive.cloudera.com/cdh5/cdh/5 ,我们进入这个页面,找到:hive-1.1.0-cdh5.15.1.tar.gz,点击下载即可。注意:使用 Hive 需要本地有 jdk 和 Hadoop,而Hadoop我在上一篇博客中已经介绍了,可以去看一下,并且目前 Hadoop 的服务都已经启动了。而在安装 Hadoop 的时候,采用的CDH版本是 5.15.1,所以这里 Hive 的CDH版本也是5.15.1。
下载完毕之后直接解压到 /opt 目录下即可,大数据组件我都放在 /opt 目录下,然后再将 bin 目录配置到环境变量。
然后看一下 Hive 的目录结构:
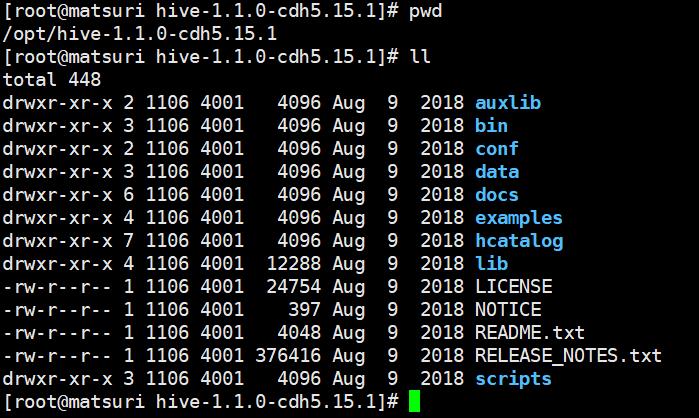
bin目录是用来执行一些命令的,我们注意到没有sbin目录,sbin目录一般是存放启动文件的,就像hadoop的sbin一样,显然Hive是将两者合并了到bin目录里面了。conf是存放配置的,lib是存放一些jar包的,还有examples案例,等等。
然后下面老规矩,肯定要修改配置文件。
我们需要修改 hive-env.sh,但是 conf 下面没有这个文件,不过有hive-env.sh.template,所以需要先 cp hive-env.sh.template hive-env.sh。我们需要指定 HADOOP_HOME 和 HIVE_CONF_DIR,也就是 Hadoop 的安装目录 和 conf目录的绝对路径。
export HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.15.1/
export HIVE_CONF_DIR=/opt/hive-1.1.0-cdh5.15.1/conf
修改完毕,由于我已经配置了环境变量,所以在家目录启动一下 hive,直接输入 hive 即可。如果没有配置环境变量,那么需要进入到 bin 目录里面。

我们看到此时我们通过 shell 的方式启动了一个客户端,我们看到默认是有一个default库。但是 Hive 默认存储元数据使用的库叫 Derby,我们需要将其改成 MySQL、或者 PostgreSQL,这里我们就用 MySQL吧。
安装 mysql。
1. wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
2. rpm -ivh mysql-community-release-el7-5.noarch.rpm
3. yum install mysql-server(如果失败的话,可以先执行一下yum update)
4. mysqld --initialize
5. systemctl start mysqld
6. 输入:mysqladmin --version 回车,如果出现类似
mysqladmin Ver 8.42 Distrib 5.6.50, for Linux on x86_64说明安装成功7. 设置密码:mysqladmin -u root password 你的密码
8. mysql -u root -p 进入数据库

MySQL就安装成功了,然后我们指定 Hive 使用 MySQL来存储元数据。
这里我们修改conf目录下的 hive-site.xml,但是没有这个文件,所以我们要 touch hive-site.xml,然后打开在里面输入如下内容:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定mysql, 将元数据存在metastore这个库中 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value>
</property>
<!-- 指定mysql的驱动, 后面还需要单独下载 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 指定mysql的用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 指定mysql的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>密码
<value>123456</value>
</property>
<!-- hive 元数据存储版本验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
我们说连接MySQL需要有相应的驱动,Java连接MySQL的驱动网上随便一搜就能找到,这里我们可以使用菜鸟教程提供的 https://www.runoob.com/java/java-mysql-connect.html,进去会看到页面所提供的下载路径。下载完毕之后,直接扔到 HIVE_HOME 的 lib 目录里面去就行了。
然后我们再来启动一下hive客户端,启动之后观察一下 MySQL 的 database。
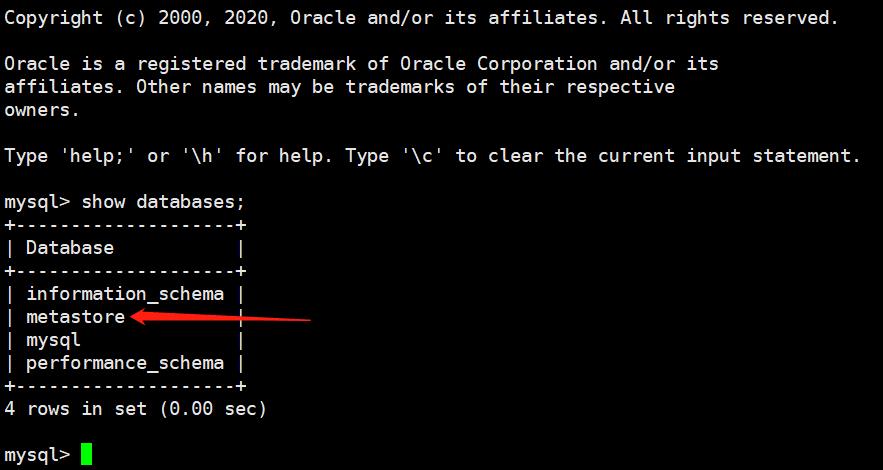
我们看到 metastore 这个库已经自动帮我们创建了,下面我们创建一张表测试一下。注意:这里创建表可不是在 MySQL 中创建,而是在 hive 中创建,创建之后元数据信息会存储在MySQL中。然后我们 insert 数据,会保存在 HDFS 中。

然后我们通过 webUI 的方式查看一下,创建的数据默认位于 /user/hive/warehouse 中,我们可以通过在 hive-site.xml 中指定 hive.metastore.warehouse.dir 来自定义存储目录。
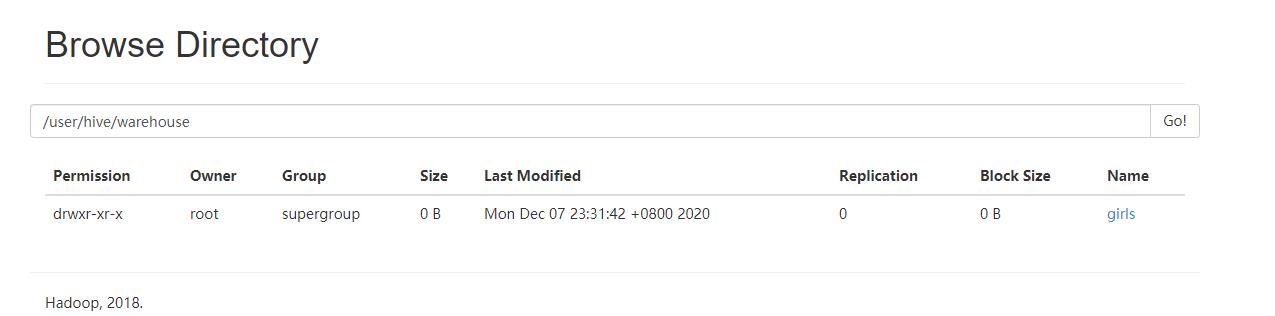
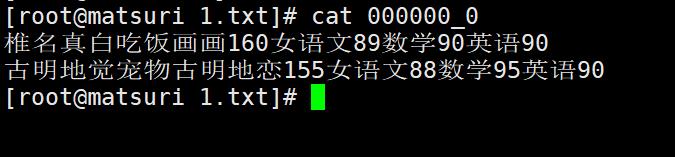
girls是一个目录、代指表,里面有一个文件 000000_0 存储了实际的数据,我们将其下载下来看看里面的内容是什么。

这不就是我们插入的数据吗,而且我们看到这只是单纯的数据,像什么字段名、类型统统都没有。所以这就是 Hive,HDFS 只存储实际数据,至于表的元信息则存在 MySQL 中。然后在查找的时候,会先去 MySQL 中查找对应的元信息,然后在 HDFS 上找到对应的数据。所以整体流程还是比较简单的,至于图中的 SOH 则不用管,它类似于分隔符一样的东西。
如果我们将 MySQL 给卸载掉,那么元数据会消失,但实际数据则不会,因为它是存在 HDFS 上的。当我们重新安装之后,只需要重新执行建表逻辑即可,依旧可以 select 出数据,因为数据一直都在 HDFS 上。
下面我们再来做个实验,我们手动往 HDFS 上拷贝一份文件:
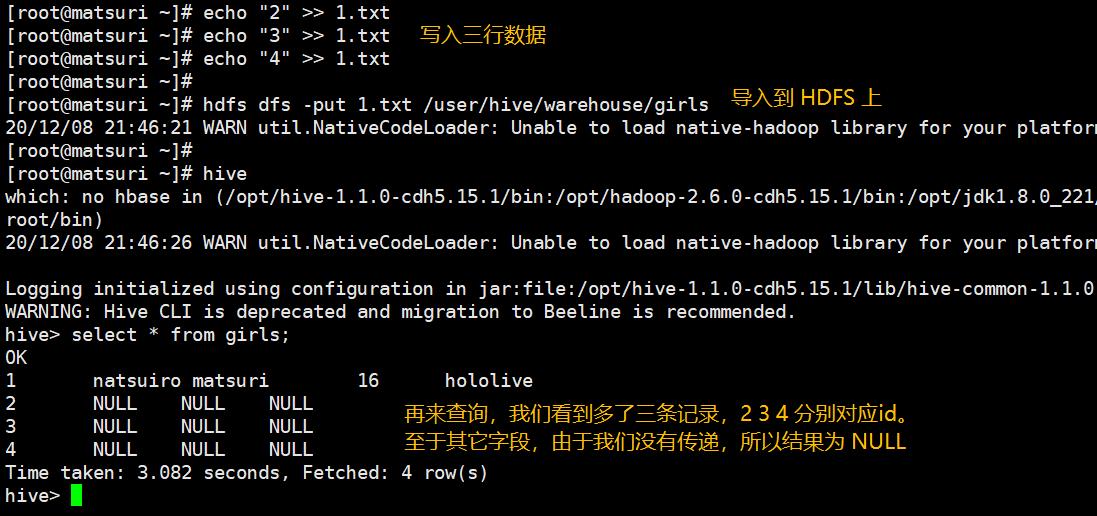
所以我们在 hive 上创建一张表,相当于在 HDFS 上创建一个目录,该目录中的文件存放我们实际导入的数据。然后我们查询该表时,等价于去 HDFS 上查询该目录下的文件内容。因此我们手动导入的文件里面的内容,也被打印出来了。
因此有两个过程:先在MySQL中找元数据,再根据元数据找HDFS上的实际数据。
配置服务让第三方访问
我们目前是通过启动一个 hive shell 的方式访问的,如果我们想通过代码、或者数据库管理工具去连接的话,目前可以办到吗?
答案显然是不行的,因为我们目前没有启动任何一个和 Hive 有关的服务,没有服务也就没有相应的端口,我们在外界根本没有任何东西可以连接。不像HDFS,我们启动了 NameNode 和 DataNode,在外界可以通过 50070 端口连接,但是 Hive 的话则不行,因为我们没有启动相关的服务。
因此命令行输入 hive 启动一个 shell 只是方便测试,而如果想让第三方使用 Hive 上的数据,那么就必须给 Hive 启动一个服务。
我们需要在 hive-site.xml 中添加如下信息:
<property>
<!-- 指定元数据要连接的地址 -->
<name>hive.metastore.uris</name>
<value>thrift://matsuri:9083</value>
</property>
但是这样的话直接启动 hive 虽然是可以的,但是尝试访问数据的时候会报错,因为无法连接指定地址,我们需要先开启服务才可以。开启服务通过 hive --service metastore,这是一个前台进程,你需要再启动一个窗口,然后就可以在命令行中启动hive shell 并访问数据了。虽然这种方式对于本地而言有点麻烦,但是至少它向外界暴露了一条通道,可以支持外界访问,但是我们不推荐这种方式,所以这个配置我就不加了,可以自己测试一下。
我们来看另一种配置 Hive 服务的方式,我们推荐使用这一种,还是修改配置文件,在里面加入如下内容:
<property>
<!-- 指定hiveserver2要连接的地址 -->
<name>hive.server2.thrift.bind.host</name>
<value>matsuri</value>
</property>
<property>
<!-- 指定hiveserver2要连接的端口, 默认也是 10000 端口 -->
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- 以上两个配置其实也可以不用加, 因为默认就是上面两个配置 -->
然后启动 hiveserver2 服务,hive --service hiveserver2,这依旧是一个前台进程。
然后我们在 Windows 上通过 Python 的 impala 模块来访问一下。
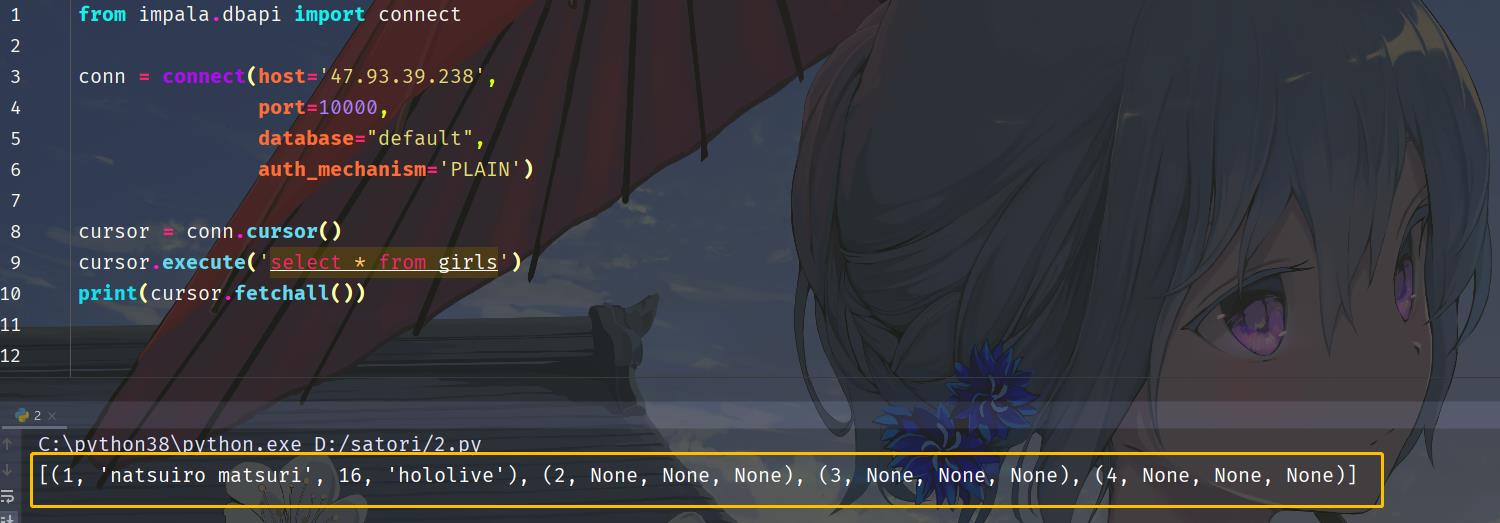
我们看到此时数据就成功的访问了,怎么样,是不是很简单呢?所以通过 hive --service hiveserver2 的方式向外界暴露一个服务,支持外界来访问相关的数据。但是我们注意一下里面的 auth_mechanism 参数,它表示 Hive 的认证机制,可以在 hive-site.xml 中通过 hive.server2.authentication 设置,我们在使用 impala 连接时指定的auth_mechanism参数的值要与之匹配,这个后面会说。当然默认情况下是 PLAIN,你也可以指定为 NOSASL,表示不认证。不过绝大部分生产环境中我们都是使用Kerberos认证,这个时候需要你本地有 Keytab 文件,然后将 auth_mechanism 为 GSSAPI即可。
然后我们来介绍一下如何安装impala,毕竟它的安装还是比较麻烦的。
1. pip install pure-sasl;
2. pip install thrift_sasl==0.2.1 --no-deps;
3. pip install thrift==0.9.3;
4. pip install thriftpy==0.3.9;
以上四个包安装没有任何问题,直接pip install即可,只是在安装过程第四个包thriftpy的时候会显示:ERROR: thrift-sasl 0.2.1 requires sasl>=0.2.1, which is not installed.,但是不用管,忽略它即可。
然后安装一个叫做 bitarray 的包,但由于它是使用C扩展编写的,在Windows上安装会报出gcc编译错误。可以下载vscode,但是比较麻烦,推荐的办法是进入
https://www.lfd.uci.edu/~gohlke/pythonlibs/进行下载对应Python版本的bitarray,进行安装。最后
pip install impyla,安装的时候叫 impyla,但是使用的时候是impala。
安装成功之后还没完,如果安装之后你直接像上图代码那样连接的话,应该会报出如下错误。
"""
Traceback (most recent call last):
File "D:/satori/1.py", line 14, in <module>
conn = connect(host=\'47.94.174.89\', port=10000, database="default", auth_mechanism=\'PLAIN\')
File "C:\\python38\\lib\\site-packages\\impala\\dbapi.py", line 144, in connect
service = hs2.connect(host=host, port=port,
File "C:\\python38\\lib\\site-packages\\impala\\hiveserver2.py", line 825, in connect
transport.open()
File "C:\\python38\\lib\\site-packages\\thrift_sasl\\__init__.py", line 75, in open
self._send_message(self.START, chosen_mech)
File "C:\\python38\\lib\\site-packages\\thrift_sasl\\__init__.py", line 94, in _send_message
self._trans.write(header + body)
TypeError: can\'t concat str to bytes
"""
根据提示信息:我们进入thrift_sasl模块下的 __init__.py 中,找到第94行。
# 值得一提的是,python中的缩进应该是四个空格,但是thrift_sasl用的两个空格,不过不影响
def _send_message(self, status, body):
header = struct.pack(">BI", status, len(body))
self._trans.write(header + body)
self._trans.flush()
# 我们看到报错的原因是header + body、因为字符串和字节无法相加
# 将上面代码改成如下
def _send_message(self, status, body):
header = struct.pack(">BI", status, len(body))
if isinstance(body, str):
body = bytes(body, encoding="utf-8")
self._trans.write(header + body)
self._trans.flush()
然后重新执行,成功获取数据。我个人到此就执行成功了,按照上述方法安装应该能够正常访问,但是你也可能还会报出如下错误。
"""
ThriftParserError: ThriftPy does not support generating module with path in protocol \'c\'
"""
# 如果报出上面错误,那么进入site-packages\\thriftpy\\parser\\parser.py
# 找到第488行,应该会看到一个条件语句,如下:
if url_scheme == \'\':
with open(path) as fh:
data = fh.read()
elif url_scheme in (\'http\', \'https\'):
data = urlopen(path).read()
else:
raise ThriftParserError(\'ThriftPy does not support generating module \'
\'with path in protocol \\\'{}\\\'\'.format(
url_scheme))
"""
将
if url_scheme == \'\':
改成
if url_scheme == \'\' or len(url_scheme) == 1:
即可
"""
可能有的小伙伴觉得这种方式不够优雅,能不能通过 SQLAlchemy 创建引擎的方式来访问呢?答案是可以的。
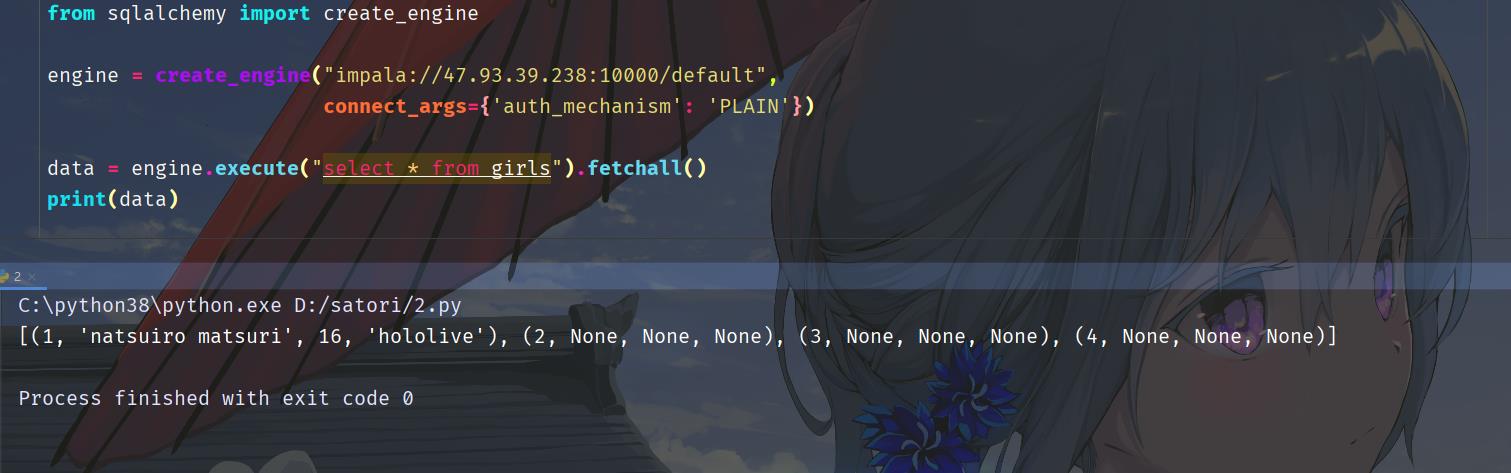
额外的参数通过 connect_args 参数指定,以字典的形式。另外除了 impala 之外我们还可以使用 pyhive,不过个人更推荐 impala。因为笔者在工作中这两个都用过,发现 pyhive 在读取数据的时候偶尔会出现数据串行的情况,但是 impala 不会。
以上就是在Windows上使用Python连接hive的方式,不过个人觉得这只适合学习,如果你想连接你们公司内网的 Hive 服务的话,希望应该渺茫。毕竟生产环境中几乎都是采用Kerberos认证,这种情况下在Windows上再想连接的话会贼麻烦。而且个人觉得,像数仓这种东西,一般都只能在指定的内网中访问中,在本地公网环境能连接的可能性不大。
当然如果你不是纯粹的大数据运维团队的话,个人觉得也不用在意这一点,因为我们做开发的话,重点还是要掌握 Hive 的语法,能够熟练使用 HQL 操作里面的数据才是第一位的。
当然我们说这种方式启动的服务是前台进程,一旦终端关闭,服务也就停止了,因此我们需要后台启动。
而后台启动服务,我们需要使用Linux中的nohup命令:nohup hive --service hiveserver2 >> /dev/null&,这样启动的进程就是后台的了。注意:这种方式,除了可以让外界访问之外,hive shell 本身也是可以访问的。
当然目前输入 hive 的话,会进入交互式界面,但我们也可以在不进入交互式的情况下执行SQL语句。
hive -e "SQL语句"
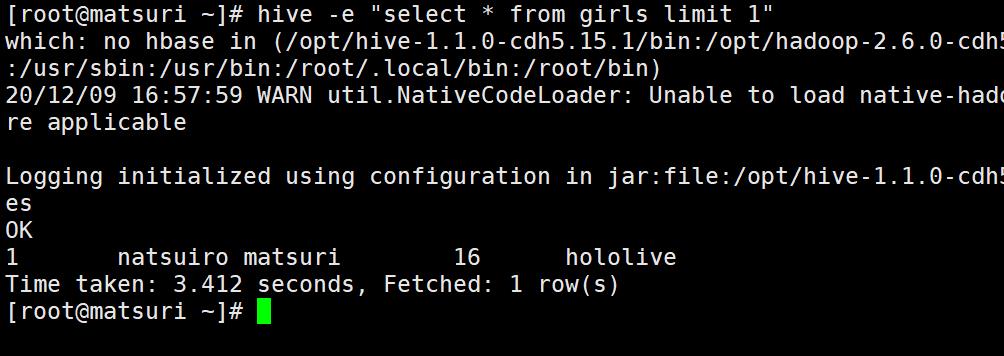
这样的话就可以在不用进入 shell 的情况下,执行语句了。
另外除了执行语句之外,我们还可以把语句写在文件里,通过 hive -f 文件名,来执行文件里面的SQL语句。不管是哪种方式,它们都还支持重定向,比如:hive -f "select * from girls" > 1.txt,可以将查询结果重定向到指定的文件中。
Hive 的数据类型
下面我们来看看 Hive 的数据类型,数据类型有基本数据类型 和 集合数据类型。
基本数据类型

还是比较简单的,基本都是熟悉的类型名称。像 tinyint、smallint 交互不怎么常用,毕竟是大数据框架,这两老铁用的实在是不多。然后string类型就相当于数据库的 varchar 类型,它是一个可变的字符串,只不过不能显示的声明最多存储多少个字符,不过理论上可以存储 2GB 的字符串。而日期类型可以是 timestamp(年月日时分秒),或者 date(年月日),当然 date 图中忘记写了。
集合数据类型

Hive 有三种复杂类型:struct、map 和 array。array 和 map 就想成 Python 的 列表和字典即可,而struct则等价于 C 或者 Go 的结构体,它封装了一个命名字段的集合,复杂数据类型允许任意层次的嵌套。
不过这种复杂的数据类型不是很常用,下面来演示一下。想基础数据类型我们就一笔带过了,有关系型数据库经验的话肯定不是问题。
首先定义一张表,里面有4个字段。name、hobby、info、score。
name:姓名,显然是string类型hobby:兴趣,一个人可以有很多兴趣,所以这是一个arrayinfo:个人信息,比如身高->int,性别->string,这是一个结构体score:成绩,语文:90,数学:89,英语:92,这是一个map
那么怎么定义这张表呢?
create table student (
name string,
hobby array<string>,
info struct<length: int, gender: string>,
score map<string, int>
)
--还没完,还有一个很重要的事情就是分割符
--对于每一个字段来说,我们在插入数据的时候,是使用逗号分割
--但是对于集合来说,有多个元素,我们要怎么分开呢,因此我们需要指定分割符
--字段之间,使用逗号分割,默认的
row format delimited fields terminated by \',\'
--对于集合来说,我们使用 _ 分割里面的每一个元素
collection items terminated by \'_\'
--比如hobby就是 唱歌_跳舞
--info就是 160_女
map keys terminated by \':\'
-- 对于map,我们使用:分隔键值对,那么score就可以是 总分:285
lines terminated by \'\\n\';
--也可以不用指定,多行默认使用\\n分割
我们把注释去掉,执行一下,在表创建成功之后便可以插入数据了。
这里我们将数据写在文件里面,命名为 /root/student.txt。
椎名真白,吃饭_画画,160_女,语文:89_数学:90_英语:90
古明地觉,宠物_古明地恋,155_女,语文:88_数学:95_英语:90
我们看到struct、map、array,内部所有的元素都是采用 _ 进行分隔,至于 map 里面的键值对则是使用 :,然后我们可以在 hive shell 中通过 load data local inpath "文件名" into table 表名 的方式进行导入。
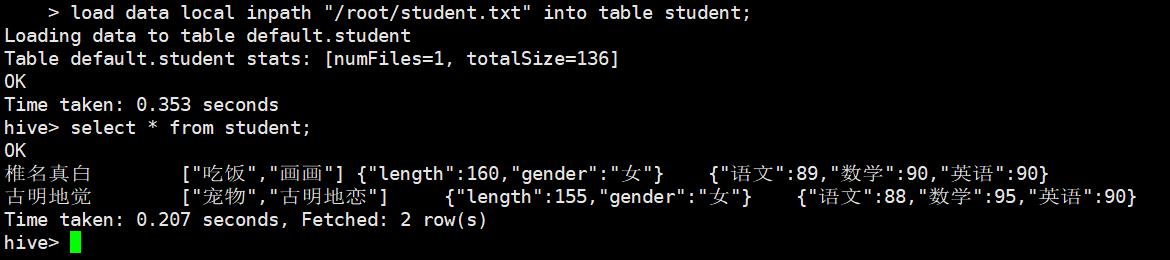
此时我们看到数据已经被导入了,而且也成功的查询到了。
那么问题来了,我们如何获取array、map、struct中的指定元素呢?
-- hobby[1]表示获取数据组中索引为1的元素
-- info.length表示获取结构体中成员为length的元素
-- score[\'语文\']表示获取map中key为\'语文\'的元素
select name, hobby[1], info.length, score[\'语文\'] from student;

怎么样,是不是成功获取了呢?另外,这个打印的格式是不是不太好看啊,明显都错位了。因此为了打印好看,我们后面就使用 Python 来执行了,封装一个函数,将语句传进去即可,然后会返回 DataFrame,从而打印漂亮的输出。

变量 hql 里面的就是执行的SQL(HQL)语句,调用 execute_hql 函数,将 HQL 传进去即可得到结果,和使用 hive shell 是一样的,只不过打印明显变好看了。而且使用 Python 这种方式打印我们还可以自动得到字段信息,默认使用 hive shell 执行得到的结果是没有字段信息的。另外,最左边的 0 1 不属于 hive 返回的数据信息,它是 DataFrame 自带的,不用关心。
类型转换
Hive 的原子数据类型是可以进行隐式转换的,例如某表达式使用 int 类型,tinyint会自动转换为int类型,但是 Hive 不会反向转化。例如某表达式使用 tinyint 类型,而 int 类型不会转化为 tinyint 类型,它会返回错误,除非使用 cast 进行转化。
1. 首先是 隐式转化。
任何一个整数类型都可以转化为范围更广的类型,比如tinyint可以转为int、int可以转为bingint所有整数类型、float、string都可以隐式地转化为doubletinyint、smallint、int都可以转为floatboolean类型不可以隐式转化为其它任何类型
2. 可以使用cast进行 显式转化。
可以使用 cast(\'1\' as int) 将字符串 \'1\' 转换为整型1;如果强制转化失败,比如cast(\'xxx\' as int),则表达值返回空值NULL。

\'1\' + 2,显然;两个元素都转成了double。
DDL 数据定义
下面我们来看看 Hive 支持的DDL操作,在 Hive 中 DDL 远没有 DML 重要,但我们还是要了解的。
创建数据库
创建一个数据库很简单,和MySQL类似,当然 Hive 默认有一个 default 库。
create database db_hive; -- 表示创建 db_hive 这个库
但如果 db_hive 已经存在的话会报错,因此更严格一点的写法是 create database if not exists db_hive,我们看到这和 MySQL 是高度相似的。
我们执行一下,显示创建成功,但是创建之后的数据库在哪呢?显然如之前说了,都在 /user/hivewarehouse/ 下面,我们来看看。

可以看到我们在 default 数据库中建的表也在 /user/hivewarehouse/ 下面,建的数据库也是一样的。因此为了区分,会自动在我们建的数据库名后面加上一个 .db,来区分这是一个数据库。我们在db_hive数据库中建一张表看看,而在db_hive数据库里面建立的表,显然在 /user/hivewarehouse/db_hive.db 路径下面会多一个目录。
然后我们查看一下。
可以看到该库下已经有我们创建的表了。而且我们创建数据库的也可以自己指定位置,只需要加上一个 location 路径 即可。
create database if not exists komeijisatori location \'/komeijisatori123\'
执行之后就会创建了一个名为 komeijisatori 的数据库,但是路径在 / 下面,并且指定了新名字 komeijisatori123。所以一个库和一张表在 HDFS 上都会对应一个目录,并且它们的名字是一致的,当然数据库的话在HDFS上结尾会多出一个 .db。但是它们的名字也可以不一样,只不过一般我们都是设置成一样的,为了统一,否则的话只会给自己找麻烦。
查询数据库
这个就没必要介绍了吧,只是 hive 中查询数据库还支持模糊查询。

还可以查看数据库信息,desc database 数据库,显示详细信息的话 desc database extended 数据库。

修改数据库
用户可以使用 alter database 来为某个数据库设置键值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据所在的位置,只能改一些附加的信息,比如创建时间等等,这里不介绍了,没啥太大卵用。
删除数据库
drop database 数据库,可以看到基本上和 MySQL 的语法差不多。如果某个数据库删不掉,那么可以使用 drop database 数据库 cascade 语法强制删除。
hive> show databases;
OK
db_hive
default
Time taken: 0.013 seconds, Fetched: 2 row(s)
hive> drop database db_hive; # 我们看到删不掉, 因为数据库不为空, 里面存在着表
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.
InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
hive> drop database db_hive cascade; # 加上 cascade 强制删除
OK
Time taken: 0.741 seconds
hive> show databases; # 删除成功
OK
default
Time taken: 0.016 seconds, Fetched: 1 row(s)
hive>
创建表
创建表还是蛮复杂的,首先我们来看一下最基本的建表语句。
create table 表名 (
列名 类型 [comment 注释],
列名 类型 [comment 注释],
列名 类型 [comment 注释],
......
);
和关系型数据库创建表的语法类似,但是我们之前某次创建表的时候可没有这么简单,还制定了好多的分隔符啥的。那么下面再来看一看复杂的建表语句:
create [external] table [if not exists] 表名(
列名 类型 [comment 注释],
列名 类型 [comment 注释],
列名 类型 [comment 注释],
......
)
[comment 表注释]
[partitioned by (列名 类型 [comment 注释], ···)]
[clustered by (列名,列名,列名,···)]
[sorted by (列名[asc|desc], ···) into num_buckets buckets]
[row format row_format]
[stored as file_format]
[location hdfs_path]
我们先简单解释一下,后续会详细介绍:
external:表示创建一个外部表,不加表示创建内部表[comment 表注释]:除了给字段添加注释,还可以给表添加注释partitioned by:按照指定字段分区clustered by:按照指定字段分桶sorted by:按照字段排序,很少用row format:元素之间按照···分割stored:按照指定格式存储,默认是txtlocation:之前说了,指定hdfs存储路径
内部表和外部表
内部表和外部表的主要区别就在于删除方面。我们默认的创建的表都是内部表,也叫管理表。当我们删除一个表的时候,实际上删除的是数据库里面的元数据,而原始的数据信息存在hdfs上面。如果是内部表,hive会控制生命周期,在删除元数据的时候,HDFS上数据也会删除。但如果是外部表,那么删除元数据,不会影响HDFS上的原始数据,因为两者是不同的对象管理,我们来演示一下。
create table girl1(id int);
create external table girl2(id int);
创建两张表,girl1是内部表,girl2是外部表,然后将两个表全部删除,看看会有什么影响。

然后我们去 HDFS 上看一看。

我们看到外部表girl2还在,但是内部表girl1已经没了。
所以如果创建的是外部表的话,即使删除了元数据,HDFS上的原始数据依旧坚挺在那里。
那么我们如何选择呢?如何只是作为中间的临时表,建议使用内部表,否则还要手动删除HDFS上的数据,如果是一直使用的表,那么建立外部表,这样更安全。另外Hive是如何查询数据的呢?其实Hive是通过MySQL存储的元数据信息然后找到对应的存储数据的HDFS路径,这两者无论先有哪一个都无所谓。我们可以先有元信息,然后在指定的HDFS路径上存数据;也可以先有数据,然后再把数据存储的路径作为元信息存储到MySQL中,都是一样的,这两者没有所谓的先后顺序。
我们绝大部分建立的都是外部表,内部表只有在作为中间临时表才会用。
但是问题来了,如果我们创建表的时候不小心创建错了,本来想创建外部表结果创建成了内部表该怎么办呢?其实hive是支持我们修改的。
首先我们需要确定这张表到底是内部表还是外部表,可以使用 desc formatted table_name 来查看。

我们查看之前创建的girls表,发现输出了很多信息,比如:字段名、类型,所在数据库、所有者、创建时间等等,然后我们看到Table Type是MANAGED_TABLE,所以这是一张管理表(内部表)。
修改表的类型。
alter table 表名 set tblproperties(\'EXTERNAL\'=\'TRUE\'),表示把表变为外部表,同理FALSE的话,是把表变为内部表。注意:EXTERNAL、TRUE、FALSE这三者是固定写法,区分大小写,不能用小写。

成功修改为外部表。
修改表
1. 首先是重命名。
alter table 表名 rename to 新表名
2. 增加一列
alter table 表名 add columns (列名 类型, 列名 类型 ...),既然是columns,肯定是可以添加多列。
3. 修改一列
alter table 表名 change column 列名 新列名 类型,可以只改名字,也可以只改类型,当然新的列名和类型必须都写。
4. 替换一列
这个比较怪异,
alter table 表名 replace columns (列名 类型, 列名 类型),这个替换表示的是把原来表的列全部清空,然后把指定的新的列添加进去。比如原来的表有id,name字段,所以如果是replace columns (uid int, age int),那么此时的表就只有uid 和 int。所以比较让人难以理解,是把原来的所有列全删了,把新指定的列加进去。如果是替换单个列,就用change。但是注意的是我们改的是元数据,实际数据依旧存储在hdfs上面,是不会变的。
修改表很少用,大致了解一下即可。
分区表
普通的表对应HDFS的一个目录,目录里面是存储数据的文件。分区表也是对应一个 HDFS 文件系统上的独立目录,但是该目录下面是则不再是具体的文件了,而还是目录。而里面的分目录就是Hive中的分区,所以把一个大的数据集根据业务需要分割成多个小的数据集。然后在查询的时候指定分区,会提高效率。怎么理解呢?我们举个例子:

girls是我们的一张表,所以在HDFS上面是一个目录,girls目录里面存放的是具体的数据文件,点击就可以下载了。之前我们说过Hive是没有索引的,因此在查询数据的时候,是暴力的全表扫描。而分区表的话,表示按照字段进行分区,比如按照时间进行分区,1号、2号、3号,那么等于说是按照时间把表分成了三个区域,这三个区域当然还在heroes里面,但是它们不再是具体的数据文件,而也是一个目录(分区目录),然后每个目录里面存储各自对应的分区数据。那么当我想查找对应的数据,就只需要去对应的分区
(比如1号的数据,只需要到1号分区里面去查找)就可以了,就不用全表扫描了。尤其是当数据量很大的时候,指定分区表是非常有必要的,其实我们在生产中建立的表绝大部分都是分区表。比如365天的数据,如果不指定分区,那么girls里面可能会有365个文件,那么当查找的时候会从这365个文件中从头查找,即便我们只想从第200天的数据中查找。但如果是分区表就不一样了,我们可以按照天分区,如果数据量增长速度极快,那么你还可以按照小时分区。按照天分区的话,heroes里面就相当于有365个分区目录,每个目录里面存放了对应的数据,那么当我们想要第200天的数据的时候,只需要到第200天对应的分区里面去找就ok了。
下面我们就来创建一下分区表,并插入数据。
create table info (id int, name string, dt string)
-- 指定字段 day 作为分区, 它可以不出现在创建的表字段当中, 原因后面解释
partitioned by (day string)
row format delimited fields terminated by \',\';
然后我们用Python生成10000条伪数据,伪数据如下,id是自增整数,名字是使用Python的faker模块随机生成的,dt一律都是 2020-03-08。
1,庄秀华,2010-03-08
2,李欣,2010-03-08
3,乔兵,2010-03-08
4,钱建国,2010-03-08
5,王伟,2010-03-08
6,朱玉,2010-03-08
7,许桂香,2010-03-08
8,王柳,2010-03-08
9,刘秀珍,2010-03-08
10,李健,2010-03-08
11,程芳,2010-03-08
12,曹亮,2010-03-08
13,黄博,2010-03-08
14,李玉兰,2010-03-08
15,曹淑英,2010-03-08
16,田颖,2010-03-08
............
然后通过 load data local inpath 导入到 Hive 中。

但是在插入数据的时候报错了,报了个什么错误呢?告诉我们 因为目标表被分区了,我们需要指定分区字段。

补充一下,创建表的时候,分区字段不能出现在定义的表的字段里面。我们通过指定 partition(day=\'2010-03-08\'),表示这是一个day=\'2010-03-08\'的分区。再比如今天是 \'2019-03-09\',那么我想把今天的数据存在一个分区里,就可以指定partition(day=\'2019-03-09\'),表示这个分区存放了 \'2019-03-09\' 的所有数据。

此时我们再使用webUI查看一下,发现里面是一个目录,注意这是目录。如果不是分区表,那么就是文件。我们点进去看看:
我们点进去就能看到我们 load 进来的文件,所以分区分的就是目录。那比如说,我们再创建一个分区。

此时又创建了一个 day=\'2010-06-07\' 的分区,然后查看一下HDFS。

可以看到就又多了一个分区。那么我们就来查询一下数据,两个分区存的数据是一样的,都是10000条。
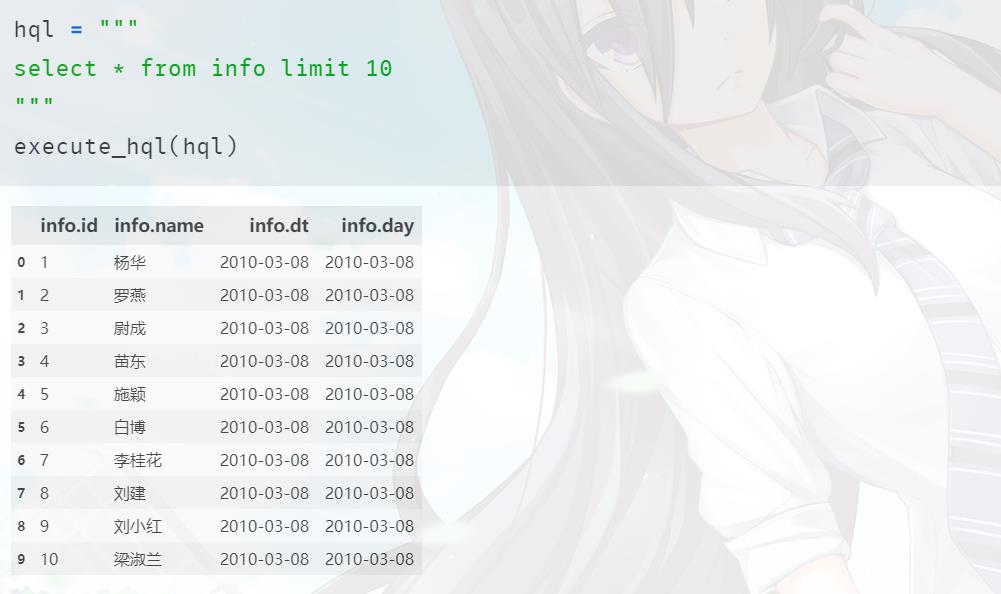
我们原来的数据只有三个字段,但是现在是4个,说明把分区字段 day 也给加上去了。当然由于我们只选了10条,这10条都是分区day=\'2010-03-08\'下面的,因为不指定分区的话,默认是从第一个分区开始选。

如果通过分区作为筛选字段的话就不一样了,此时不会再重头筛选,而是会从指定的分区中筛选。
所以默认情况下是操作所有分区,我们统计一下记录总数,以及查询一下 id = 100 的。

我们看到总共的记录数是20000,说明统计的时候是把所有分区都给算进去的。当然查询其他内容也是一样的,默认是所有分区,我们生成的数据里面的 dt 都是 "2010-03-08",但是有两个分区,数据一样,所以在查找 id = 100 的记录的时候,将两个分区的数据都找出来了。而如果我们想指定分区的话,直接将day(分区字段)当成普通字段来指定即可。
那么Hive是如何做到的呢?我们之前说了元数据都存在MySQL里面,而我们指定的数据库是metastore,我们就进去看看,里面到底存了哪些表?

可以看到里面存了很多表,其中的 TBLS 存储的就是HDFS数据的元信息,而且我用箭头还指向了PARTITIONS这张表。不用想,从名字就能看出来这是与我们现在的分区有关系,我们来看看这张表长什么样子。
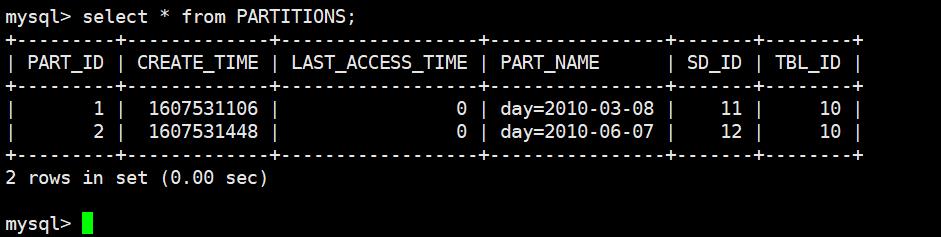
看到了没,分区字段也是数据的元信息,是存储在MySQL里面的,通过分区信息来找到对应的分区。所以我们是先找到分区,然后再到分区里面查找数据,所以说Hive虽然没有索引,但是这个分区是不是也有点索引的感觉呢?不过分区的这个字段它并不是我们在表中真正意义上创建的字段(所以才说指定的分区字段名不能和我们定义的表的字段名之间有重复,也就是不能用表的字段再作为分区的字段),它只是作为元信息。不过你可以认为它是我们普通地定义的表的字段之一、并在查询的时候把所有的字段一视同仁,毕竟在查询的时候分区字段也会跟着一块出来。
分区操作
添加分区:
我们之前是通过 load data local inpath,然后指定分区,从而创建了分区并且把数据导入了对应的分区中,那么可不可以直接创建分区呢?显然是可以的,通过 alter table info add partition(day=\'2018-9-9\') partition(day=\'2018-9-10\') ... 操作,是的,我们可以一次性指定多个分区,当然也可以一次只指定一个。

然后我们查看一下HDFS上的元信息。
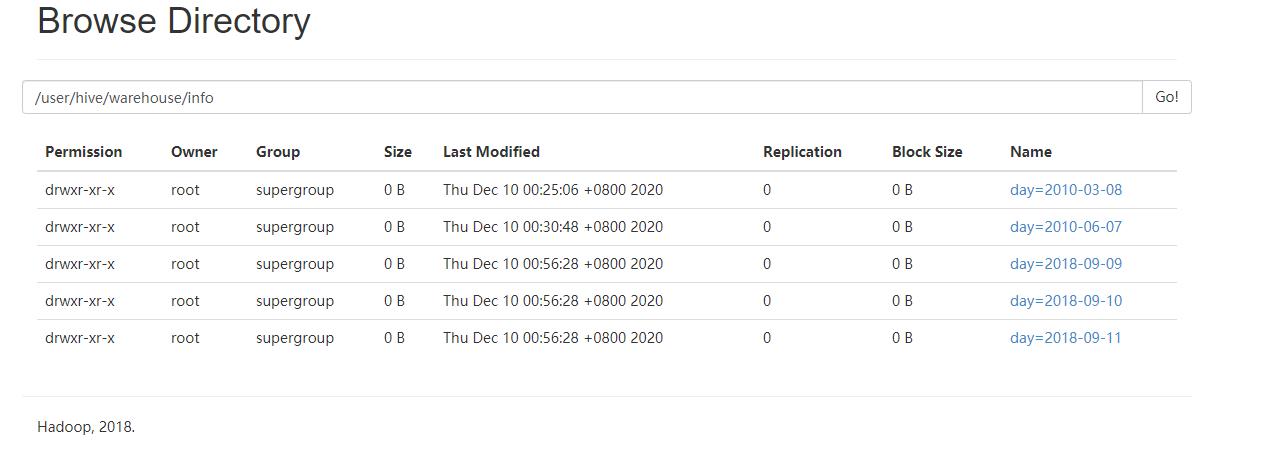
发现多了几个分区,就是我们刚刚创建的,当然里面都没有数据。
我们注意到这个 /user/hive/warehouse/info/day=2018-09-09,里面是没有数据的。我们之前可以通过 load data local inpath 这种方式将数据增加到分区里面。那么通过手动上传文件的方式,将数据上传到HDFS,然后通过SQL能不能访问呢?我们来试一试:

数据是上传成功了的,但是能不能通过sql访问呢?

显然是可以的,所以再次证明了,元数据和实际数据不存在所谓先后顺序。不管是先有元数据、还是先有原始数据,只要两者都存在、并且建立映射关系,那么就能访问到。
删除分区:
alter table info drop partition(day=\'2018-09-09\'),partition(day=\'2018-09-10\'),...,注意:和创建分区不同,除了把add换成了drop之外,多个分区之间是使用逗号分隔的,这个比较恶心,你要使用空格都使用空格,使用逗号都使用逗号。但是创建多个分区,使用空格分隔;删除多个分区,使用逗号分隔,就有点莫名其妙。

再来看看HDFS:

分区已被成功删除。
查看分区:
show partitions table,查看分区表有多少分区。desc formatted table查看分区表结构。

数据的导入与导出
介绍完 数据库 和 表 的创建,我们来看看如果导入和导出数据。
数据的导入
数据导入的话可以使用 insert 语句,但如果我们有一个大文件的话,那么我们需要先把文件内容读取出来,然后再 insert 进去,可不可以直接将文件导入到 Hive 中呢?
显然是可以的,因为我们之前已经用过了,也就是 load data local inpath,下面我们再来介绍一下这个语句。
load data [local] inpath \'数据路径\' [overwrite] into table table_name [partition (partition_col1 = val1, ...)]
load data: 表示加载数据;local: 表示从本地加载, 否则从HDFS上加载;inpath: 表示数据加载的路径;overwrite: 表示覆盖表中已有数据, 否则追加;into table: 表示加载到哪张表中;partition: 表示上传到指定分区, 需要是分区表;
然后就是 insert 语句,这个比较简单了,和关系型数据库是类似的。
insert into 表(col1, col2, ...) values (val1, val2, ...), (val1, val2, ...)
还可以将一张表的记录插入到另一张表中:
insert into 表1 as select * from 表2; -- 表示将表2的记录插入到表1当中,当然还可以筛选字段、指定行数
和普通关系型数据库不一样的是,Hive 除了 insert into 之外,还有一个 insert overwrite,表示将表清空之后再插入,而 insert into 是直接追加。
此外表不存在的时候也可以插入数据,会先创建表。
create table 表1 as select * from 表2; -- 根据从表2选出的字段创建表1, 然后再将数据导入到表1中
-- 表1的字段类型和表2保持一致, 当然这里我们还可以执行更加复杂的查询, 然后根据其结果创建新表
数据的导出
insert 导出
你没有看错,insert 除了可以导入之外,还可以导出。可以将查询的结果导出到本地:
insert overwrite [local] directory "本地目录(不存在则创建)" select * from 表名
如果不加local,则是导出到hdfs上面。当然查询不一定是select * ,还可以是其它复杂查询,这里就用select *代替了。

然后查看一下本地文件,虽然我们指定的是 1.txt,但是很明显它是一个目录,因为一张表对应一个目录,该目录里面才是具体存放的数据文件。当然分区表是个例外,分区表里面还是目录,也就是每一个分区。
我们看到数据都在里面了,但是貌似这些数据都连在一起了,这样的数据貌似也不好用啊。而我们在创建表的时候可以指定分隔符,表示我们通过本地数据导入的时候,本地数据的每一行的每一个字段之间用指定分隔符分隔 以上是关于hadoop--大数据最基础最重要的组件的主要内容,如果未能解决你的问题,请参考以下文章