常用Unicode编码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用Unicode编码相关的知识,希望对你有一定的参考价值。
参考技术A unicode编码范围:
汉字:[0x4e00,0x9fa5](或十进制[19968,40869])
数字:[0x30,0x39](或十进制[48, 57])
小写字母:[0x61,0x7a](或十进制[97, 122])
大写字母:[0x41,0x5a](或十进制[65, 90])
汉字编码范围:\\u4E00-\\u9FA5
双字节字符编码范围:\\u0391-\\uFFE5
双字节字符编码范围
汉字unicode编码表
一般使用2w基本汉字就够了
| 字符集 | 字数 | Unicode 编码 |
| 基本汉字 | 20902字 | 4E00-9FA5 |
| 基本汉字补充 | 38字 | 9FA6-9FCB |
| 扩展A | 6582字 | 3400-4DB5 |
| 扩展B | 42711字 | 20000-2A6D6 |
| 扩展C | 4149字 | 2A700-2B734 |
| 扩展D | 222字 | 2B740-2B81D |
| 康熙部首 | 214字 | 2F00-2FD5 |
| 部首扩展 | 115字 | 2E80-2EF3 |
| 兼容汉字 | 477字 | F900-FAD9 |
| 兼容扩展 | 542字 | 2F800-2FA1D |
| PUA(GBK)部件 | 81字 | E815-E86F |
| 部件扩展 | 452字 | E400-E5E8 |
| PUA增补 | 207字 | E600-E6CF |
| 汉字笔画 | 36字 | 31C0-31E3 |
| 汉字结构 | 12字 | 2FF0-2FFB |
| 汉语注音 | 22字 | 3105-3120 |
| 注音扩展 | 22字 | 31A0-31BA |
| 〇 | 1字 | 3007 |
两万常用汉字的拼音+首字母缩写+unicode编码对照表
最近做项目遇到一项需求,为了隐藏汉字,对医院名称使用首字母代替,对医生名称用拼音代替。
直接下载最终excel成果:
https://download.csdn.net/download/liuxiaoddd/11545306
查阅了众多资料,对各种结果分析汇总并改造,最终总结如下:
1. 读出汉字的拼音首字母可通过Excel 公式实现;
2. 读出汉字的拼音实现方法,基本需要借助编程,但是目前网上流传最广的版本是比较老旧的版本,不仅编码覆盖不全,而且有错误的mapping。
3. 得到2万个常用的汉字并不容易,最终是通过程序按照unicode顺序逐一写出,才得到了汉字全集
4. VBA中十六进制和十进制互相转化的妙用
首先,VBA中,把unicode转为汉字:
Sub Unicode2HZ()
Sheets("Sheet1").Cells(1, 1) = ChrW$(CLng("&H" & "4E00"))
End Sub
其次,VBA中十进制与十六进制互相转化:
Sub m_Unicode2HZ2()
'十六进制转十进制
Sheets("编码对照表").Cells(1, 1) = WorksheetFunction.Hex2Dec("4E00")
Sheets("编码对照表").Cells(2, 1) = WorksheetFunction.Hex2Dec("9FA5")
'十进制转十六进制
Sheets("编码对照表").Cells(3, 1) = "'" & CStr(Hex(Sheets("编码对照表").Cells(1, 1).Value))
Sheets("编码对照表").Cells(4, 1) = "'" & CStr(Hex(Sheets("编码对照表").Cells(2, 1).Value))
End Sub
最后,VBA中通过unicode编码写出所有的汉字:
Sub getAllHanzi()
Dim i As Long
Dim low As Long
Dim high As Long
low = WorksheetFunction.Hex2Dec("4E00") - 1
high = WorksheetFunction.Hex2Dec("9FA5") + 1
i = low + 1
Do While i > low And i < high
Sheets("编码对照表").Cells(i - 19967, 1) = i
Sheets("编码对照表").Cells(i - 19967, 2) = "'" & CStr(Hex(i))
Sheets("编码对照表").Cells(i - 19967, 3) = ChrW$(CLng("&H" & Sheets("编码对照表").Cells(i - 19967, 2).Value))
i = i + 1
Loop
End Sub
最后的几个标签页的结果分别如图:
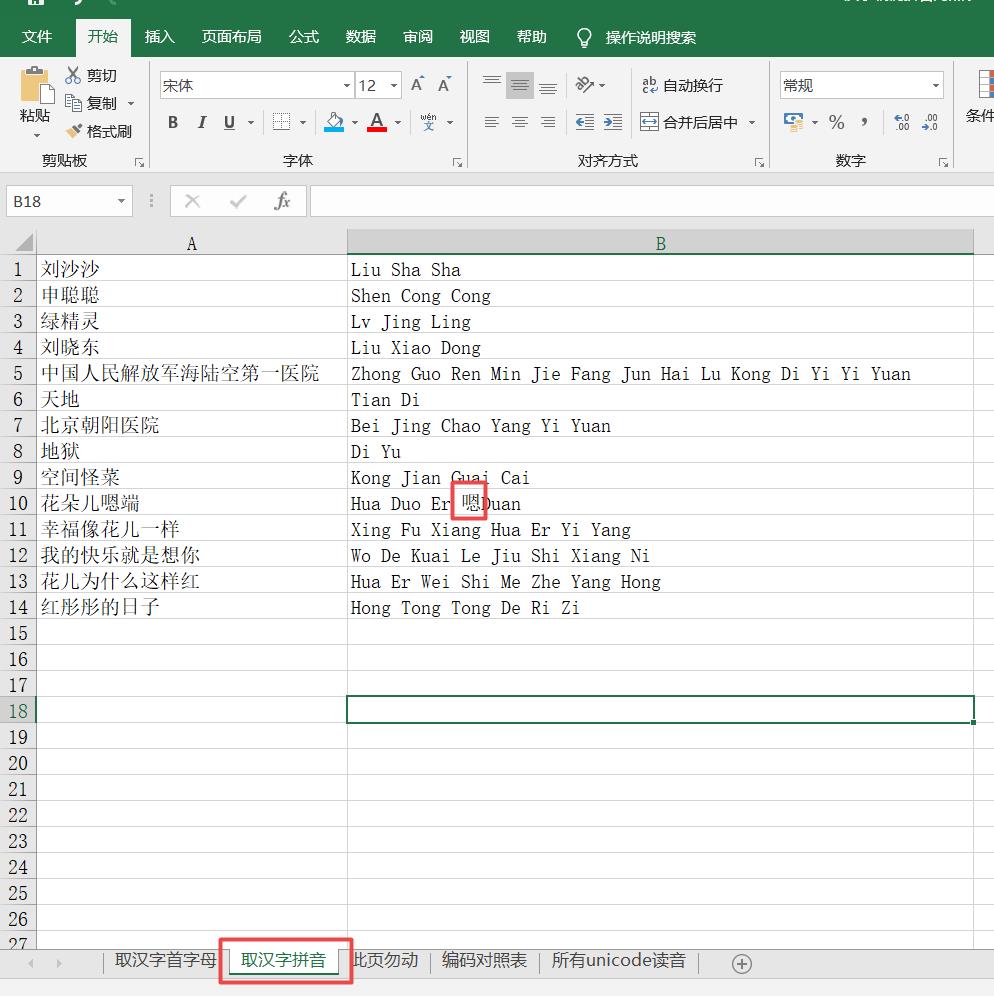
取汉字首字母:根据Excel公式生成
取汉字拼音:根据VBA中的代码生成,不太全
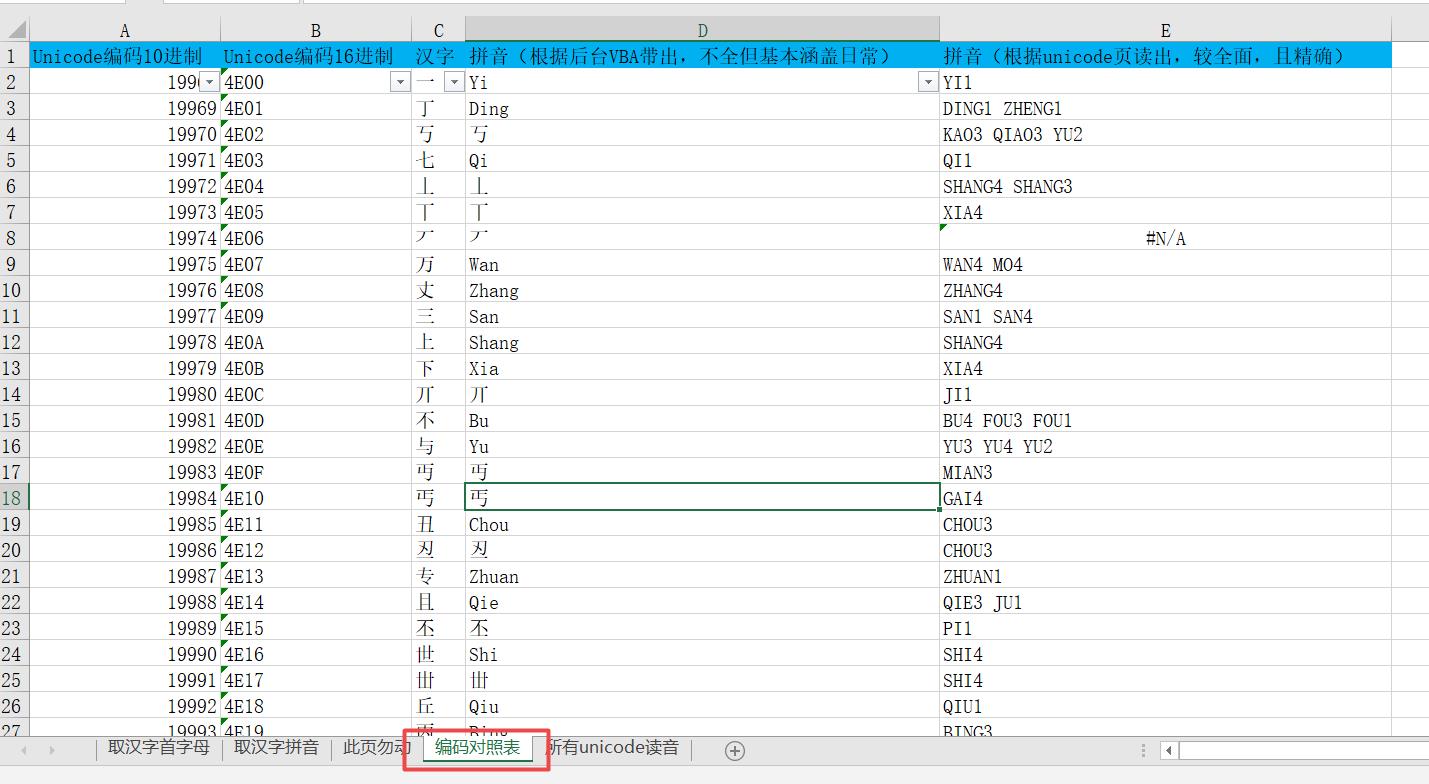
编码对照表:比较全的对照表,但没有用来更新“取汉字拼音”后台逻辑的vba程序,仅作研究,为大家提供便利。
由于含有宏,文件格式为xlsm,需要启用宏各功能才可用。
已经上传到CSDN论坛,名称为“汉字编码拼音对照表.xlsm”
直接下载最终excel成果:
https://download.csdn.net/download/liuxiaoddd/11545306

直接下载成果:
一个unicode和拼音的对照表,dat文件,可以用notepad++打开
https://download.csdn.net/download/baidu_18987603/9695456

unicode 的汉字编码范围:
https://www.qqxiuzi.cn/zh/hanzi-unicode-bianma.php

以上是关于常用Unicode编码的主要内容,如果未能解决你的问题,请参考以下文章