Unicode与编码方式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Unicode与编码方式相关的知识,希望对你有一定的参考价值。
参考技术AUnicode可以表示世界上的每一个字符,每一个字符都有相应并且 唯一 的二进制编码。Unicode是一种字符集,让几乎所有语言中的每个字符都和一个 唯一数字 对应起来。
https://unicode-table.com/cn/4F60/
Unicode 是为了解决传统的字符编码方案的局限而产生的, 它为每种语言中的每个字符设定了统一并且唯一的二进制编码 ,以满足跨语言、跨平台进行文本转换、处理的要求。也就是说世界上的任意一个字符,无论何种语言,都能在Unicode字符集中找到其对应的二进制编码。
Unicode的表现方式是U+XXXXXX,X代表一位十六进制数,可以有4-6位,不足 4 位前补 0 补足 4 位,超过则按是几位就是几位。
字符A的ASCII码是65,将65转换成16进制就是41(16×4+(16^0)×1 = 65),按照规则前面补0,那么字符A的Unicode表示就是U+0041,依次类推B的Unicode表示就是U+0042...等等,汉字"爱"的字符表示是“U+7231”
常见的编码方式有 UTF-8 , UTF-16 , GB2312 , GBK,它们都只是一种编码方式,每种编码有自己的规则。
UTF-8是一种非常通用的 可变长 字符编码方式,范围由1-4个字节不等。
UTF-16通常由2字节或者4字节表示一个字符,U+000~U+FFFF的范围内用2个字节表示。
U+10000~U+10FFFF的范围内用4个字节表示。
GB2312,每个汉字及符号以两个字节来表示,兼容ASCII码,GB 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312也收录了许多其他语音的文字及符号。它所收录的汉字已经覆盖中国大陆99.75%的使用频率,对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来 GBK 及GB 18030汉字字符集的出现。
GBK 向下与 GB 2312 编码兼容,向上支持 ISO 10646.1 国际标准 ,是前者向后者过渡过程中的一个承上启下的产物。GBK编码,是在 GB2312-80 标准基础上的 内码 扩展规范,使用了双 字节 编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容 GB2312-80 标准
在javascript中,所有的string类型都是使用UTF-16编码的,形如 \'\\u00A9\' 或者 \'\\uD87E\\uDC04\' ,详情参考MDN文档 Lexical_grammar 。
所以JS中,将字符转换成Unicode如下:
用通信理论的思路可以理解为:
unicode是信源编码,对字符集数字化。
utf-8是信道编码,为更好的存储和传输。
一个很简单的例子:
一个用GBK编码的文件,我如果以UTF-8来解码的话,打开就会是一片乱码。
再比如:
当然mata也可能会失效,如图
参考
Unicode中UTF-8与UTF-16编码详解
UTF-8与Unicode的区别
GB2312编码表
gb2312中的英文字母占几个字节?
漫画:什么是字符集和编码?ASCII、UTF-8、UTF-16、UTF-32 又是什么?
解决GB2312、GBK、UTF-8转换问题
Unicode和UTF编码转换
刨根究底字符编码之十一——UTF-8编码方式与字节序标记
UTF-8编码方式与字节序标记

一、UTF-8编码方式
1.
接下来将分别介绍Unicode字符集的三种编码方式:UTF-8、UTF-16、UTF-32。这里先介绍应用最为广泛的UTF-8。
为满足基于ASCII、面向字节的字符处理的需要,Unicode标准中定义了UTF-8编码方式。UTF-8应该是目前应用最广泛的一种Unicode编码方式(但不是最早面世的,UTF-16要早于UTF-8面世)。它是一种使用8位码元(即单字节码元)的变宽(即变长或不定长)码元序列的编码方式。
由于UTF-16对于ASCII字符也必须使用两个字节(因为是16位码元)进行编码,存储和处理效率相对低下,并且由于ASCII字符经过UTF-16编码后得到的两个字节,高字节始终是0x00,很多C语言的函数都将此字节视为字符串末尾从而导致无法正确解析文本。
因此,UTF-16一开始推出的时候就遭到很多西方国家的抵制,大大影响了Unicode的推行。于是后来又设计了UTF-8编码方式,才解决了这些问题。
2.
UTF-8的码元由8位单字节组成;在UTF-8中,因为码元较小的缘故,Unicode码点值被映射到一个、两个、三个或四个码元;换言之,UTF-8使用一个至四个8位单字节码元的序列来表示Unicode字符。
UTF-8编码方式对所有ASCII码点值(0x00~0x7F)具有透明性。所谓透明性,具体指的是在U+0000到U+007F范围内(十进制为0~127)的Unicode码点值,被直接转换为UTF-8单一字节码元0x00~0x7F,与ASCII码没有区别。
并且,0x00~0x7F不会出现在UTF-8编码的非ASCII字符的首字节与非首字节的任意一个字节中(非ASCII字符的UTF-8编码为由多个单字节码元所组成的码元序列),这样就保证了与早已应用广泛且已成为工业标准的ASCII码的完全兼容,避免了歧义,同时纠错能力也强。

(笨笨阿林原创文章,转载请注明出处)
3.
UTF-8同其他的多字节码元编码方式相比具有以下优点:
a) UTF-8的编码空间足够大,未来Unicode新标准收录更多字符,UTF-8也能适应,因此不会再出现UTF-16那样的尴尬。
(注:这里所指的编码空间并不是前文所提到的编号空间Code Space,编号空间属于编号字符集CCS里的概念,而编码空间属于字符编码方式CEF里的概念,两者不能等同;这里的编码空间可理解为编码方式的未来可扩展性、高适应性,详见后文《UTF-8究竟是怎么编码的——UTF-8的编码算法介绍》以及《UTF-16究竟是怎么编码的——UTF-16的编码算法介绍》)
b) UTF-8是变长编码(准确地说是变长码元序列,而码元本身是固定长度为8位单字节的,也就是说,UTF-8采用的单字节码元),比如一个字节足以容纳所有的ASCII字符,就用一个字节来存储,不必在高位补0以浪费更多的字节来存储,因此在英语作为国际语言的现实情况下,UTF-8因其ASCII字符的单字节编码这一特性可节省空间。
c) UTF-8完全直接兼容ASCII码,而非不完全间接兼容。
d) UTF-8的码元序列的第一个字节指明了后面所跟的字节的数目(即带有前缀码),这对字节流的前向解析非常有效(详见后文《UTF-8究竟是怎么编码的——UTF-8的编码算法介绍》)。
e) 也因为UTF-8编码带有前缀码,所以容错性好,即使在传输过程中发生局部的字节错误,比如即便丢失、增加、改变了某些字节,也不会导致所有后续字符全部错乱这样传递性、连锁性的错误问题(否则,若存在错误传递性、连锁性的话,一旦中间某些字节出错,则必须丢弃从出错点开始到结尾的所有编码字节,比如GB码、UTF-32码就是如此),因此很容易重新同步,具有很强的鲁棒性(即健壮性)。
f) 由于UTF-8编码没有状态,从UTF-8字节流的任意位置开始可以有效地找到一个字符的起始位置,字符边界很容易界定、检测出来,所以具有很好的“自同步性”。
g) UTF-8已经成为互联网所采用的字符编码方式的事实标准。
h) UTF-8是字节顺序无关的(因为是单字节码元,而非像UTF-16、UTF-32这样的多字节码元),它的字节顺序在所有系统中都是一样的,其码元序列与字节序列相同,因此它实际上并不需要字节顺序标记BOM(Byte-Orde Mark),虽然Windows系统经常“多此一举”地加上BOM。(有关字节序标记BOM的介绍见下文)
字节序问题在进行信息交换时会带来不小的麻烦。如果字节序未协商好,将导致乱码;若协商结果为双方一个采用大端一个采用小端,则必然有一方要进行大小端转换,性能损失不可避免(字节序的大小端问题其实不像看起来那么简单,有时会涉及硬件、操作系统、上层应用软件多个层次,可能会导致多次转换,详见前文中有关字节序Byte-Orde的介绍)。
i) 字节FE(二进制为1111 1110)和FF(二进制为1111 1111)在UTF-8编码中永远不会出现(因为UTF-8编码方式中,每个字节只能以0、110、1110、11110或10开头,详见后文介绍)。因此可以用称之为零宽度不中断空格(ZERO WIDTH NO-BREAK SPACE)的字符(Unicode字符名称为U+FEFF)作为字节顺序标记BOM来标明UTF-16或UTF-32文本的字节序。
(Windows系统中BOM有时也用在UTF-8编码的文本文件的开头,虽然UTF-8编码不存在字节序问题,但Windows却用BOM来表明该文本文件的编码格式为UTF-8,看起来这有点“多此一举”,其具体原因详见后文)
j) UTF-8编码可以通过屏蔽位和移位操作快速读写。
k) 字符串比较时strcmp()和wcscmp()的返回结果相同,因此使排序变得更加容易。
4.
UTF-8编码方式也并非完美无缺,大致上有如下缺点:
a) 无法根据字符数直接判断出UTF-8文本的字节数,因为UTF-8是一种变长编码方式(码元虽然固定为8位单字节,但码元序列是变长的,可能是单个码元共8位,比如ASCII字符;也可能是两个码元共16位、三个码元共24位、四个码元共32位等)。因此,无论是计算字符数,还是执行索引操作,效率都不高。
b) 需要用2个字节编码那些在扩展ASCII(即EASCII)字符集中只需1个字节编码的扩展字符。
c) 以8位单字节码元编码的UTF-8字符会被Email网关过滤,因为Internet上的信息传输最初设计为7位ASCII码字符(ASCII仅用到了1个字节的低7位)的传输。因此产生了UTF-7编码(类似于同样为Email传输而设计的Base64编码或quoted-printable编码,由于Base64编码或quoted-printable编码各有其不足,因此又设计了UTF-7编码)。
d) UTF-8在它的表示中使用值100xxxxx的几率超过50%,而现存的实现如ISO 2022、4873、6429和8859系统,会把它错认为是C1控制码。因此产生了UTF-7.5编码。
(笨笨阿林原创文章,转载请注明出处)
二、字节序标记BOM

1.
在将逻辑形式的码元序列(或可称之为逻辑编码)映射为物理形式的字节序列(或可称之为物理编码)时,因系统平台的差异,存在一个字节序(Byte-Order字节顺序)的问题。Unicode/UCS规范中推荐的标记字节顺序的方法是BOM字节序标记(Byte-Order Mark字节顺序标记)。
字节序标记BOM是Unicode码点值为FEFF(十进制为65279,二进制为1111 1110 1111 1111)的字符的别名。
最初,字符U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序——是高位在前还是低位在前;如果它出现在字节流的中间,则表达为该字符的原义——零宽度不中断空格(ZERO WIDTH NO-BREAK SPACE零宽度无断空白)。该字符名义上是个空格,实际上是零宽度的,即相当于是不可见也不可打印字符(平常使用较多的是ASCII空格字符,是非零宽度的,需要占用一个字符的宽度,为可见不可打印字符)。
从Unicode 3.2开始,U+FEFF只能出现在字节流的开头,且只能用于标识字节序,就如它的别名——字节序标记——所表示的意思一样;除此以外的用法已被舍弃。取而代之的是,使用U+2060来表示零宽度不中断空格。
2.
如果UTF-16编码的字节序列为大端序,则该字节序标记在字节流的开头呈现为0xFE 0xFF;若字节序列为小端序,则该字节序标记在字节流的开头呈现为0xFF 0xFE。如果UTF-32编码的字节序列为大端序,则该字节序标记在字节流的开头呈现为0x00 0x00 0xFE 0xFF;若字节序列为小端序,则该字节序标记在字节流的开头呈现为0xFF 0xFE 0x00 0x00。
UTF-8编码本身没有字节序的问题,但仍然有可能会用到BOM——有时被用来标示某文本是UTF-8编码格式的文本;再强调一遍:在UFT-8编码格式的文本中,如果添加了BOM,则只用它来标示该文本是由UTF-8编码方式编码的,而不用来说明字节序,因为UTF-8编码不存在字节序问题。
3.
许多Windows程序(包含记事本)会添加BOM到UTF-8编码格式的文件中(至于为什么要添加BOM,可参看后续《微软跟联通有仇?》一文)。然而,在类Unix系统中,这种作法则不被建议采用。
因为它会影响到无法识别它的编程语言,如gcc会报告源码文件开头有无法识别的字符;而在PHP中,如果没有激活输出缓冲(output buffering),它会使得页面内容开始被送往浏览器(即header头被提交),这使PHP脚本无法指定header头(HTTP Header)。
对于已在IANA注册的字符编码(这里的字符编码实际为字符编码模式CES)UTF-16BE、UTF-16LE、UTF-32BE和UTF-32LE等来说,不可使用BOM。因为其名称本身已决定了其字节顺序。对于已注册的字符编码(这里的字符编码实际为字符编码方式CEF)UTF-16和UTF-32来说,则必须在文本开头使用BOM。
4.
不同编码的字节序列中所使用的字节序标记BOM本身的字节序列呈现:
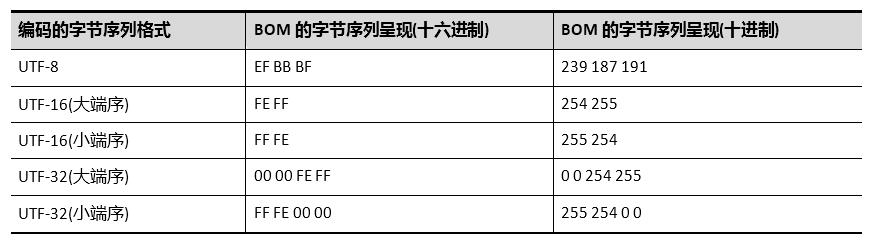
(笨笨阿林原创文章,转载请注明出处)
三、小结
1.
由于UTF-8编码方式以一个字节(8位)作为码元,属于单字节码元,在计算机处理、存储和传输时不存在字节序问题(字节序问题只跟多字节码元有关),因此避免了平台依赖性,跨平台兼容性好。
它相对于其他编码方式对英语更为友好,同样也对计算机语言(如C++、Java、C#、JavaScript、PHP、HTML等)更为友好。它在处理ASCII等常用字符集时很少会比UTF-16低效。
2.
所以,UTF-8是较为平衡、较为理想的Unicode编码方式。虽然Windows平台由于历史的原因API缺乏对UTF-8的原生支持(Windows原生支持的是UTF-16,因为UTF-16早于UTF-8面世),导致UTF-8推出后的早期使用不广,但目前是应用最为广泛的三大UTF编码方式之一。
因此,应该尽量使用UTF-8(准确地说,应该尽量使用UTF-8 without BOM,即不带字节顺序标记BOM的UTF-8)。
(笨笨阿林原创文章,转载请注明出处)
(未完待续)
【预告:本《刨根究底字符编码》系列的下一篇将重点剖析UTF-8究竟是怎么编码的(即UTF-8的编码算法介绍);而《刨根究底正则表达式》系列的下一篇为正则表达式简介(上),包括正则表达式的概念、功能、简史、流派介绍,敬请关注!】
以上是关于Unicode与编码方式的主要内容,如果未能解决你的问题,请参考以下文章