hadoop学习笔记
Posted 星火燎原
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop学习笔记相关的知识,希望对你有一定的参考价值。
一、hadoop1.x的生态系统

HBase:实时分布式数据库
相当于关系型数据库,数据放在文件中,文件就放在HDFS中。因此HBase是基于HDFS的关系型数据库。实时性:延迟非常低,实时性高。
举栗:在近18亿条数据的表中查询1万条数据仅需1.58s,这是普通数据库(Oracle集群,mysql集群)无法办到的。
HDFS:分布式文件系统
MapReduce:分布式计算框架
Zookeeper:分布式协作服务
协作HBase存储、管理、查询数据,Zookeeper是一个很好的分布式协作服务框架。
Hive:数据仓库
数据仓库:
比如给你一块1000平方米的仓库,让你放水果。如果有春夏秋冬四季的水果,让你放在某一个分类中。但是水果又要分为香蕉、苹果等等。然后又要分为好的水果和坏的水果。。。。。
因此数据仓库的概念也是如此,他是一个大的仓库,然后里面有很多格局,每个格局里面又分小格局等等。对于整个系统来说,比如文件系统。文件如何去管理?Hive就是来解决这个问题。
Hive:
分类管理文件和数据,对这些数据可以通过很友好的接口,提供类似于SQL语言的HiveQL查询语言来帮助你进行分析。其实Hive底层是转换成MapReduce的,写的HiveQL进行执行的时候,Hive提供一个引擎将其转换成MapReduce再去执行。
Hive设计目的:方便DBA很快地转到大数据的挖掘和分析中。
Pig:数据流处理
基于MapReduce的,基于流处理的。写了动态语言之后,也是转换成MapReduce进行执行。和Hive类似。
Mahout:数据挖掘库
基于图形化的数据碗蕨。
Sqoop:数据库ETL工具
ELT:提取 --> 转换 --> 加载。
从数据库中获取数据,并进行一系列的数据清理和清洗筛选,将合格的数据转换成一定格式的数据进行存储,将格式化的数据存储到HDFS文件系统上,以供计算框架进行数据分析和挖掘。
格式化数据:
|- TSV 格式:每行数据的每列之间以制表符(tab \\t)进行分割
|- CVS 格式:每行数据的每列之间以逗号进行分割
Sqoop:将关系型数据库中的数据与HDFS(HDFS 文件,HBase中的表,Hive中的表)上的数据进行相互导入导出。
Flume:日志收集工具
将大的集群上面的每台机器的日志收集起来,自动地放到你指定的HDFS文件系统的某个路径中去。
Ambari:安装、部署、配置和管理工具
提供一个图形化工具对集群进行安装、部署、配置及管理,无需手动在命令行操作。
四、hadoop2.x的生态系统

YARN:集群资源管理系统
对整个集群每台机器的资源进行管理,对每个服务、每个job、每个应用进行调度(CPU等)。
HDFS2:分布式文件系统
增强了一些特性,最主要的就是NameNode的单节点故障和NameNode的横向扩展。
Tez:DAG计算框架
Storm:流式计算框架
五、hadoop1.x组成
对于分布式系统和框架的架构来说,一般分为两部分:
第一部分:管理层,用于管理应用层的。
第二部分:应用层(工作)。
HDFS核心后台守护进程:
NameNode:元数据服务器
NameNode是主节点,存储文件的元数据如文件名、文件目录结构、文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在DataNode等。
属于管理层,用于管理数据的存储。
Secondary NameNode:辅助元数据服务器
用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
属于管理层,辅助NameNode进行管理。
DataNode:块存储
在本地文件系统存储文件块数据,以及块数据的校验和。
属于应用层,用于进行数据的存储,被NameNode进行管理。要定时向NameNode进行工作汇报,执行NameNode分配分发的任务。
MapReduce,分布式进行计算框架:
JobTracker:任务调度员
负责接收用户提交的作业,负责启动、跟踪任务执行。
属于管理层,管理集群资源和对任务进行资源调度,监控任务的执行。
TaskTrackers:任务执行
负责执行由JobTracker分配的任务,管理各个任务在每个节点上的执行情况。
属于应用层,执行JobTracker分配分发的任务,并向JobTracker汇报工作情况。
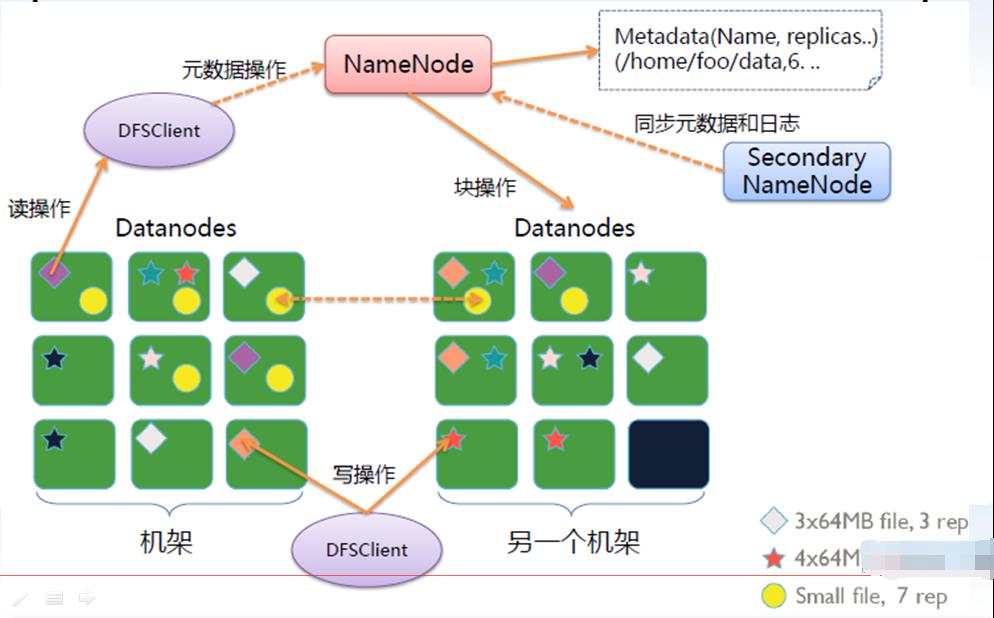
六、HDFS架构图
七、MapReduce架构图

以上是关于hadoop学习笔记的主要内容,如果未能解决你的问题,请参考以下文章